MongoDB简介
10gen于2007年由DoubleClick的创始人兼CTO Dwight Merriman与工程师Eliot Horowitz联合创办,采用的是一种开源模式,主要通过为客户提供支持、培训以及相关咨询服务获得收益。MongoDB是10gen的主要产品,2007年推出后,作为基于文档的数据库被业界广泛认可,后10gen公司更名为MondoDB公司,主页由10gen.com变为mongodb.com.
MongoDB是一个开源的,基于分布式的,面向文档存储的非关系型数据库,是非关系型数据库当中比较像关系型数据库的.MongoDB由C++编写,起名字来源于”humongous”这个单词,宗旨在于处理大量数据.
MongoDB的特点:
面向集合存储,易存储对象类型的数据。
模式自由。集合中没有行和列的概念,每个文档可以有不同的key,key的值不要求一致的数据类型.
支持动态查询。支持丰富的查询的表达式,查询指令可以使用JSON形式表达式.
支持索引。
支持查询。
支持复制和故障恢复。
使用高效的二进制数据存储,包括大型对象(如视频等)。
自动处理碎片,以支持云计算层次的扩展性
支持C/C++,PHP,RUBY,PYTHON,JAVA,等多种语言。
文件存储格式为BSON(一种JSON的扩展,JSON的二进制)
数据库排行榜:
DB-Engines:2016年3月数据库排名
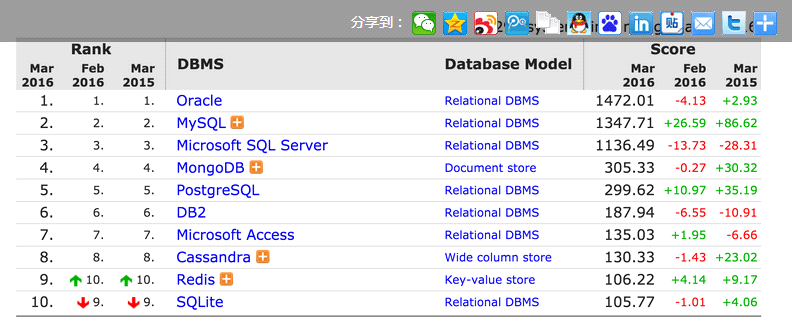
MongoDB应用场景:
京东,中国著名电商,使用MongoDB存储商品信息,支持比价和关注功能.
赶集网,中国著名分类信息网站,使用MongoDB记录pv浏览计数
奇虎360,著名病毒软件防护和移动应用平台,使用MongoDB支撑的HULK平台每天接受200亿次的查询.
百度云,使用MongoDB管理百度云盘中500亿条关于文件源信息的记录.
CERN,著名的粒子物理研究所,欧洲核子研究中心大型强子对撞机的数据使用MongoDB
纽约时报,领先的在线新闻门户网站之一,使用MongoDB
sourceforge.net,资源网站查找,创建和发布开源软件免费,使用MongoDB的后端存储
MongoDB的安装
MongoDB的使用
mongodb和sql对应关系
SQL术语/概念
MongoDB术语/概念
解释/说明
database
database
数据库
table
collection
数据库表/集合
row
document
数据记录行/文档
column
field
数据字段/域
index
index
索引
table joins
嵌入文档
表连接,MongoDB不支持,可通过内嵌和包含关联ID实现
primary key
primary key
主键,MongoDB自动将_id字段设置为主键
文档
文档是一个键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
如:
{"site":"www.itcast.com", "name":"传智播客"}
注意事项:
文档中的键/值对是有序的。
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
MongoDB区分类型和大小写。
MongoDB的文档不能有重复的键。
文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键不能含有� (空字符)。这个字符用来表示键的结尾。
文档命名.和$有特别的意义,只有在特定环境下才能使用。
文档命名以下划线"_"开头的键是保留的(不是严格要求的)。
集合
文档组,类似于关系数据库中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"} {"site":"www.google.com","name":"Google"} {"site":"www.itcast.cn","name":"传智教程","num":5}
当第一个文档插入时,集合就会被创建。
分布式数据库系统
由分布于多个计算机结点上的若干个数据库系统组成,它提供有效的存取手段来操纵这些结点上的子数据库。分布式数据库在使用上可视为一个完整的数据库,而实际上它是分布在地理分散的各个结点上。当然,分布在各个结点上的子数据库在逻辑上是相关的。
mongo常用数据类型
数据类型
描述
String
字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
Integer
整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
Boolean
布尔值。用于存储布尔值(真/假)。
Double
双精度浮点值。用于存储浮点值。
Arrays
用于将数组或列表或多个值存储为一个键。
Timestamp
时间戳。记录文档修改或添加的具体时间。
Object
用于内嵌文档。
Null
用于创建空值。
Symbol
符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
Date
日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
Object ID
对象 ID。用于创建文档的 ID。
Binary Data
二进制数据。用于存储二进制数据。
Code
代码类型。用于在文档中存储 JavaScript 代码。
Regular expression
正则表达式类型。用于存储正则表达式。
创建删除数据库
创建/切换:
use DATABASE_NAME
显示所有数据库名:
show dbs
查看当前数据库的名称:
db
查看所有的collection:
show collections
删除当前的数据库
db.dropDatabase()
MongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
mongodb 增加文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档:
db.COLLECTION_NAME.insert(document)
例如:
db.test.insert({title: 'mongo test',
description: 'MongoDB是Nosql数据库',
url: 'http://mongodb.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 200
})
区别:
1.save函数实际就是根据参数条件,调用了insert或update函数.如果想插入的数据对象存在, insert函数会报错, 而save函数是改变原来的对象;如果想插入的对象不存在,那么它们执行相同的插入操作. 这里可以用几个字来概括它们两的区别,即所谓"有则改之,无则加之".
