释名
灰色关联度分析(Grey Relation Analysis,GRA),是一种多因素统计分析的方法。简单来讲,就是在一个灰色系统中,我们想要了解其中某个我们所关注的某个项目受其他的因素影响的相对强弱,再直白一点,就是说:我们假设以及知道某一个指标可能是与其他的某几个因素相关的,那么我们想知道这个指标与其他哪个因素相对来说更有关系,而哪个因素相对关系弱一点,依次类推,把这些因素排个序,得到一个分析结果,我们就可以知道我们关注的这个指标,与因素中的哪些更相关。
( note : 灰色系统这个概念的提出是相对于白色系统和黑色系统而言的。这个概念最初是由控制科学与工程(hhh熟悉的一级学科)的教授邓聚龙提出的。按照控制论的惯例,颜色一般代表的是对于一个系统我们已知的信息的多少,白色就代表信息充足,比如一个力学系统,元素之间的关系都是能够确定的,这就是一个白色系统;而黑色系统代表我们对于其中的结构并不清楚的系统,通常叫做黑箱或黑盒的就是这类系统。灰色介于两者之间,表示我们只对该系统有部分了解。)
举例
为了说明灰色关联度分析的应用场景,我们利用下图进行说明:
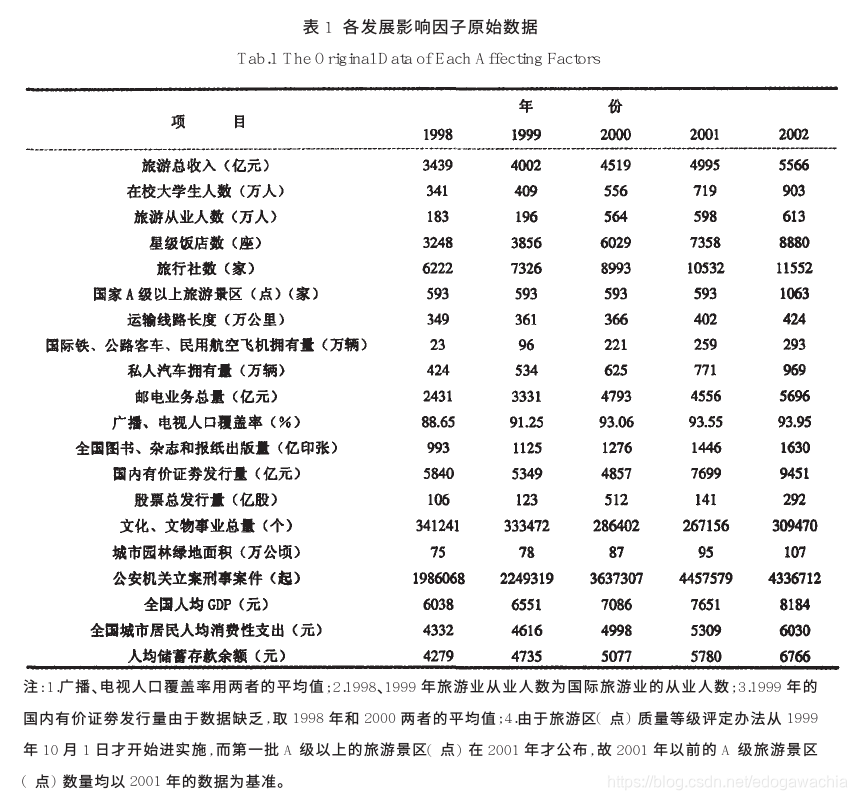
该图来源于参考文献1。这篇文献研究的内容是旅游业发展的影响因子,看该表格,第一行为五年的旅游总收入,代表着旅游业发展的程度,而下面的这些要素就是我们需要分析的因子,比如在校大学生数,旅行社数,星级饭店数,A级景区数等等。最终目的是要得到一个排序,从而说明这些因子对旅游总收入的关联性的程度。
操作步骤与原理详解
(1) 确立母序列
(参考序列,在上面栗子中就是1998~2002年的旅游总收入序列)和子序列(比较序列,也就是需要确立顺序的因素序列,上栗中的除了第一行以外的所有因素都可以作为参考序列)
为了后面的表述方便,这里统一一下notation:
我们用x_i(k)表示第i个因素的第k个数值
用上面的栗子来说
比如第一个因素是在校大学生人数,那么x_1(1)就表示在校大学生人数在1998年的取值,也就是341,x_1(2)就是1999年的取值,
而x_2(1)就是表示旅游从业人数在1998年的数值。以此类推。
我们用x_0(k)表示母序列,i≥1的表示子序列,也就是要分析的要素的序列。
如果不写括号,比如x_i ,就代表这个元素的整个序列,也就是向量 x_i = [x_i(1), x_i(2), ... , x_i(n)]
n为每个向量的维度,也就是每个元素的特征的数量,在上栗中,n就是5,因为有五年的数据,代表五维向量。
以下所有表述都用该notation表示。
详解: 这个就是我们任务的目的(找到子序列和参考序列的关联程度),所以不需要再解释了吧~
(2)归一化,或者叫 无量纲化。
详解: 因为我们的这些要素是不同质的东西的指标,因此可能会有的数字很大有的数字很小,但是这并不是由于它们内禀的性质决定的,而只是由于量纲不同导致的,因此我们需要对它们进行无量纲化。这个操作一般在数据处理领域叫做归一化(normalization),也就是减少数据的绝对数值的差异,将它们统一到近似的范围内,然后重点关注其变化和趋势。
如下图所示,这是上面表格中前3个元素随年的变化曲线,以及作为母序列的旅游总收入:
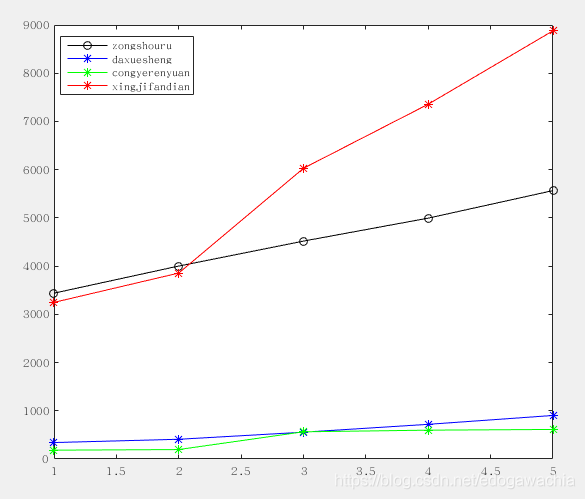
可以看到,有两个曲线绝对数值很大,而另外两个很小,如果不做处理必然导致大的数值的影响会”淹没“掉小数值的变量的影响。
