一、Github地址 课程项目要求
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 510 | 570 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | ||
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| | 合计 | 510|570
三、解题思路。即刚开始拿到题目后,如何思考,如何找资料的过程。
-
C++ 怎么读写文件?
学习了如何使用C++文件读写,使用头文件
。 -
怎么识别单词并统计个数?
可以创建结构体数组用来存每类单词和对应的个数,遍历一遍整个文档,以英文字母为开头的词语先暂时存在临时结构体中,全部读完该词语再进行判断是否符合单词规范,再跟单词结构数组对比,相同的单词数量加一,都不一样则存新的结构数组中。
-
怎么对单词数量排序,并且相同数量的按字典排序?
使用优先队列,之前存的单词数组放入优先队列中,个数多的优先,个数相同的,按单词字母字典排序优先。
-
怎么统计单词数,字符数,行数?
定义全局变量,识别到符合单词规范,单词数量累加;按要求,遍历文档时字符Ascii码在0-255之间则字符数累加。
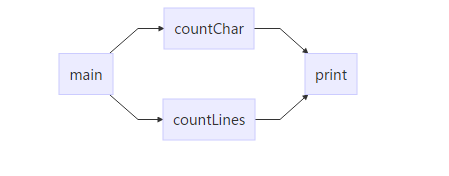
四、设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
定义全局变量计算个数,结构体数组存单词,一个主函数,调用三个函数:一个countChar(string u)//统计字符数,单词放入优先队列中,一个countLines(string u)//返回有效行数,一个输出函数print(string u)// 按要求输出到文件result.txt。
