ResNet
相关文献:
Deep Residual Learning for Image Recognition
Kaiming He Xiangyu Zhang Shaoqing Ren Microsoft Research
CVPR 2016
其他参考文献:
Identity Mappings in Deep Residual Networks http://arxiv.org/abs/1603.05027
Residual Networks Behave Like Ensembles of Relatively Shallow Networks http://arxiv.org/abs/1605.06431
The Shattered Gradients Problem: If resnets are the answer, then what is the question? http://arxiv.org/abs/1702.08591
模型介绍:
ResNet是一个很有名的模型,而且residual learning的方法,即不直接学习输出,而是学习残差的方法现在已经在图像的low-level中被广泛应用了。ResNet在结构角度看就可以看成是一组小的学习残差的网络连接而成的深层网络。然而对于ResNet的能力究竟来自何处,或者ResNet是否解决了梯度消失或者梯度爆炸等问题仍然存在一定争议,也有一些文章对这些问题进行了一些理论的分析。下面先介绍2015年ImageNet比赛上的ResNet模型的最原始的文章,然后结合其他参考文献对其中的一些问题进行讨论。
模型结构
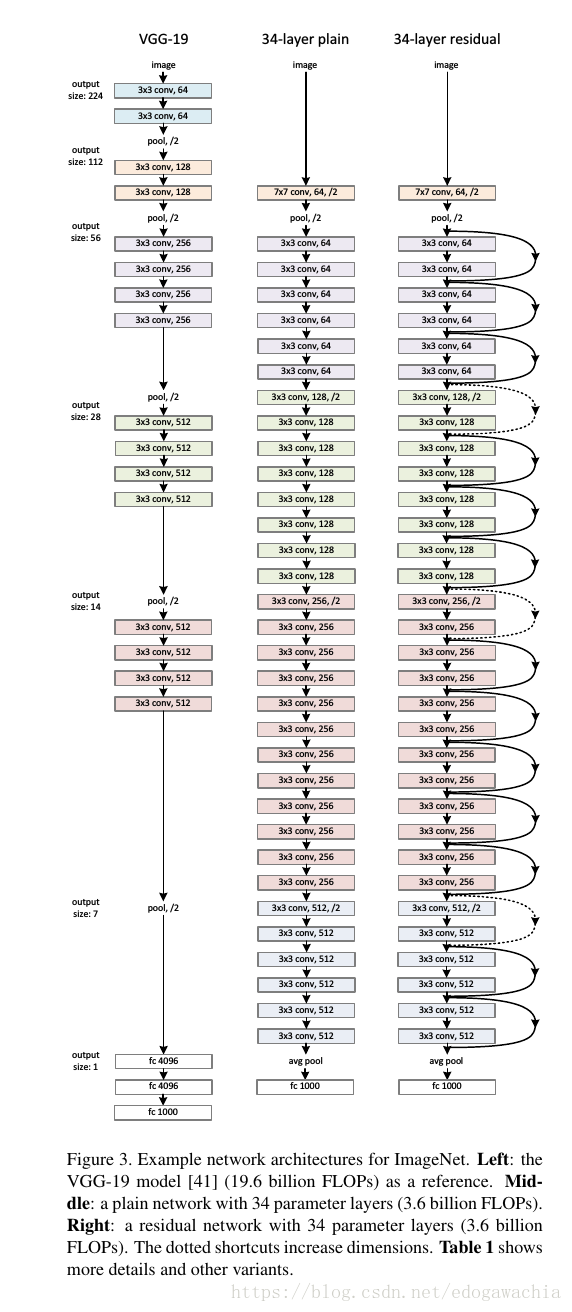
上面是对vgg和没有residual learning结构的plain network结构的对比,右边是34层的ResNet。
可以看出,ResNet的结构是由若干小的block组成的,每个block的结构如下所示:
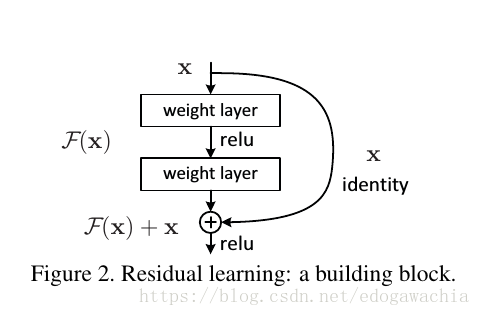
为何要引入shortcut?原因在于如下这样一个现象:
这个现象被称为degradation problem,指的是在网络层数到一定程度后,训练的误差和测试误差都较高而且不再下降的问题。上图中的degradation因为训练集的error也下不去,显然不是因为过拟合,而是因为网络太深,导致没法很好的optimize。