2.insert可以一次性插入一个列表,而不用遍历,效率高, save则需要遍历列表,一个个插入.
3.如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
mongodb 查询文档
查询格式如下:
db.COLLECTION_NAME.find({COND},{FIELDS})
find() 方法以非结构化的方式来显示所有文档。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.test.find().pretty()
{
"_id" : ObjectId("56ece7acf5fec0105618da63"),
"title" : "22mongo test",
"description" : "MongoDB是Nosql数据库",
"url" : "http://www.baidu.com",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 200
}
一次返回1个结果:
db.test.findone()
MongoDB 与 RDBMS Where 语句比较
操作
格式
范例
RDBMS中的类似语句
等于
{<key>:<value>}
db.test.find({"title":"mongo"}).pretty()
where title = 'mongo'
小于
{<key>:{$lt:<value>}}
db.test.find({"likes":{$lt:50}}).pretty()
where likes < 50
小于或等于
{<key>:{$lte:<value>}}
db.test.find({"likes":{$lte:50}}).pretty()
where likes <= 50
大于
{<key>:{$gt:<value>}}
db.test.find({"likes":{$gt:50}}).pretty()
where likes > 50
大于或等于
{<key>:{$gte:<value>}}
db.test.find({"likes":{$gte:50}}).pretty()
where likes >= 50
不等于
{<key>:{$ne:<value>}}
db.test.find({"likes":{$ne:50}}).pretty()
where likes != 50
mongodb 删除文档
执行remove()函数前先执行find()命令来判断执行的条件是否正确
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档.默认是true
writeConcern :(可选)抛出异常的级别。
例如:
db.test.remove({"_id" : ObjectId("56ece690f5fec0105618da62")})
mongodb 修改文档
更新数据格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如$,$set...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew, true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true, 就把按条件查出来多条记录全部更新。
*writeConcern :可选,抛出异常的级别。
实例:
我们在集合test中插入如下数据:
>db.col.insert({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
url: 'http://www.baidu.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
接着我们通过 update() 方法来更新标题(title):
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息
可以看到标题(title)由原来的 "MongoDB 教程" 更新为了 "MongoDB"。以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
*WriteConcern的几种抛出异常的级别参数:
WriteConcern.NONE:没有异常抛出
WriteConcern.NORMAL:仅抛出网络错误异常,没有服务器错误异常(默认)
WriteConcern.SAFE:抛出网络错误异常、服务器错误异常;并等待服务器完成写操作。(特殊情况可以使用该级别 )
WriteConcern.MAJORITY: 抛出网络错误异常、服务器错误异常;并等待一个主服务器完成写操作。
WriteConcern.FSYNC_SAFE: 抛出网络错误异常、服务器错误异常;写操作等待服务器将数据刷新到磁盘。
WriteConcern.JOURNAL_SAFE:抛出网络错误异常、服务器错误异常;写操作等待服务器提交到磁盘的日志文件。
WriteConcern.REPLICAS_SAFE:抛出网络错误异常、服务器错误异常;等待至少2台服务器完成写操作。
mongodb索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
语法:
db.COLLECTION_NAME.ensureIndex({KEY:1})
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
mongodb聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等) ,并返回计算后的数据结果。有点类似sql语句中的 count(*)。
MongoDB中聚合的方法使用aggregate()。
语法:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
实例:
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'w3cschool.cc',
url: 'http://www.w3cschool.cc',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'w3cschool.cc',
url: 'http://www.w3cschool.cc',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
现在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "w3cschool.cc",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
以上实例类似sql语句: select by_user, count(*) from mycol group by by_user
在上面的例子中,我们通过字段by_user字段对数据进行分组,并计算by_user字段相同值的总和。
mongodb副本集
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。复制还允许您从硬件故障和服务中断中恢复数据。
为什么要进行复制?
