前言
这是一个KNN算法的应用实例,参考《机器学习实战》中的datingTestSet2.txt的数据集。
可以通过对不同约会对象的特征进行分析然后自动得出以下三种结论:
- 不喜欢的
- 有点魅力的
- 很有魅力的
准备数据
这个数据集中针对每一个约会对象收集了三种具有代表性的特征,分别是:
- 每年获得的飞行常客里程数
- 玩网游所消耗的时间比
- 每年消耗的冰淇淋公升数
然后对每个约会对象的三种结论进行打分,对应的分数分别为1、2、3。
数据展示:
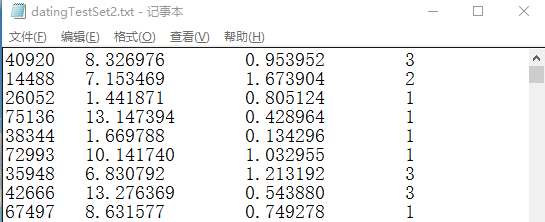
这样的数据需要处理成分类器可以接受的格式,所以我们创建了file2matrix函数用与完成这个功能。
代码如下 :
# ==========================# 读入文本记录,转换为NumPy,便于其他函数使用# 输入:文本记录的路径# ==========================def file2matrix(filename):fr = open(filename)arrayOLines = fr.readlines()numberOfLines = len(arrayOLines)returnMat = zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrayOLines:line = line.strip() # 删除字符串首尾的空白符(包括' ', ' ', ' ', ' ')listFromLines = line.split(" ")returnMat[index, :] = listFromLines[0:3]classLabelVector.append(int(listFromLines[-1]))index += 1return returnMat, classLabelVector
可视化分析数据:
我们用matplotlib制作原始数据的散点图,用于分析并找出三个特征中的哪两个特征可以得到更好的分类效果。
绘图代码:
def plotSca(datingDataMat, datingLabels):import matplotlib.pyplot as pltfig = plt.figure()ax1 = fig.add_subplot(121)# 玩网游所消耗的时间比(横轴)与每年消耗的冰淇淋公升数(纵轴)的散点图ax1.scatter(datingDataMat[:,1], datingDataMat[:, 2], 15.0*array(datingLabels), 5.0*array(datingLabels))ax2 = fig.add_subplot(122)# 每年获得的飞行常客里程数(横轴)与 玩网游所消耗的时间比(纵轴)的散点图ax2.scatter(datingDataMat[:,0], datingDataMat[:, 1], 15.0*array(datingLabels), 5.0*array(datingLabels))plt.show()
绘图效果:
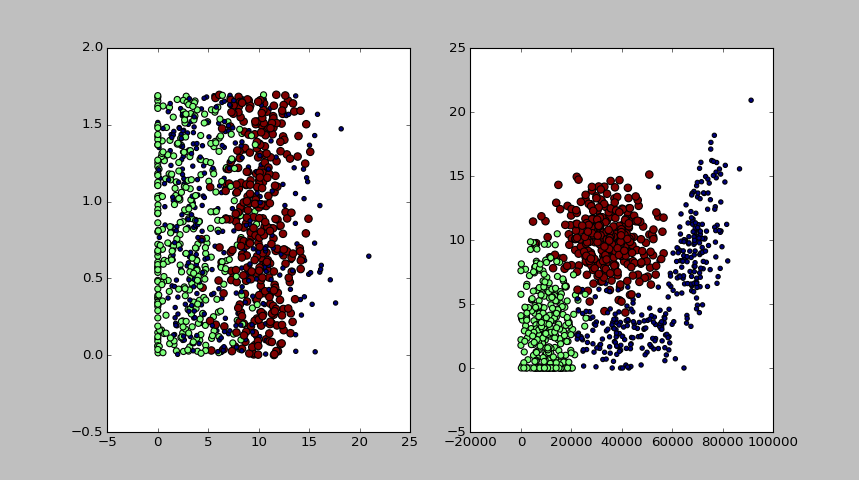
从图中可以看出,显然图二中展示的两个特征更容易区分数据点从属的类别。
归一化数值:
从展示数据中我们可以很明显的看出,不同特征值量级相差太大。
而他们在模型中占的权重又并不比其他特征大,这个时候就需要对特征值进行归一化,
也就是将取值范围处理为0到1或者-1到1之间
这里用autoNorm()函数实现这个功能
# =====================================# 如果不同特征值量级相差太大,# 而他们在模型中占的权重又并不比其他特征大,# 这个时候就需要对特征值进行归一化,# 也就是将取值范围处理为0到1或者-1到1之间# 本函数就是对数据集归一化特征值# dataset: 输入数据集# =====================================def autoNorm(dataset):minVals = dataset.min(0)maxVals = dataset.max(0)ranges = maxVals - minValsnormDataset = zeros(shape(dataset))m = dataset.shape[0]normDataset = dataset - tile(minVals, (m, 1))normDataset = normDataset/tile(ranges, (m, 1)) # 矩阵中对应数值相除return normDataset, ranges, minVals
测试算法:
通过上面的准备工作,再加上上一节的classify0分类函数就可以构成一个完整的分类器,用于对约会对象快速分类打分。
测试的时候一个很重要的工作就是评估算法的正确率。
通常我们会把整个数据集按9:1的比例分成训练集和测试集。
测试集就是用来检测分类器的正确率。
需要注意的是,在选择测试集的时候需要保持数据的随机性。
测试分类代码如下:
'''分类器针对约会网站的测试代码'''def datingClassTest():hoRatio = 0.10 # 数据集中用于测试的比例filePath = "E:mlmachinelearninginactionCh02datingTestSet2.txt"datingDataMat, datingLabels = file2matrix(filePath)# plotSca(datingDataMat, datingLabels)normMat, ranges, minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(hoRatio*m)errcounter = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i, :],normMat[numTestVecs:m, :],datingLabels[numTestVecs:m], 3)print "the classifier came back with: %d, the real answer is: %d" %(classifierResult, datingLabels[i])if (classifierResult !=datingLabels[i]): errcounter +=1.0print "the total error rate is: %f" % (errcounter/float(numTestVecs))print errcounter
输出效果如图所示:
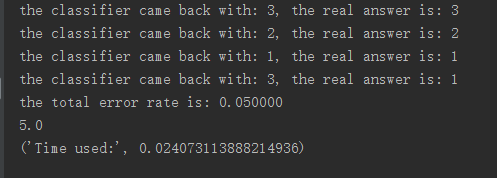
输出表示错误率为5%,且显示了算法的运行时间(通过import time,然后用time.clock - time.start实现)
小结
从运行效果看,算法的优点是精度高。而且算法对异常值不敏感,不需要事先训练。
但是从算法步骤上看,在对每一个新数据进行分类的时候都要和训练集中的每一个已知数据进行比较和相似度计算
可以预见的是,一旦数据集很大的时候,算法所要求的时间复杂度和空间复杂度就会迅速提高