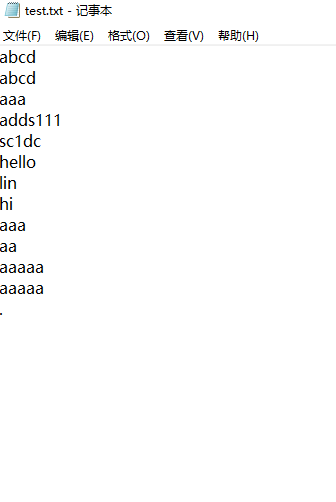
简单的单元测试:
测试一
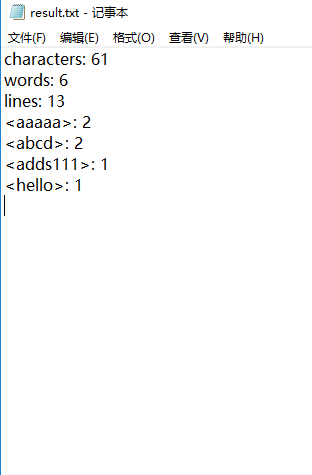
测试二

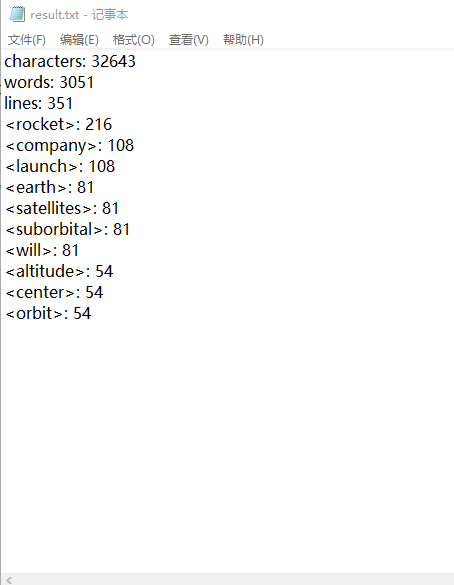
五、记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。
判断单词是否是新单词还是重复单词时所花费的时间较长,每次都从头遍历数组,但是按这个方法来做,所花费的时间是必须的,要改进只能重新换一种方法来做。
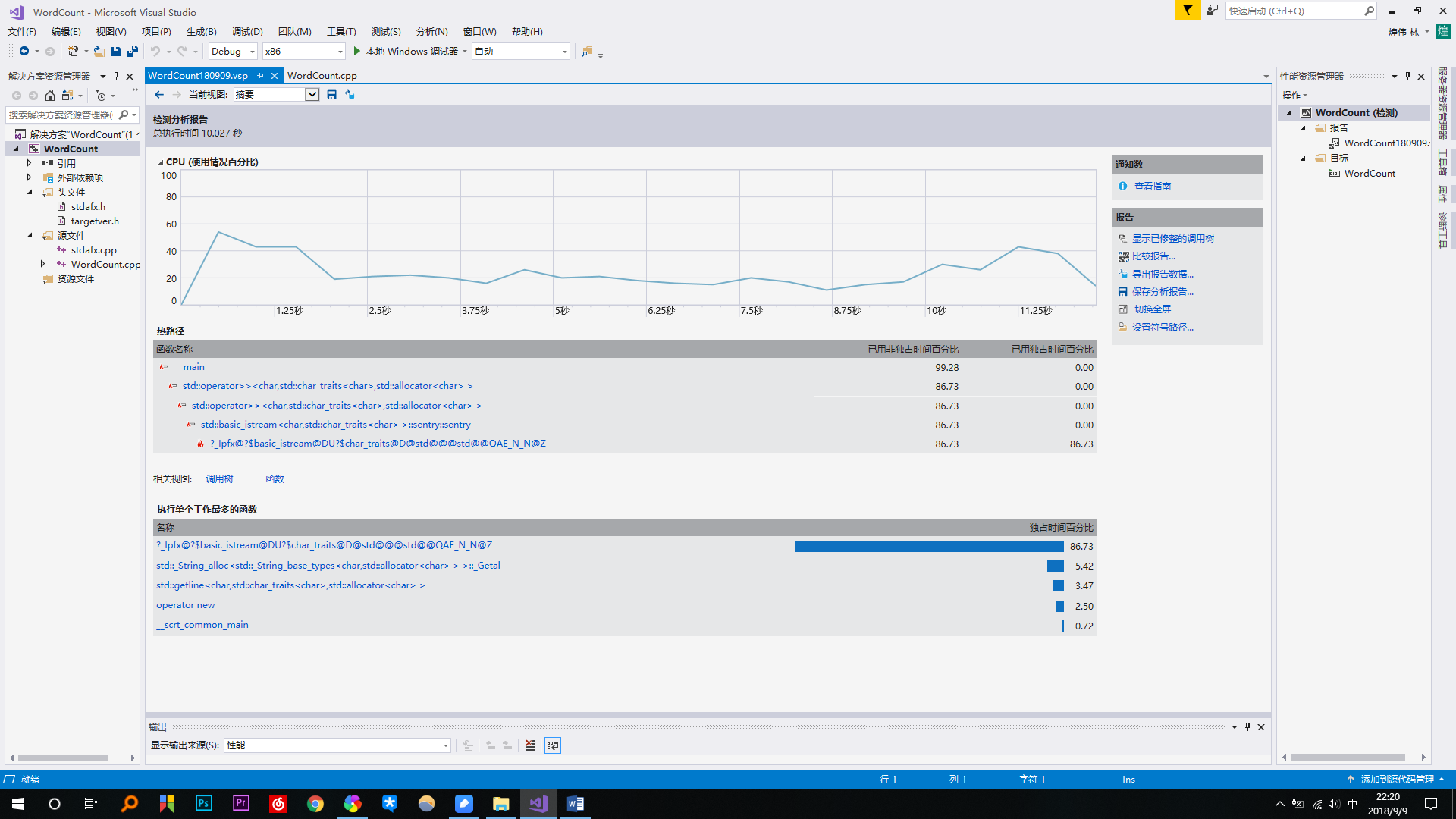
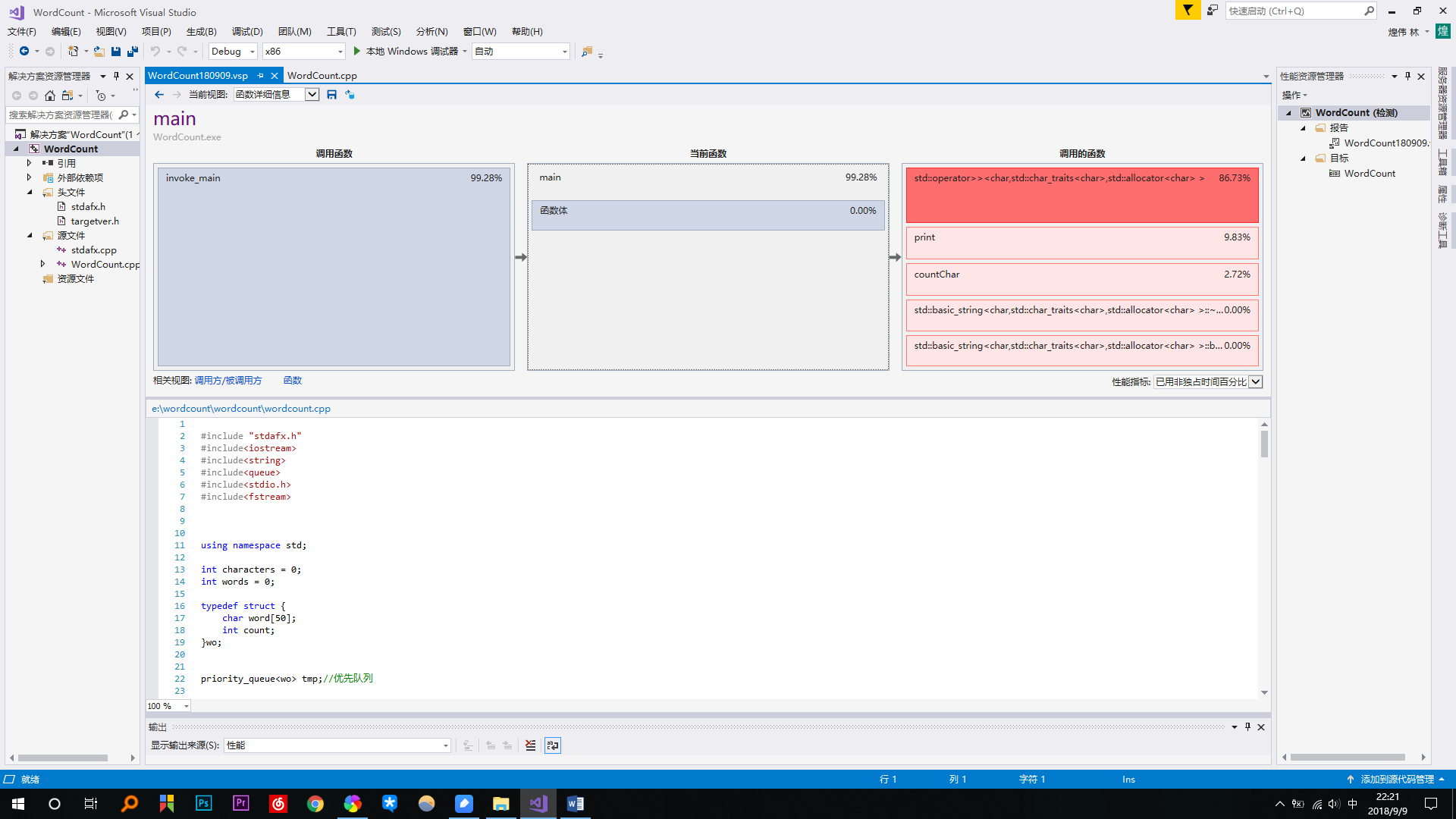
可以看到main函数占99.28%,countChar()占2.27%,print()占9.83%。占消耗最大的是优先队列的排序函数占了主要的86.37%
六、代码说明。展示出项目关键代码,并解释思路与注释说明。
- 统计行数
int countLines(string u) //统计行数
{
char ch;
int lines=0;
int flag = 0;
ifstream fin;
fin.open(u);//打开文件
if (!fin)
{
cout << "can not open file" << endl;
}
while (!fin.eof())
{
ch = fin.get();
if (ch >= 33 && ch <= 126)//表示该行是有效行
{
flag = 1;
}
if (ch == 10 && flag == 1)//当该行是有效行,并且遍历到1个换行符时,行数加1
{
lines++;
flag = 0;
}
}
if (flag == 1)//最后一行如果没有换行符,也加1
lines++;
fin.close();
return lines;
}
- 遍历文件识别单词并记录,创建结构体数组用来存每类单词和对应的个数,遍历一遍整个文档,以英文字母为开头的词语先暂时存在临时结构体中,全部读完该词语再进行判断是否符合单词规范,再跟单词结构数组对比,相同的单词数量加一,都不一样则存新的结构数组中。
int countChars(string u) //统计字符数
{
char ch;
int chars = 0;
ifstream fin;
fin.open(u);//打开文件
if (!fin)
{
cout << "can not open file" << endl;
}
while (fin.get(ch))
{
//if(ch<=255&&ch>=0)
chars++;
}
fin.close();
return chars;
}
void countWord(string u)//统计单词放在优先队列中
{
wo *danci = new wo[9999999];//动态分配结构体数组
wo temp_danci;
int k, i, j, flag,n=0;
char ch;
ifstream fin;
fin.open(u);//打开文件
if (!fin)
{
cout << "can not open file" << endl;
}
while (!fin.eof())
{
ch = fin.get();
//判断是否为单词
if ((ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z'))
{
k = 0;
flag = 0;
temp_danci.count = 1;
while ((ch >= 'a'&&ch <= 'z') || (ch >= 'A'&&ch <= 'Z') || (ch >= '0'&&ch <= '9'))
{
if (ch >= 'A'&&ch <= 'Z')
ch += 32;
temp_danci.word[k++] = ch;
ch = fin.get();
}
temp_danci.word[k++] = '�';
for (i = 0; i < 4; i++)
{
if ((temp_danci.word[i] >= '0'&&temp_danci.word[i] <= '9') || temp_danci.word[i] == '�')
{
flag = 1;//判断是否符合单词规范
break;
}
}
if (flag == 0)
{
words++;
j = n;
for (i = 0; i<j; i++)//相同的单词个数累加
{
if (strcmp(temp_danci.word, danci[i].word) == 0)
{
danci[i].count++;
break;
}
}
if (n == 0 || i == j)//新单词生成新的空间
{
danci[n] = temp_danci;
n++;
}
}
}
else continue;
}
fin.close();
for (int i = 0; i < n; i++)
{
tmp.push(danci[i]);
}
}
- 自定义优先队列排序方式,个数多的单词优先,个数相同的,按单词字母字典排序优先。
bool operator< (wo a, wo b)//自定义排序
{
//个数相同的单词按字典排序
if (a.count == b.count)
{
int i = -1;
do {
i++;
} while (a.word[i] == b.word[i]);