由于前面的文章已经证明了,网络的深度有助于更好的提取和表征数据特征,从而容易得到更好的效果。所以我们希望能从增加网络层数这一条路径继续下去从而提高网络性能。当然,googlenet的论文中提到过,网络过深容易overfit。但是这里作者指出了另一个问题,就是所谓的梯度消失或者梯度爆炸 vanishing/exploding gradients 现象,也就是在训练过程中可能出现的问题。
作者是这样论证这个问题的:深度网络理论上至少不会比比它更浅的网络的train error更大,因为每一个深网络都可以看成是一个浅的网络加上一些层以后形成的,那么如果我们将这些新加入的层做成恒等映射层 (identity map),那么最终的结果就是浅层网络的最优解。因此说明深层网络也存在一个这样的解,或者说至少要达到浅层的水平。那么实际中没法达到或者没法在可以接收的时间内达到,就需要改变训练策略。
ResNet的策略就是不让layer直接学习一个映射,而是学习一个residual,也就是说,若是想学习H(x),那么就改成学习F(x) = H(x) - x,就是上面的block的图中所示的那样。We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. 最极端的情况,如果最优解就是一个恒等映射的话,那么把residual push 为0,也就是将输入通过神经网络后变成0,是很容易办到的。
作者展示了用这种residual learning的block组成的网络可以很容易优化,还能得到accuracy gain。
更6的是,作者用这种结构把网络做到了1000+层….最开始的Lenet也就5个卷积层,号称深度的vgg也就19个,googlenet也是二十左右,而ResNet由于这种结构可以训练,直接提高到了上百甚至上千层。
residual learning
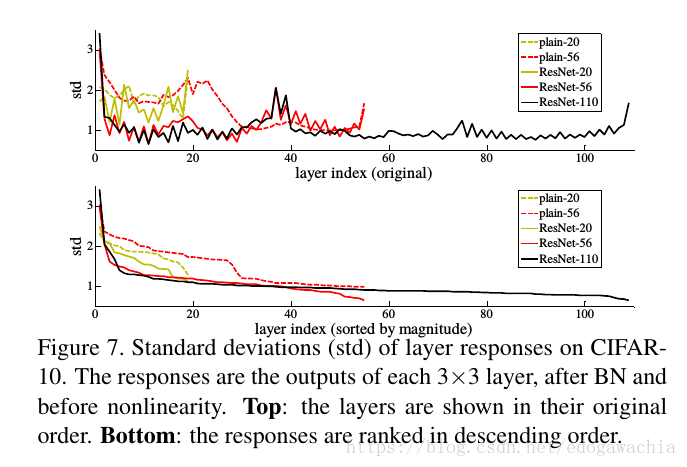
The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers. 作者从degradation中猜测,可能深度网络不太能很好的表征恒等映射(因为按照前文的思想实验深层只要是恒等映射就能达到浅层网络的最优解,然而没有),所以直接拉过来一根跳线,即如果需要恒等映射就直接走跳线。另外,在实际case中,一般恒等映射,也就是不变换不太可能是最优解,但是可能最优解相比于接近0来说更接近输入本身,所以我们学的是对于reference的扰动,而不是本身,这可以通过观察Learned residual function具有更小的response来说明。