保障数据的安全性
数据高可用性 (24*7)
灾难恢复
无需停机维护(如备份,重建索引,压缩)
分布式读取数据
如何实现复制?
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB关于C++的API简介
主要API介绍,对应头文件为dbclientinterface.h
说明:
IN表示输入参数;
OUT表示输出参数;
1.构造函数
DBClientConnection(bool auto_connect, 0, double so_timeout);
auto_connect(IN):连接失败后自动重连
so_timeout(IN):非连接超时,tcp的读写超时
2.连接函数
bool connect(string server, &string errmsg);
返回值:成功/失败
server(IN):连接的服务器
errmsg(OUT):出错信息
示例:
bool auto_connect = true;
double so_timeout = 3;
string host = "127.0.0.1";
string port = "27017";
string errmsg = "";
DBClientConnection pConn = new DBClientConnection(auto_connect, 0, so_timeout);
pConn->connect(host+":"+port, errmsg);
3.查询
auto_ptr query(const string &ns, Query query, int nToReturn, int nToSkip,
const BSONObj *fieldsToReturn, int queryOptions , int batchSize);
返回值:结果集
ns(IN):命名空间,db_name.collection_name
query(IN):查询的条件,相当于mysql中的where
nToReturn:返回结果条数,相当于limit
nToSkip:跳过的结果条数,相当于skip
fieldsToReturn:返回列集合
queryOptions:详见QueryOptions这个枚举,填0即可
batchSize:未说明
示例:
string db = "shool";
string collection = "student";
Query condition = QUERY("age"<<20);
int limit = 10;
int offset = 5;
BSONObj columns = BSON("uid"<<1<<"name"<<1);
auto_ptr cursor;
cursor = pConn->query(db+"."+collection, condition, limit, offset, columns, 0, 0);
其效果相当于:
select uid,name from shool.student where age=20 limit 5,10;
对结果集的操作:
int uid=0;
string name="";
while(cursor->more())
{
BSONObj p = cursor->next();
uid = p["uid"].Int();
name = p["name"].String();
count << uid << " " << name << endl;
}
4.插入
void insert(const string &ns, BSONObj obj, int flags);
ns(IN):命名空间,db_name.collection_name
obj(IN):插入的列
flags(IN):详见API文档,默认填零即可
示例:
BSONObj insert = BSON("uid"<<10001<<"name"<<"skean1017");
pConn->insert(db+"."+collection, insert, 0);
其效果相当于:
insert into shool.student (uid, name) values (10001, “skean1017″);
5.删除
void remove(const string &ns, Query query, bool justOne);
ns(IN):命名空间,db_name.collection_name
query(IN):查询条件
justOne(IN):是否只删除匹配的第一条
示例:
Query query = QUERY("name"<<"skean1017");
pConn->remove(db+"."+collection, query, true);
其效果相当于:
delete from shool.student where name=”skean1017″;
6.修改
void update(const string &ns , Query query , BSONObj obj , bool upser , bool multi);
ns(IN):命名空间,db_name.collection_name
query(IN):查询条件
obj(IN):修改后的值
upser(IN):是否upser,如果不存在则插入记录
multi(IN):是否为符合文档
示例:
Query query = QUERY("uid"<<10001);
BSONObj obj = BSON("$set"<update(db+"."+collection, query, obj, false, false);
其效果相当于:
update shool.student set name=”habadog1203” where uid=10001;
mongodb的api的异常处理
mongodb为我们提供了DBException异常类,如果有错误会进行抛出,我们可以通过try catch的方式捕捉该类错误,然后通过打印 what()显示错误详细信息.具体所在头文件: assert_util.h.除了捕获mongo提供的异常信息,还需要捕获标准库的错误信息,最后有一个兜底的所有异常捕捉.
使用方法:
catch( mongo::DBException& e ) {
printf("MONGO Exception(set): %s
", e.what());
return -1;
}
catch (std::exception& e) {
printf("MONGO Exception(set): %s
", e.what());
return -1;
}
catch (...){
printf(“MONGO Exception
”);
return -1;
}