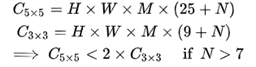论文题目:MnasNet: Platform-Aware Neural Architecture Search for Mobile
文献地址:https://arxiv.org/pdf/1807.11626.pdf
源码地址:https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet

设计移动端使用的卷积神经网络结构的挑战在于移动端不仅要求模型具有小而速度快的特性,还需要保持精度。尽管在设计和改进移动设备方面付出了巨大努力,但是当有这么多架构上的可能性需要考虑时,手动平衡这些特性是极其困难的。这篇文章中提出了一种自动移动神经网络搜索(automa -ted mobile neural architecture, MNAS)方法:该方法明确的将模型运算延迟时间(latency)作为主要的优化目标之一,以此搜索可以平衡运算延迟时间(latency)和精度(accuracy)的网络模型结构。而在之前的工作中,运算延迟时间(latency)是通过一个通常不准确的方式间接衡量,例如FLOPs (float --ing point operations per second:每秒浮点运算时间)。这种方法可以在移动设备上执行模型来直接测量真实世界的推断延迟。另外,提出了一种分层分解搜索空间(hierarchical search space)方法来确定网络结构。
作者的灵感来自于其看到了MobileNet和NASNet中,虽然具有相似的FLOPs(575M vs 564M),但延迟时间却相差较大(113ms vs 183ms)。其次,作者观察到以前的自动化方法主要搜索几种类型的单元,然后通过网络重复地堆叠相同的单元。这种简易的搜索机制会限制层的多样性。第一个灵感诞生了将运算延迟时间与精度进行多目标优化的想法;第二个灵感诞生了分层分解搜索空间的方法。允许层在架构上有所不同,但仍然在灵活性和搜索空间大小之间取得适当的平衡。
MnasNet实验效果
1. ImageNet分类上的表现
表1展示了模型在ImageNet数据集上的效果,作者设置目标延迟时间T=75ms,使用α=β=-0.07作为目标函数中的常量。作者从结果中挑选出三个最好的模型:

2. Model Scaling Performance
改变深度因子Depth multiplier或者分辨率input size对模型的影响:

3. 在COCO目标检测上的表现

移动端卷积神经网络现状
卷积神经网络已经在图像分类、目标检测等方面的应用取得了很大的进步。由于CNN网络结构变得越来越深(ResNet)、越来越大(GoogLeNet), 不可避免的会 出现计算速度慢,需要更多计算资源的问题。这一问题使得很难将先进的CNN模型移植到资源限制的平台,如移动设备或者嵌入式设备中。
由于移动设备上可用的计算资源有限,因此最近的许多研究都集中于设计和改进移动CNN模型,通过降低网络的深度,并且使用资源消耗不大的操作,如深度卷积(depthwise convolution)和组卷积(group convolution)。然而,设计一个资源限制的移动端模型会面临如下挑战:必须小心地平衡准确性和资源利用率,从而有一个较大的设计空间。
论文贡献
1. 将移动端神经网络结构设计的问题转化为一个多目标优化的问题(accuracy和latency),采用强化学习网络搜索的方式,优化移动设备上的运算延迟时间同时保持精度。
2. 提出了一种分级搜索空间方法,通过在灵活性和搜索空间大小之间取得适当的平衡,最大化利用移动网络所在设备上的资源效率。
问题描述
既然作者想到将移动端神经网络结构设计的问题转化为一个多目标优化的问题,目标函数的建立自然是不可避免的。
作者想要直接将模型作用于移动设备端,通过在移动设备端产生的实际推理延迟融入到目标函数的建立中,这种与现实(real-world)交互产生收益的模式正好适合使用强化学习的思想解决。
给定一个模型m,ACC(m)表示模型在目标任务上的精度;LAT(m)表示模型在目标移动设备上推理过程的延迟时间;T表示一个硬性的约束,即延迟时间要小于T。一个最大化准确率的目标函数建立如下:
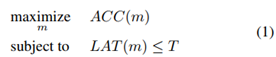
但是,这种方法只最大化了一个度量,并没有提供多个Pareto最优解(毕竟单目标优化嘛,怎么可能出来Pareto解)。对多目标优化不熟悉的小伙伴可以这样理解Pareto解:单目标优化就是要让精度最大即可,而不考虑运算延迟的大小,满足约束即可;而多目标优化需要同时考虑精度和运算延迟,最优解的含义就是它具有最高的精度,而不增加延迟,或者它具有最低的延迟,而不减少准确性。
考虑到执行架构搜索的计算成本,在单个架构搜索中找到多个pareto最优解决方案的策略更划算。也就是说,执行一次优化计算得到多个最优解要比只得到一个最优解要好。因此,多目标函数如下所示:
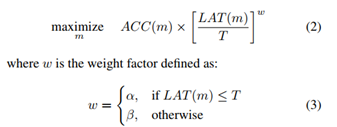
从公式中可以看出,作者巧妙的将运算延迟时间LAT(m)除以约束T形成权重,构建了目标函数,α和β是固定的权重因子。确保帕累托最优解在不同的ACC-LAT权衡下有相似的回报。论文中除特殊声明,α=β=-0.07。
在下图3中,横坐标表示延迟时间LAT(m),纵坐标表示目标函数。下图上半部分表示(α,β)取值为(0,-1)时,当延迟时间小于目标延迟T时,目标函数不随延迟时间的变化而变化(水平直线),只是精度的函数;下图下半部分表示(α,β)取值为(-0.07, -0.07)时,将目标延迟T作为软约束,当延迟时间小于目标延迟T时,不同的延迟时间LAT对于目标函数的影响均会有不同的量化(平滑)。

