
# 上代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import shutil
import tarfile
base_dir = os.path.abspath(os.path.dirname(__file__))
print(base_dir)
# 文件拷贝
def CopyFiles(source_dir, target_dir):
for file in os.listdir(source_dir):
source_file = os.path.join(source_dir, file)
target_file = os.path.join(target_dir,file)
if os.path.isfile(source_file):
if not os.path.exists(target_dir):
os.mkdir(target_dir)
if not os.path.exists(target_file) or (os.path.exists(target_file) and (os.path.getsize(target_file) != os.path.getsize(source_file))):
#读文件 写文件的 方式可能会由于编码问题导致错误 这里选择文件拷贝的方式
#open(target_file,'wb').write(open(source_file,'rb').read())
shutil.copy2(source_file, target_dir)
if os.path.isdir(source_file):
First_Directory = False
CopyFiles(source_file,target_file)
# 文件打包
def make_targz(output_filename, source_dir):
with tarfile.open(output_filename, 'w:gz') as tar:
tar.add(source_dir,arcname=os.path.basename(source_dir) )
if __name__ == '__main__':
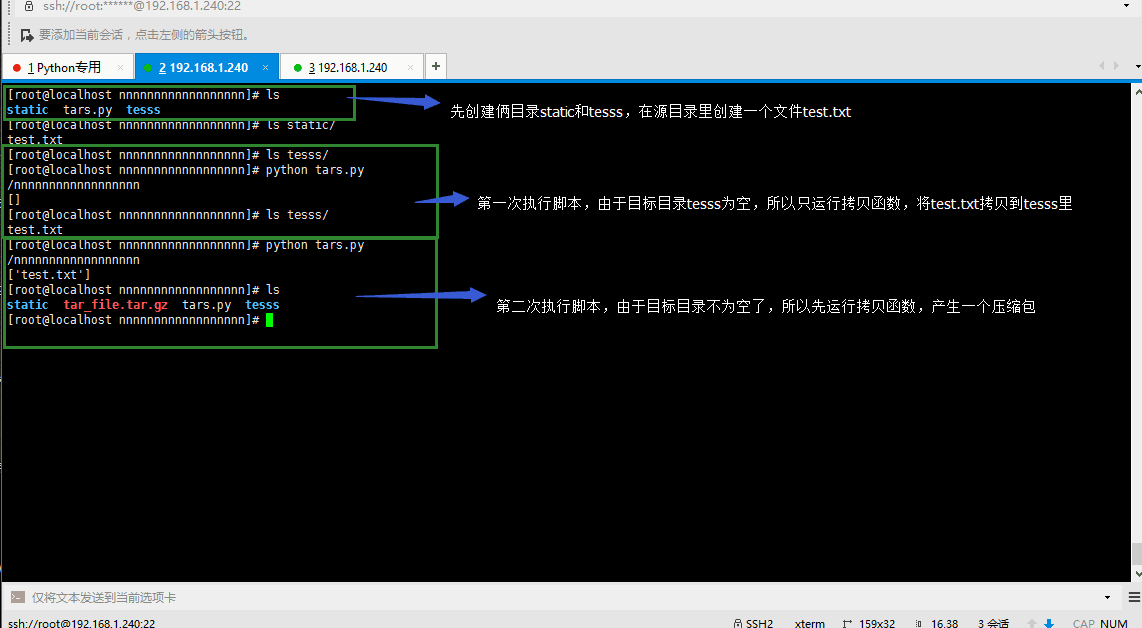
source_dir = os.path.join(base_dir,'static')
target_dir = os.path.join(base_dir,'tesss')
# 判断目标文件是否为空
# 目标文件为空直接 拷贝
print os.listdir(target_dir) #这里最好先判断目标目录是否存在,如果不存在就会报错,如果不加判断语句的话,就在当前目录里先创建好static和tesss这两个目录
if len(os.listdir(target_dir)) == 0:
CopyFiles(source_dir,target_dir)
else:
# 目标文件不为空 先打包 再删除 然后在拷贝
#打包
make_targz('tar_file.tar.gz',target_dir) #为了容易识别,这里给压缩包加上格式'.tar.gz'
shutil.rmtree(target_dir)
os.mkdir(target_dir)
CopyFiles(source_dir,target_dir)

文件打包
1、zip
import os, zipfile
#打包目录为zip文件(未压缩)
def make_zip(source_dir, output_filename):
zipf = zipfile.ZipFile(output_filename, 'w')
pre_len = len(os.path.dirname(source_dir))
for parent, dirnames, filenames in os.walk(source_dir):
for filename in filenames:
pathfile = os.path.join(parent, filename)
arcname = pathfile[pre_len:].strip(os.path.sep) #相对路径
zipf.write(pathfile, arcname)
zipf.close()
2、tar/tar.gz
import os, tarfile
#一次性打包整个根目录。空子目录会被打包。
#如果只打包不压缩,将"w:gz"参数改为"w:"或"w"即可。
def make_targz(output_filename, source_dir):
with tarfile.open(output_filename, "w:gz") as tar:
tar.add(source_dir, arcname=os.path.basename(source_dir))
#逐个添加文件打包,未打包空子目录。可过滤文件。
#如果只打包不压缩,将"w:gz"参数改为"w:"或"w"即可。
def make_targz_one_by_one(output_filename, source_dir):
tar = tarfile.open(output_filename,"w:gz")
for root,dir,files in os.walk(source_dir):
for file in files:
pathfile = os.path.join(root, file)
tar.add(pathfile)
tar.close()
文件拷贝 网上不错的例子:
import os
import shutil
yuanD = "F:scriptsmonitor"
mubiaoD = "F:scriptsCheungSSHweb"
#递归复制文件夹内的文件
def copyFiles(sourceDir,targetDir):
#忽略某些特定的子文件夹
if sourceDir.find("exceptionfolder")>0:
return
#列出源目录文件和文件夹
for file in os.listdir(sourceDir):
#拼接完整路径
sourceFile = os.path.join(sourceDir,file)
targetFile = os.path.join(targetDir,file)
#如果是文件则处理
if os.path.isfile(sourceFile):
#如果目的路径不存在该文件就创建空文件,并保持目录层级结构
if not os.path.exists(targetDir):
os.makedirs(targetDir)
#如果目的路径里面不存在某个文件或者存在那个同名文件但是文件有残缺,则复制,否则跳过
if not os.path.exists(targetFile) or (os.path.exists(targetFile) and (os.path.getsize(targetFile) != os.path.getsize(sourceFile))):
open(targetFile, "wb").write(open(sourceFile, "rb").read())
print targetFile+" copy succeeded"
#如果是文件夹则递归
if os.path.isdir(sourceFile):
copyFiles(sourceFile, targetFile)
#遍历某个目录及其子目录下所有文件拷贝到某个目录中
def copyFiles2(srcPath,dstPath):
if not os.path.exists(srcPath):
print "src path not exist!"
if not os.path.exists(dstPath):
os.makedirs(dstPath)
#递归遍历文件夹下的文件,用os.walk函数返回一个三元组
for root,dirs,files in os.walk(srcPath):
for eachfile in files:
shutil.copy(os.path.join(root,eachfile),dstPath)
print eachfile+" copy succeeded"
#删除某目录下特定文件
def removeFileInDir(sourceDir):
for file in os.listdir(sourceDir):
file=os.path.join(sourceDir,file) #必须拼接完整文件名
if os.path.isfile(file) and file.find(".jpg")>0:
os.remove(file)
print file+" remove succeeded"
if __name__ =="__main__":
copyFiles(yuanD,mubiaoD)
#removeFileInDir("./dir2")
#copyFiles2("./dir1","./dir2")