所以我们要对数据进行归一化处理,主要方法有如下几个:
(1) 初值化: 顾名思义,就是把这一个序列的数据统一除以最开始的值,由于同一个因素的序列的量级差别不大,所以通过除以初值就能将这些值都整理到1这个量级附近。
公式: x_i(k)' = x_i(k) / x_i(1) i = 1,...,m, k = 1,...,n
(m为因素个数,n为每个因素的数据维度,仍如上栗,n=5,m=3(我们只看前三个因素,就是曲线图里画的这三种,和旅游总收入的关联,数据维度为5,即五年))
(2) 均值化: 顾名思义,就是把这个序列的数据除以均值,由于数量级大的序列均值比较大,所以除掉以后就能归一化到1的量级附近。
公式: x_i(k)' = x_i(k) / ( mean(x_i) ) (除以均值)
其中 : mean(x_i) = (1/n) sum_k=1^n (x_i(k)) (求第i个因素序列的均值)
其余还有如区间化,即把序列的值规范到一个区间,比如[0, 1],之间。这个方法实际上在数据处理中应用比较多,但是在GRA中似乎常用均值化或者初值化,所以在此不介绍。
这里我们按照参考文献中的采用的方法,用初值化进行归一化,得到的结果如下图:
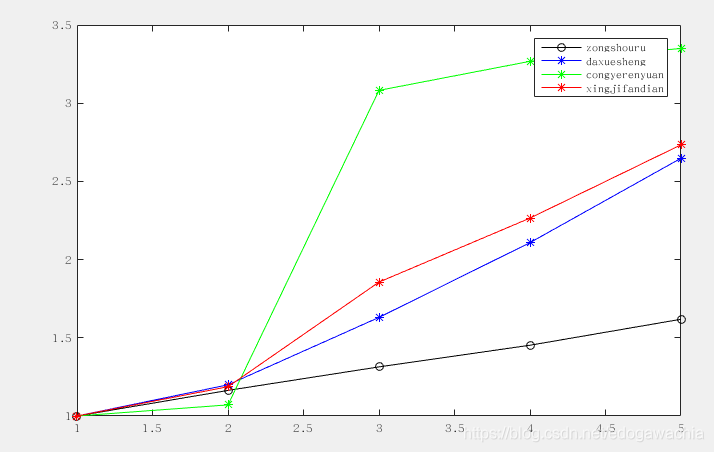
可以看到,归一化以后的数据,量级差别变小了,这是为了后面提供铺垫,因为我们关注的实际上是曲线的形状的差异,而不希望绝对数值对后面的计算有影响。
(3)计算灰色关联系数
先放上公式:
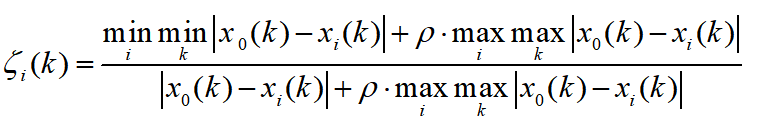
详解:
首先,我们把i看做固定值,也就是说对于某一个因素,其中的每个维度进行计算,得到一个新的序列,这个序列中的每个点就代表着该子序列与母序列对应维度上的关联性(数字越大,代表关联性越强)。
仔细观察这个公式,rho是一个可调节的系数,取值为(0,1),大于零小于一,这一项的目的是为了调节输出结果的差距大小,我们放在后面讲。我们先假设把rho取成0,那么,这个式子就变成了
pseudo_zeta_i(k) = min min |x_0(k) - x_i(k)| / |x_0(k) - x_i(k)| = constant / |x_0(k) - x_i(k)|
我们看上面这个式子,可以发现,分子上这个数值,对于所有子序列来说都是一样的(,分子上这个数实际上就是所有因素的所有维度中,与母序列(参考序列,即我们要比较的序列)距离最近的维度上的距离。为什么要这样做呢?这样来想,假如我们没有进行归一化,或者不是用的初值化,而是用的均值化或者其他方法,可能会导致曲线之间,也就是母序列和各个子序列之间仍然有一段距离,那么这个距离最小值与下面的每个维度的距离相除,实际上也可以看成是一种取消量纲的手段。对于所有子序列,这个分子是相同的,所以实际上,这个系数pseudo_zeta是与第k个维度上,子序列与母序列的距离(差的绝对值,通常叫做l1范数(l1-norm))成反比,也就是说,这两个数距离越远,我们认为越不相关,这是符合直觉的。
当然,如果用了初值化归一化数据,如上面的图2所示,min min |x_0(k) - x_i(k)| 对每个i都会变成0,这样就不好了,因为这样一来,所有的zeta_i(k)都成了0,是无意义的。所以这时候我们就看到后面的 rho max max这一项的作用了。这一项对于每个i来说也是一个不变的常数constant,所以可以理解为给上面那个式子的分子分母同时加上某个数值,如下所示:
zeta_i(k) = (aconstant + bconstant) / (|x_0(k) - x_i(k)| + bconstant)
这样做的目的是什么呢? 我们举个栗子: 对于两个分数: 1/5 和 1/4 ,它们的分子一样,分母相差为1,这时候他们的值相差1/20,也就是0.05,这就是没有+rho max max那一项的情况,分子相同,分母的差代表着与参考序列的距离。 如果我们给他们分子分母同时加上20,那么就是21/25和21/24,它们相差为0.035,可以看到,加入这一项会导致同样的距离的点的系数差,会因为计算而变小。很显然地,rho取得越大,不同zeta系数的差距就越小。
另外,由于分子上是min min,也就是距离的全局最小值,这就导致下面的分母必然大于分子(不考虑 rho max max 项),而且,如果分母非常大,曲线距离非常远,那么,zeta接近0; 相反,如果x_i和x_0在所有维度上的差完全一样,那么分数的值就是1。这样zeta取值范围就是0~1之间,0表示不相关,1表示强关联性。这也符合认知。考虑上rho max max 项之后,我们知道对于一个真分数,分子分母都加一个同样的值,仍然是真分数(实际上是一个添加溶质的溶液的问题)。也就是说,仍然是0到1。
总结来说,rho是控制zeta系数区分度的一个系数,rho取值0到1, rho越小,区分度越大,一般取值0.5较为合适。zeta关联系数取值落在0到1之间。
接上栗,我们对上述三个子序列做出关联系数zeta的序列,结果如下:
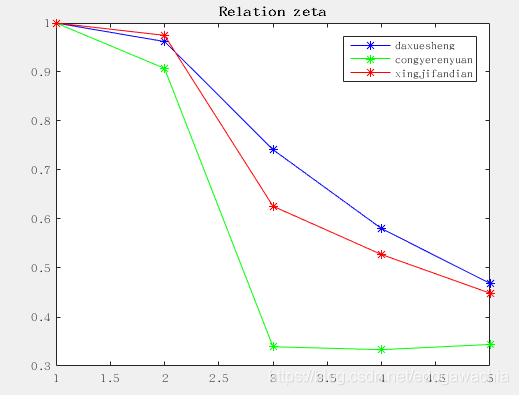
其实从这个图中已经可以看出,大学生这一因素对旅游也的相关性普遍要高一些,从业人员相对影响少一些。星级饭店的数量居中。
(4) 计算关联系数均值,形成关联序
根据上图其实已经可以看出大概的趋势,但是这只是因为这个恰好所有维度上的趋势比较一致,实际上,我们得到zeta关联系数的值以后,应该对每个因素在不同维度上的值求取均值,换句话说,也就是对于上面那些zeta 的曲线,同一个颜色的求取均值。结果如下:
>> mean(zeta_1)
ans =
0.7505
>> mean(zeta_2)
ans =
0.5848
>> mean(zeta_3)
ans =
0.7154
可以看到,根据关联系数大小,排序结果为:
大学生人数 > 星级饭店数量 > 从业人员人数
这和参考文献论文中的结论是一致的:

(由于论文中用了所有的因子,导致max max 这个全局最大值不同,所以计算出的关联度数值与复现计算的结果数值不一样,但是这三个因子的关联度的排序是一致的,说明关联度是一个相对的指标,它反映的是不同因子与参考内容的关联程度)
总结
GRA算法本质上来讲就是提供了一种度量两个向量之间距离的方法,对于有时间性的因子,向量可以看成一条时间曲线,而GRA算法就是度量两条曲线的形态和走势是否相近。为了避免其他干扰,凸出形态特征的影响,GRA先做了归一化,将所有向量矫正到同一个尺度和位置,然后计算每个点的距离。最后,通过min min 和max max 的矫正,使得最终输出的结果落在0到1之间,从而符合系数的一般定义。rho调节不同关联系数之间的差异,换句话说,就是输出的分布,使其可以变得更加稀疏或者紧密。以数学角度要言之,该算法即度量已归一化的子向量与母向量的每一维度的l1-norm距离的倒数之和,并将其映射到0~1区间内,作为子母向量的关联性之度量的一种策略。
