1、事务
?> 什么是事务
事务就是将一组SQL语句放在同一批次内去执行
如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行
MySQL事务处理只支持InnoDB和BDB数据表类型
?>事务的ACID原则 百度 ACID https://blog.csdn.net/dengjili/article/details/82468576
原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)事务前后数据的完整性必须保持一致。
隔离性(Isolation)事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
2、事务的隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read uncommitted) | √ | √ | √ |
| 读已提交(Read committed) | × | √ | √ |
| 可重复读(Repeatable read) | × | × | √ |
| 可串行化(Serializable) | × | × | × |
脏读:
指一个事务读取了另外一个事务未提交的数据。
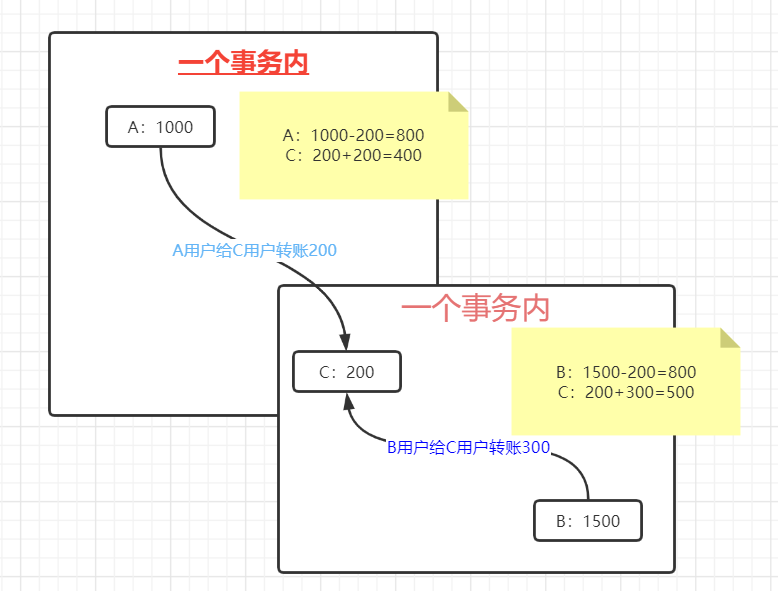
不可重复读:
在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)

虚读(幻读):
是指在一个事务内读取到了别的事务插入的数据,导致前后读取数量总量不一致。 (一般是行影响,如下图所示:多了一行)