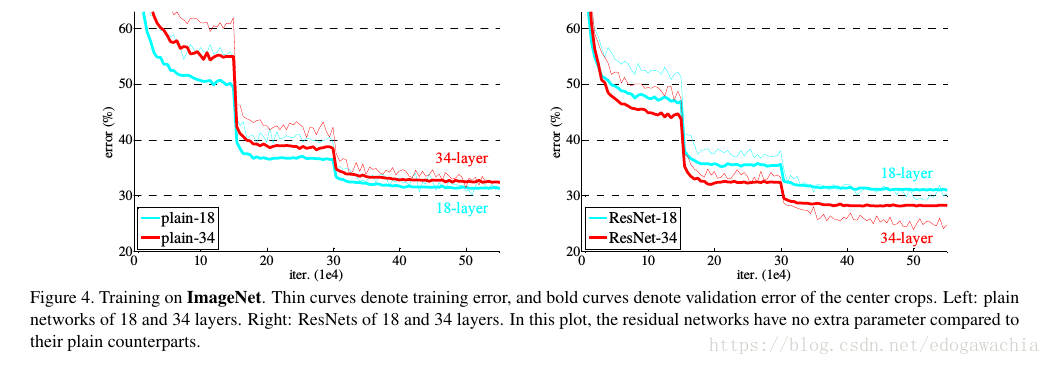
实验结果
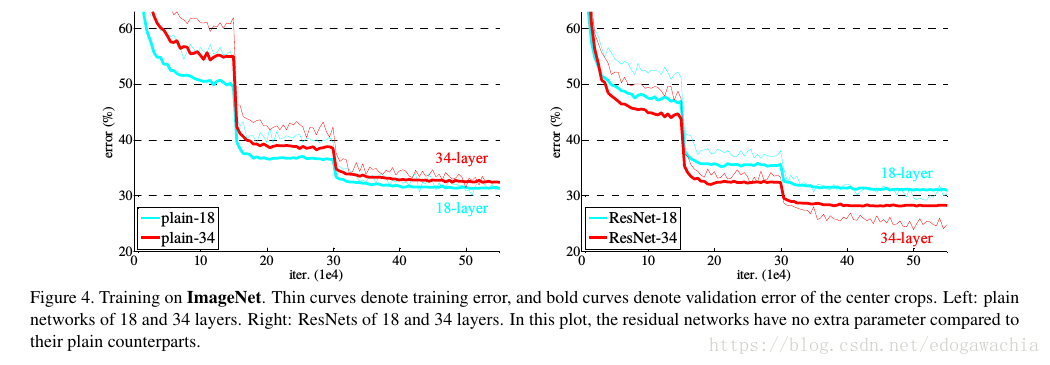
上图可以看出,plain网络具有degradation,即深层比浅层error还大,而ResNet就没有这一现象了。
作者这里说这种优化的困难不太像是vanishing gradient引起的,因为加了BN层,保证了variance非零,而且反传的gradient的norm也是正常的。作者认为是由于收敛率指数型导致的收敛速度太慢。We conjecture that the deep plain nets may have exponentially low convergence rates, which impact the reducing of the training error3 . The reason for such optimization difficulties will be studied in the future.
为了减小运算量,以便用更深的网络,作者改变了block结构,加上了1×1的bottleneck
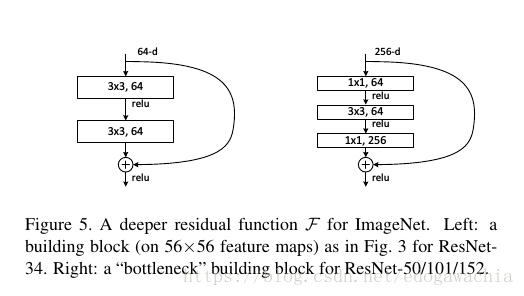
关于恒等映射(identity map)
在16年的一篇文章中(Identity Mappings in Deep Residual Networks 作者就是ResNet的原作者们),通过推导论证了一个结论:Our derivations reveal that if both h(xl) and f (yl) are identity mappings, the signal could be directly propagated from one unit to any other units, in both forward and backward passes. 这里的h,f以及xl和yl如下图:

如果不考虑激活函数和BN,而h又是identity map的话,就可以做下面的推导:

可以看到,某一个block的输入可以写成前面某项的输入加上一个和式,这个和式表达的是前面某项到该输入之间的若干个矩阵卷积后再激活的结果,由于是和表达式,求导后仍然是和式,所以某项的梯度可以直接传到其他项。
而如果是plain network,正如最后一句话说的,那么某一个xL就可以写成一个乘积表达式,那么求导就自然会有连乘,也就是说某一项的gradient不一定能较好地传给其他项。
那么如果h是一个x的正比例函数,即系数不是1的情况呢?

经过推导可以看出,这样的话会导致要么梯度过小,从而消失,也就是关闭了shortcut,强制让信号从卷积层流过来;要么就是太大,可能会梯度爆炸。这就是选择identity map 的理由。
从ensemble的角度理解
Residual Networks Behave Like Ensembles of Relatively Shallow Networks 一文中提出,可以将ResNet理解为一个不同长度的多路径的集合的一个ensemble-like的东西,并且发现只有短的path在训练中是有必要的,因为long path不贡献gradient。这篇文章的摘要如下:

把ResNet展开就是下面的右图:
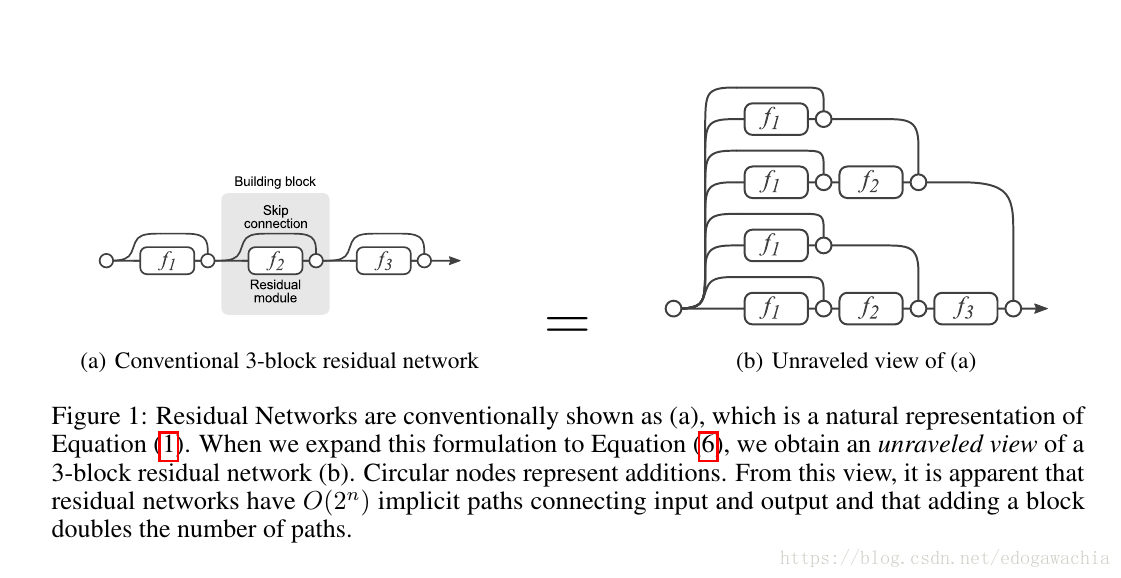
实际上,这个展开图和前面文章的展开式是同一个东西。下面是一个实验:在vgg中删去任何一个path,test error 会变大且随机,而对于ResNet则影响甚微。
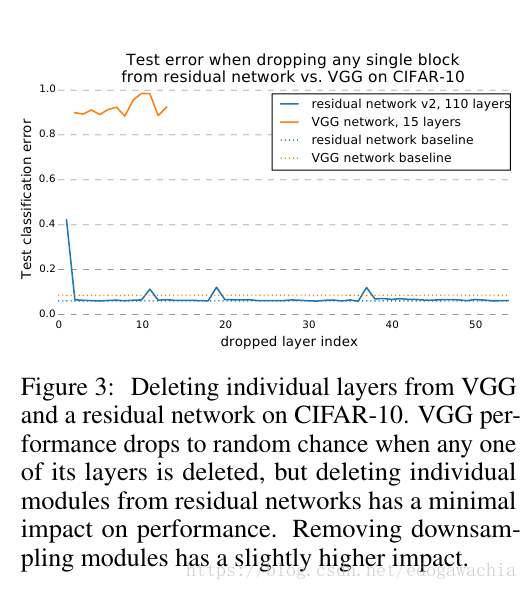
作者的解释是:It shows that residual networks can be seen as a collection of many paths. As illustrated in Figure 2 (a), when a layer is removed, the number of paths is reduced from 2n to 2n−1 , leaving half the number of paths valid. VGG only contains a single usable path from input to output. Thus, when a single layer is removed, the only viable path is corrupted. This result suggests that paths in a residual network do not strongly depend on each other although they are trained jointly. ResNet因为是一个path的集合,去掉某个仍然有一般的路径可走;而vgg只有一条可行路径,删除了某个layer,这个路径就不存在了。
限于时间,最后一篇 The Shattered Gradients Problem: If resnets are the answer, then what is the question? 留作之后再细读。此略。
2018年04月19日00:50:04