神经网络结构在移动端搜索算法
1. 分层分解搜索空间(Factorized Hierarchical Search Space)
一个定义良好的搜索空间是极其重要的。之前的方法只搜索几个复杂的单元格,然后重复堆叠相同的单元格。这些方法不会允许层的多样性。而层的多样性对于实现高精度和低延迟非常重要。
思想:将CNN模型分解为独立的块,然后为每一个块分别搜索运算和连接,这样将会允许不同的块使用不同的层结构。直觉上,需要根据输入和输出形状寻找最佳操作,以获得更好的精度权衡。例如,在CNN模型结构的早期阶段(靠近输入的层中),通常会处理大量的数据,这些层关于延迟的影响要比远离输入的层大得多。
对于广泛使用的深度卷积可以将卷积核描述为一个四元组(K, K, M, N),输入尺寸为(H, W, M),输出尺寸为(H, W, N),(H, W)表示输入feature 的分辨率,M, N表示输入、输出的通道数量。运算量可以描述为:

从上式中可以看出,H,W,M是不可控制的,或者说是由上一层的K和N控制的。也就是说,在计算资源受限的情况下,需要平衡卷积核的大小K和输出feature map的通道数量N。例如,在同一层,使用较大的卷积核K来增大感受野的同时,需要适当的减小卷积核的个数N(输出通道数量);或者在其它层计算。
由下图所示,将一个CNN模型分割成一系列预先定义的块,逐渐降低输入分辨率,增加过滤器大小,这在许多CNN模型中很常见。每个块都有一组相同的层,它们的操作和连接由每个块的子搜索空间决定。
上述描述的搜索机制可以这样理解:将CNNs模型分解成为若干个块,然后对每个块中包含的内容进行搜索优化。每个块中可以包含的属性以及相应的选择有:
1. 卷积操作的选择(ConvOp):常规卷积操作(conv);深度卷积操作(depthwise conv);倒置瓶颈卷积操作(MobileNet V2中提到的inverted bottleneck conv)。
2. 卷积核的大小(kernel size):3×3;5×5。
3. Squeeze-and-excitation ratio (SE ratio): 0; 0.25
4. 跳跃操作(skip ops):pooling; residual; no skip;
5. 输出卷积核通道数量:Fi
6. 块Block的数量:Ni (i是重复的次数)
通过一个生活中的例子解释加深对于上述优化的理解:对于高速列车开行方案的优化,如果将Block的数量理解为开行列车的数量,属性Ni理解为每列列车的开行频率,那么每个Block中的属性对应的就是高速列车的编组数量(可以离散化为0:8编组,1:16编组)、各站点是否停靠(0:某站点不停靠,1:某站点停靠)、以及停靠的到站离站时间等。 这个例子的用意在于说明上述CNNs模型搜索方案的可行性。
ConvOp、KernelSize、SERatio、SkipOp、Fi决定了一个层的架构,而Ni决定了这个层将为块重复多少次。例如,下图中block 4的每一层都有一个反向的瓶颈5x5卷积和一个单位剩余跳跃路径,并且同一层重复N4次。Block中的属性也将会采用离散化的方式处理:使用MobileNetV2作为参考网络,将所有的搜索选择离散化:对于块内的每个层,基于MobileNetV2搜索{0,+1,−1} ;对于每个层的filter size,搜索MobileNetV2的相关尺寸的{0.75,1.0,1.25}。
Block的数量B确定后,该优化问题的搜索空间大小也就确定了,搜索空间的大小可以计算得知(详见原文)。

2. 搜索算法(reinforcement-learning based Search Algorithm )
在模型的网络结构通过上述方式确定之后,便可以通过强化学习的方式对建立的多目标优化问题进行求解。作者没有选择优化算法,而是选用强化学习的方式求解多目标优化问题,是因为强化学习的方式很方便,奖励reward机制也很容易定制。当然,优化算法也是可以实现的。
强化学习中,最重要的就是确定奖励机制,如下式所示:

其中,m表示由一系列action a1:T决定的采样模型,R(m)是建立的多目标优化模型中的目标函数值。action的产生是基于agent参数θ。
如下图所示,该搜索框架由三个部分组成:一个基于递归神经网络(RNN)的控制器、一个获取模型精度的训练器和一个基于移动设备的推理引擎,用于测量延迟。对于每个采样的模型m,在目标任务上对其进行训练以获得其精度ACC(m),并在真实的移动设备上运行它,从而获得其推理延迟LAT(m) 。之后,便可以计算收益值R(m)(也就是目标函数)。最后,参数θ将会使用PPO原则,通过式5定义的最大化收益被更新。

庐山真面目(自动生成的)
优化出的MnasNet-A1模型结构如下所示,从图中可以发现,模型结构使用了3*3卷积和5*5卷积。与之前的Mobile Model不同的是,之前的仅使用3*3卷积。

从深度卷积运算量的公式中可以看出,在深度卷积中,5*5卷积效果要优于3*3卷积。即当卷积核的个数大于7后,5*5卷积的运算量要小于3*3卷积的运算量。