数据集
house.csv
数据概览

代码
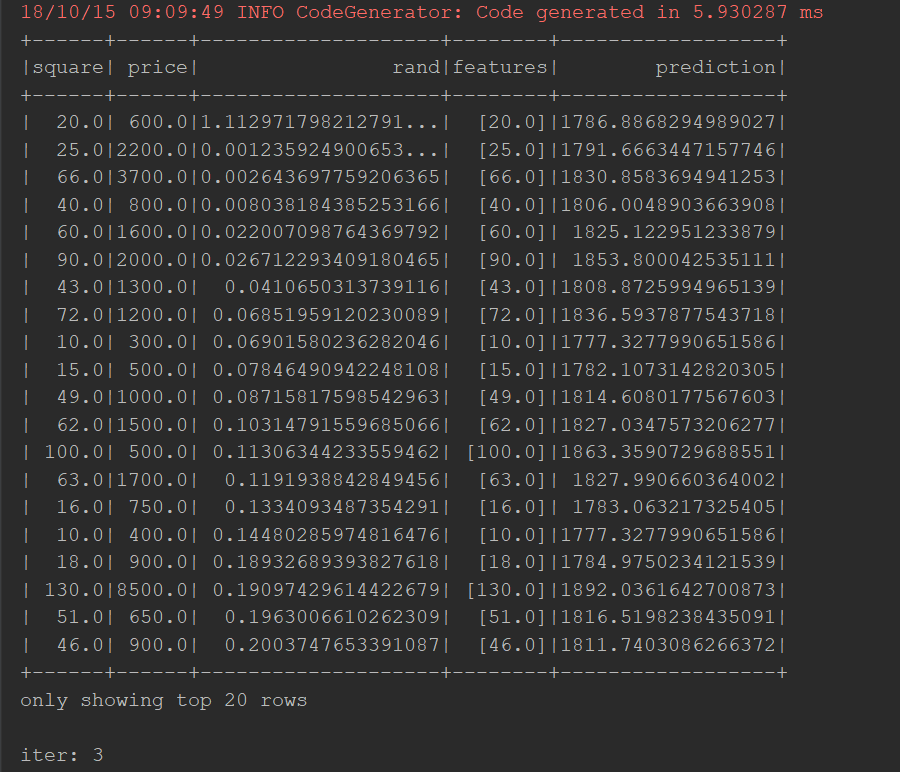
package org.apache.spark.examples.examplesforml import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} import scala.util.Random /* 日期:2018.10.15 描述: 7-6 线性回归算法 预测房价 数据集:house.csv */ object Linear { def main(args:Array[String]): Unit ={ val conf=new SparkConf().setMaster("local[*]").setAppName("LinearregRession") val sc=new SparkContext(conf) val spark=SparkSession.builder().config(conf).getOrCreate() val file=spark.read.format("csv") .option("header","true")//y .option("sep",";")//分隔符 .load("D:\机器学习算法准备\7-6线性回归-预测房价\house.csv") import spark.implicits._ val random =new Random() val data=file.select("square","price") .map(row => (row.getAs[String](0).toDouble,row.getAs[String](1).toDouble,random.nextDouble())) .toDF("square","price","rand") .sort("rand") data.show() val assembler=new VectorAssembler() .setInputCols(Array("square")) .setOutputCol("features") val dataset=assembler.transform(data) var Array(train,test)=dataset.randomSplit(Array(0.8,0.2),1234L) train.show() println(test.count()) var regression=new LinearRegression().setMaxIter(10).setRegParam(0.3).setElasticNetParam(0.8) val model=regression.setLabelCol("price").setFeaturesCol("features").fit(train) model.transform(test).show() val s = model.summary.totalIterations println(s"iter: ${s}") } }
输出: