线性结构:
一、概念
- 线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系。
- 线性结构拥有两种不同的存储结构,即顺序存储结构和链式存储结构。顺序存储的线性表称为顺序表,顺序表中的存储元素是连续的,链式存储的线性表称为链表,链表中的存储元素不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息。
- 线性结构中存在两种操作受限的使用场景,即队列和栈。栈的操作只能在线性表的一端进行,就是我们常说的先进后出(FILO),队列的插入操作在线性表的一端进行而其他操作在线性表的另一端进行,先进先出(FIFO),由于线性结构存在两种存储结构,因 此队列和栈各存在两个实现方式。
二、部分实现
- 顺序表(顺序存储)
按照我们的习惯,存放东西时,一般是找一块空间,然后将需要存放的东西依次摆放,这就是顺序存储。计算机中的顺序存储是指在内存中用一块地址连续的空间依次存放数据元素,用这种方式存储的线性表叫顺序表其特点是表中相邻的数据元素在内存中存储位置也相邻,如下图:

1 // 倒置线性表 2 public void Reverse() 3 { 4 T tmp = default(T); 5 6 int len = GetLength() - 1; 7 for (int i = 0; i <= len / 2; i++) 8 { 9 if (i.Equals(len - i)) 10 { 11 break; 12 } 13 14 tmp = data[i]; 15 data[i] = data[len - i]; 16 data[len - i] = tmp; 17 } 18 } - 链表(链式存储)
假如我们现在要存放一些物品,但是没有足够大的空间将所有的物品一次性放下(电脑中使用链式存储不是因为内存不够先事先说明一下...,具体原因后续会说到),同时设定我们因为脑容量很小,为了节省空间,只能记住一件物品位置。此时我们很机智的找到了解决方案:存放物品时每放置一件物品就在物品上贴一个小纸条,标明下一件物品放在那里,只记住第一件物品的位置,寻找的时候从第一件物品开始寻找,通过小纸条我们可以找到所有的物品,这就是链式存储。链表实现的时候不再像线性表一样只存储数据即可,还有下一个数据元素的地址,因此先定义一个节点类(Node),记录物品信息和下一件物品的位置,我们把物品本身叫做数据域,存储下一件物品地址信息的小纸条称为引用域。链表结构示意图如下: 寻找物品的时候发现了一个问题,我们从一件物品找下一件物品的时候很容易,但是如果要找上一件物品就得从头开始找,真的很麻烦。为了解决这个问题我们又机智了一把,模仿之前的做法,在存放物品的时候多放置一个小纸条记录上一件物品的位置,这样就可以很快的找到上一件物品了。我们把这种方式我们称为双向链表,前面只放置一张小纸条的方式称为单向链表。
寻找物品的时候发现了一个问题,我们从一件物品找下一件物品的时候很容易,但是如果要找上一件物品就得从头开始找,真的很麻烦。为了解决这个问题我们又机智了一把,模仿之前的做法,在存放物品的时候多放置一个小纸条记录上一件物品的位置,这样就可以很快的找到上一件物品了。我们把这种方式我们称为双向链表,前面只放置一张小纸条的方式称为单向链表。
1 // 倒置单链表 2 public void Reverse() 3 { 4 Node<T> oldHead = Head; 5 Node<T> tmp ; 6 Head = null; //清空链表,解除Head跟oldHead之间的相同引用 7 8 while (oldHead != null) 9 { 10 tmp = Head; 11 Head = oldHead; 12 //解除Head跟oldHead之间的相同引用 13 oldHead = oldHead.Next; 14 Head.Next = tmp; 15 } 16 }由于数据存储结构不同导致使用场景上的巨大差异,顺序表由于元素连续具有随机存储的特点,所以查找数据很方便效率很高,但是插入、删除操作为了确保数据元素连续,需要移动大量的数据导致效率很低。而链表由于存储空间不要求连续,插入、删除只需修改相邻元素的引用域地址即可,所以效率很高,但查询需要从头引用开始遍历链表,效率很低。因此,如果只是进行查找操作而不经常插入、删除线性表中的数据元素,则使用顺序存储结构,反之,使用链式存储结构。
- 栈
其实成功完成顺序表和链表之后,栈已经没太多可说的了,主要是逻辑上的不同,毕竟栈也是一种特殊的线性结构。栈是一种操作限定在表尾部进行的线性表,表尾称为栈顶(Top),另一端固定不动,称为栈底(Bottom)。进栈、出栈示意图如下: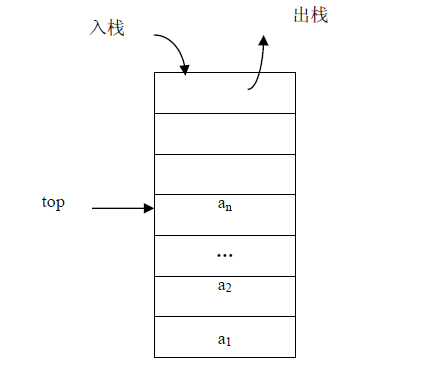
1 //链栈入驻 2 public void Push(T item) 3 { 4 Node<T> tmp = new Node<T>(item); 5 if (Top == null) 6 { 7 Top = tmp; 8 } 9 else 10 { 11 tmp.Next = Top; 12 Top = tmp; 13 } 14 Num++; 15 } 16 17 //顺序栈入栈 18 public void Push(T item) 19 { 20 if (IsFull()) 21 { 22 throw new Exception("Stack is full"); 23 } 24 25 data[++Top] = item; 26 } - 队列
队列与栈类似,仅仅是逻辑有一丢丢不同。队列是一种插入操作限定在表尾其他操作限定在表头的线性表。把进行插入操作的表尾称为队尾(Rear),把进行其它操作的头部称为队首(Front)。入队、出队示意图如下:
1 //链队入队 2 public void In(T item) 3 { 4 Node<T> node = new Node<T>(item); 5 if (Rear == null) 6 { 7 Rear = node; 8 Front = Rear; 9 } 10 else 11 { 12 Rear.Next = node; 13 Rear = Rear.Next; 14 } 15 ++num; 16 } 17 18 //循环队列入队 19 public void In(T item) 20 { 21 if (IsFull()) 22 { 23 throw new Exception("Queue is full"); 24 } 25 data[++Rear] = item; 26 }
非线性结构:
一、相关概念
树作为一种应用广泛的一对多非线性数据结构,不仅有数据间的指向关系,还有层级关系,示例见图一。因树的结构比较复杂,为了简化操作及存储,我们一般将树转换为二叉树处理,因此本文主要讨论二叉树。
- 二叉树
二叉树是每个节点最多拥有两个子节点的树结构,若移除根节点则其余节点会被分成两个互不相交的子树,分别称为左子树和右子树。二叉树是有序树,左右子树有严格的次序,若颠倒则成为一棵不一样的二叉树。 - 满二叉树
满二叉树,顾名思义除叶子节点外所有节点都拥有两个孩子,且叶子节点在同一层的二叉树,示例见图二。 - 完全二叉树
完全二叉树,移除最后一层节点后是满二叉树,且最后一层的节点都连续集中在最左面,示例见图三。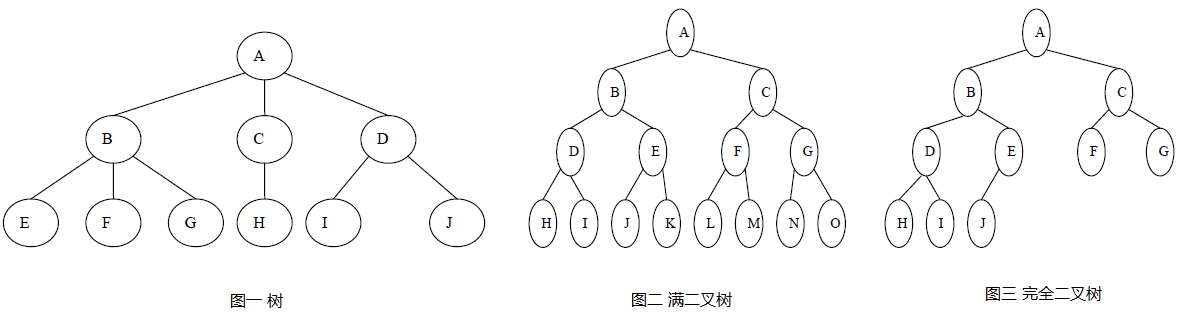
二、二叉树存储结构
- 顺序存储
根据完全二叉树的特性,可以计算出任意节点n的双亲节点及左右孩子节点的序号,因此完全二叉树的节点可以按照从上到下从左到右的顺序依次存储到一维数组中。非完全二叉树存储时应先将其改造为完全二叉树,以空替代不存在的节点,比较浪费存储空间,存储示意图见图四。 - 链式存储
树结构链式存储类似线性结构链式存储,先定义包含数据域和引用域的节点(Node),然后通过引用域存储节点之间的关系。根据二叉树的结构来看,节点Node至少包含数据域(Data),引用域(左孩子LChild、右孩子RChild),为了方便通过孩子节点查找父节点,引用域中可以考虑添加父节点引用(Parent),存储示意图见图五。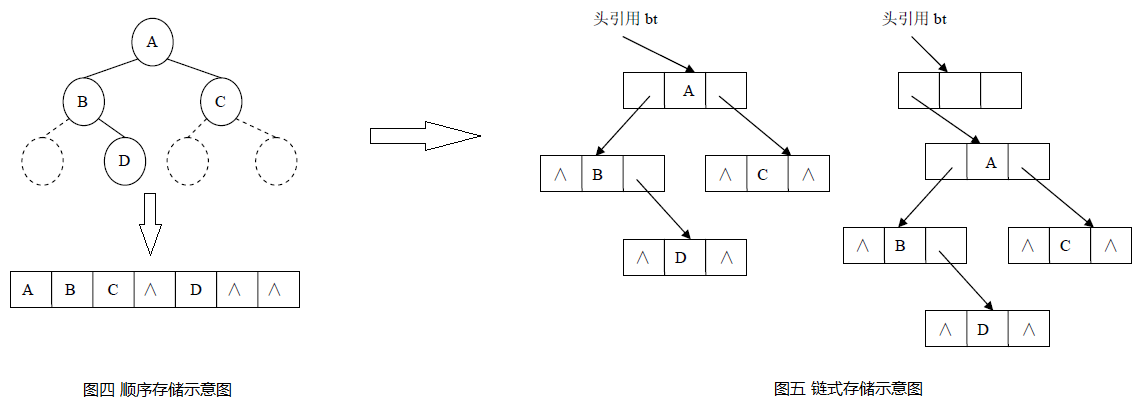
三、树与二叉树的转换
- 树转二叉树
加线,所有兄弟结点之间加一条连线。
抹线,对树中的每个结点,只保留他与第一个孩子结点之间的连线,删除它与其它孩子结点之间的连线。
整理,整理前两步得到的树,使之结构层次分明。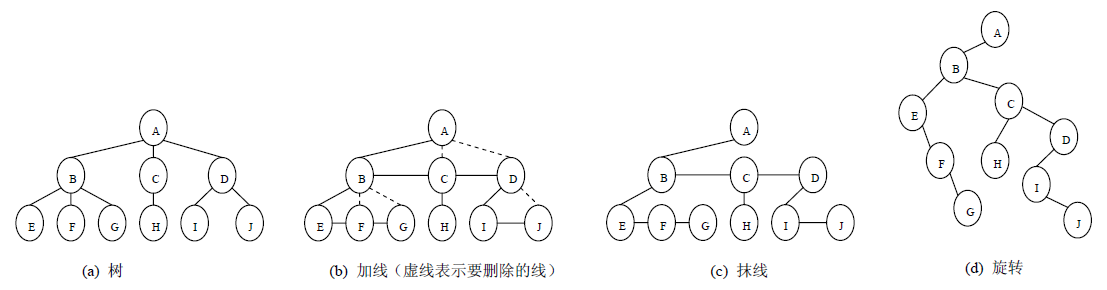
- 二叉树转树
加线,若某结点的左孩子结点存在,将左孩子结点的右孩子结点、右孩子结点的右孩子结点……都作为该结点的孩子结点,将该结点与这些右孩子结点用线连接起来。
抹线,删除原二叉树中所有结点与其右孩子结点的连线。
整理,整理前两步得到的树,使之结构层次分明。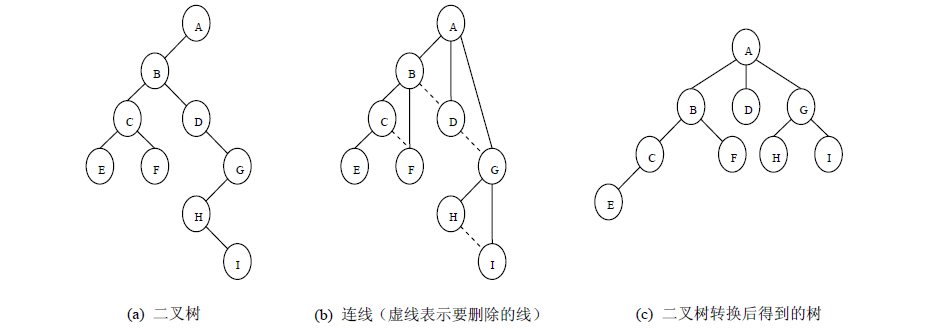
四、树遍历实现
1 /// <summary>
2 /// 先序遍历(DLR)
3 /// </summary>
4 /// <![CDATA[首先访问跟节点,然后遍历左子树,最后右子树]]>
5 static void PreOrder(Node<char> root)
6 {
7 if (root == null)
8 {
9 return;
10 }
11
12 Print(root);
13 PreOrder(root.LChild);
14 PreOrder(root.RChild);
15 }
16
17 /// <summary>
18 /// 中序遍历(LDR)
19 /// </summary>
20 /// <![CDATA[先遍历左子树,然后根节点,最后遍历右子树]]>
21 static void InOrder(Node<char> root)
22 {
23 if (root == null)
24 {
25 return;
26 }
27
28 InOrder(root.LChild);
29 Print(root);
30 InOrder(root.RChild);
31 }
32
33 /// <summary>
34 /// 后序遍历(LRD)
35 /// </summary>
36 /// <![CDATA[先遍历左子树,然后遍历右子树,最后遍历根节点]]>
37 static void PostOrder(Node<char> root)
38 {
39 if (root == null)
40 {
41 return;
42 }
43
44 PostOrder(root.LChild);
45 PostOrder(root.RChild);
46 Print(root);
47 }
48
49 /// <summary>
50 /// 层序遍历
51 /// </summary>
52 /// <![CDATA[从上向下从左到右]]>
53 static void LevelOrder(Node<char> root)
54 {
55 if (root == null)
56 {
57 return;
58 }
59 CSeqQueue<Node<char>> sq = new CSeqQueue<Node<char>>(50);
60 sq.In(root);
61 while (!sq.IsEmpty())
62 {
63 Node<char> tmp = sq.Out();
64 Print(tmp);
65
66 if (tmp.LChild != null)
67 {
68 sq.In(tmp.LChild);
69 }
70
71 if (tmp.RChild != null)
72 {
73 sq.In(tmp.RChild);
74 }
75 }
76 }