附录:MATLAB代码
下面是该博文中为举栗子复现的参考文献1中的计算过程MATLAB代码:
% Grey relation analysis
clear all
close all
clc
zongshouru = [3439, 4002, 4519, 4995, 5566];
daxuesheng = [341, 409, 556, 719, 903];
congyerenyuan = [183, 196, 564, 598, 613];
xingjifandian = [3248, 3856, 6029, 7358, 8880];
% define comparative and reference
x0 = zongshouru;
x1 = daxuesheng;
x2 = congyerenyuan;
x3 = xingjifandian;
% normalization
x0 = x0 ./ x0(1);
x1 = x1 ./ x1(1);
x2 = x2 ./ x2(1);
x3 = x3 ./ x3(1);
% global min and max
global_min = min(min(abs([x1; x2; x3] - repmat(x0, [3, 1]))));
global_max = max(max(abs([x1; x2; x3] - repmat(x0, [3, 1]))));
% set rho
rho = 0.5;
% calculate zeta relation coefficients
zeta_1 = (global_min + rho * global_max) ./ (abs(x0 - x1) + rho * global_max);
zeta_2 = (global_min + rho * global_max) ./ (abs(x0 - x2) + rho * global_max);
zeta_3 = (global_min + rho * global_max) ./ (abs(x0 - x3) + rho * global_max);
% show
figure;
plot(x0, 'ko-' )
hold on
plot(x1, 'b*-')
hold on
plot(x2, 'g*-')
hold on
plot(x3, 'r*-')
legend('zongshouru', 'daxuesheng', 'congyerenyuan', 'xingjifandian')
figure;
plot(zeta_1, 'b*-')
hold on
plot(zeta_2, 'g*-')
hold on
plot(zeta_3, 'r*-')
title('Relation zeta')
legend('daxuesheng', 'congyerenyuan', 'xingjifandian')
参考文献:
- 马晓龙. 旅游业发展影响因子灰色关联分析[J]. 人文地理, 2006, 21(2):37-40.
- 谭学瑞, 邓聚龙. 灰色关联分析:多因素统计分析新方法[J]. 统计研究, 1995, 12(3):46-48.
- 刘思峰, 蔡华, 杨英杰, et al. 灰色关联分析模型研究进展[J]. 系统工程理论与实践, 2013, 33(8):2041-2046.
2018年12月29日02:06:16
to Rita ~