3、索引
?>MySQL 官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。 提取句子主干,就可以得到索引的本质:索引就是数据结构。
索引的作用
-
提高查询速度
-
确保数据的唯一性
-
可以加速表和表之间的连接 , 实现表与表之间的参照完整性
-
使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
-
全文检索字段进行搜索优化.
3.1 索引分类
主键索引 (Primary Key)
唯一索引 (Unique)
常规索引 (Index)
全文索引 (FullText)
3.2 主键索引
主键 : 某一个属性组能唯一标识一条记录
特点 :
最常见的索引类型
确保数据记录的唯一性
确定特定数据记录在数据库中的位置
3.3 唯一索引
作用 : 避免同一个表中某数据列中的值重复
与主键索引的区别
-
主键索引只能有一个
-
唯一索引可能有多个
CREATE TABLE `Grade`( `GradeID` INT(11) AUTO_INCREMENT PRIMARYKEY, `GradeName` VARCHAR(32) NOT NULL UNIQUE -- 或 UNIQUE KEY `GradeID` (`GradeID`) )
3.4 常规索引
作用 : 快速定位特定数据
注意 :
index 和 key 关键字都可以设置常规索引
应加在查询找条件的字段
不宜添加太多常规索引,影响数据的插入,删除和修改操作
CREATE TABLE `result`( -- 省略一些代码 INDEX/KEY `ind` (`studentNo`,`subjectNo`) -- 创建表时添加 )
3.5 全文索引
百度搜索:全文索引
作用 : 快速定位特定数据
注意 :
只能用于MyISAM类型的数据表
只能用于CHAR , VARCHAR , TEXT数据列类型
适合大型数据集
/* #方法一:创建表时 CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) ); #方法二:CREATE在已存在的表上创建索引 CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ; #方法三:ALTER TABLE在已存在的表上创建索引 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ; #删除索引:DROP INDEX 索引名 ON 表名字; #删除主键索引: ALTER TABLE 表名 DROP PRIMARY KEY; #显示索引信息: SHOW INDEX FROM student; */ /*增加全文索引*/ ALTER TABLE `school`.`student` ADD FULLTEXT INDEX `studentname` (`StudentName`); /*EXPLAIN : 分析SQL语句执行性能*/ EXPLAIN SELECT * FROM student WHERE studentno='1000'; /*使用全文索引*/ -- 全文搜索通过 MATCH() 函数完成。 -- 搜索字符串作为 against() 的参数被给定。搜索以忽略字母大小写的方式执行。对于表中的每个记录行,MATCH() 返回一个相关性值。即,在搜索字符串与记录行在 MATCH() 列表中指定的列的文本之间的相似性尺度。 EXPLAIN SELECT *FROM student WHERE MATCH(studentname) AGAINST('love'); /* 开始之前,先说一下全文索引的版本、存储引擎、数据类型的支持情况 MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引; MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引; 只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。 测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。 */
3.6 拓展:测试索引
建表app_user:
CREATE TABLE `app_user` ( `id` BIGINT (20) UNSIGNED NOT NULL AUTO_INCREMENT, `name` VARCHAR (50) DEFAULT '' COMMENT '用户昵称', `email` VARCHAR (50) NOT NULL COMMENT '用户邮箱', `phone` VARCHAR (20) DEFAULT '' COMMENT '手机号', `gender` TINYINT (4) UNSIGNED DEFAULT '0' COMMENT '性别(0:男;1:女)', `password` VARCHAR (100) NOT NULL COMMENT '密码', `age` TINYINT (4) DEFAULT '0' COMMENT '年龄', `create_time` datetime DEFAULT CURRENT_TIMESTAMP, `update_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COMMENT = 'app用户表'
批量插入数据:100w
DROP FUNCTION IF EXISTS mock_data; DELIMITER $$ CREATE FUNCTION mock_data() RETURNS INT BEGIN DECLARE num INT DEFAULT 1000000; DECLARE i INT DEFAULT 0; WHILE i < num DO INSERT INTO app_user(`name`, `email`, `phone`, `gender`, `password`, `age`) VALUES(CONCAT('用户', i), '24736743@qq.com', CONCAT('18', FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(), FLOOR(RAND()*100)); SET i = i + 1; END WHILE; RETURN i; END; SELECT mock_data();
3.7 索引效率测试
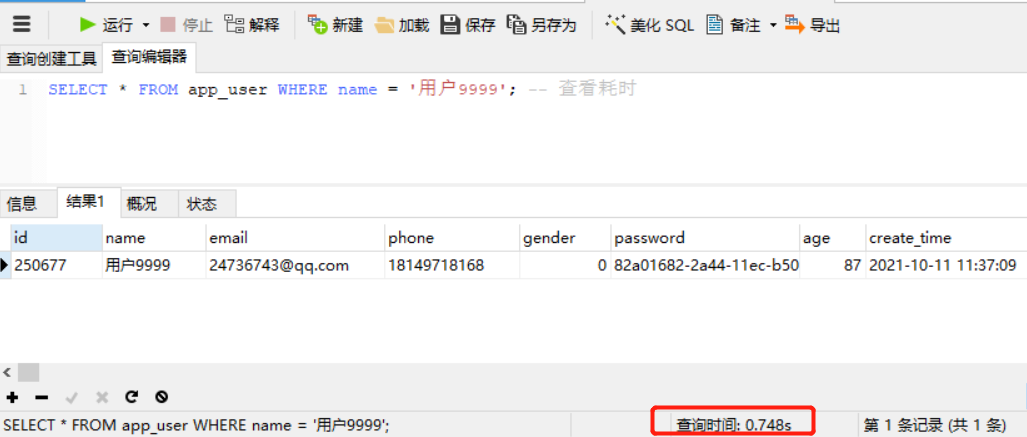
?> 无索引
SELECT * FROM app_user WHERE name = '用户9999'; -- 查看耗时
执行计划
EXPLAIN SELECT * FROM app_user WHERE name = '用户9999'

id:选择标识符 select_type:表示查询的类型。 table:输出结果集的表 partitions:匹配的分区 type:表示表的连接类型 possible_keys:表示查询时,可能使用的索引 key:表示实际使用的索引 key_len:索引字段的长度 ref:列与索引的比较 rows:扫描出的行数(估算的行数) filtered:按表条件过滤的行百分比 Extra:执行情况的描述和说明
?> 测试普通索引
-- 创建索引 CREATE INDEX idx_app_user_name ON app_user(name); EXPLAIN SELECT * FROM app_user WHERE name = '用户9999'

3.8 索引准则
-
索引不是越多越好
-
不要对经常变动的数据加索引
-
小数据量的表建议不要加索引
-
索引一般应加在查找条件的字段
3.9 索引的数据结构
?> mysql索引背后的数据结构:参考blog:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
-- 我们可以在创建上述索引的时候,为其指定索引类型,分两类 hash类型的索引:查询单条快,范围查询慢 btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它) -- 不同的存储引擎支持的索引类型也不一样 InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引; NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引; Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;