return a.word[i] > b.word[i];
}
//出现频率排序
else return a.count < b.count;
}
- 输出到文件result.txt
void print(string u)//输出到文件
{
int x = 0;
ofstream outf;
outf.open("result.txt");
outf << "characters: " << countChars(u) << endl;
outf << "words: " << words << endl;
outf << "lines: " << countLines(u) << endl;
while (!tmp.empty() && x<10)//输出前十个单词
{
outf << "<" << tmp.top().word << ">: " << tmp.top().count << endl;
tmp.pop();
x++;
}
outf.close();
}
- 主函数
int main(int argc, char* argv[]) {
string url = argv[1];//文件路径
countWord(url);
print(url);
return 0;
}
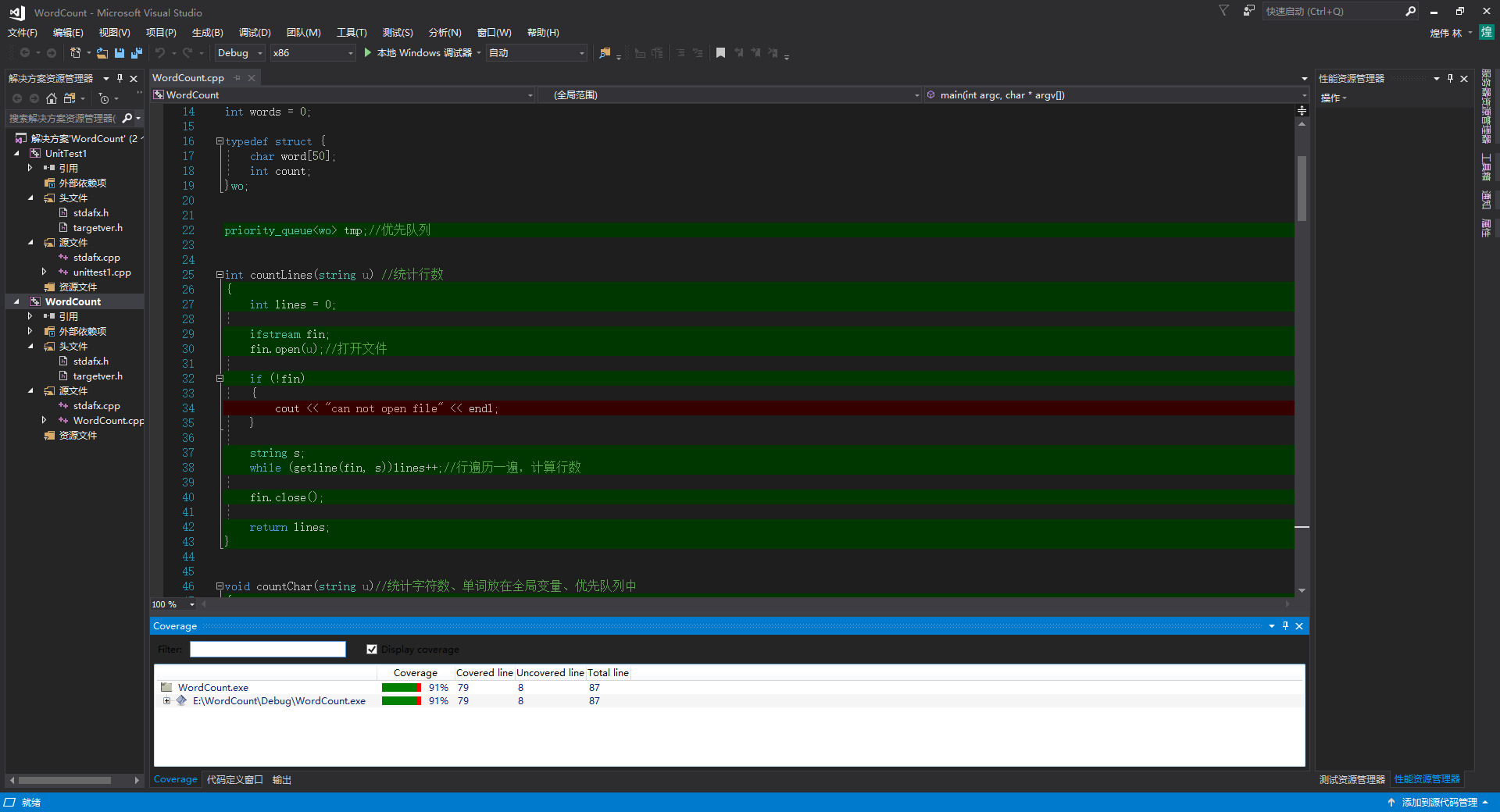
- 代码覆盖率
利用插件OpenCppCoverage,查看代码覆盖率
- 异常处理
输入一个不存在的文件,返回打开文件失败

七、解决项目的心路历程与收获。
刚开始看到题目要求时,心情十分复杂,很多专业名词都看不懂,要求不知道怎么实现,边查边读懂题目要求后,才明白了自己哪里不会,需要学什么,首先学了怎么C++读写一个txt文件,然后将读取的内容转换成之前c语言做过的字符串处理的题目,来编写代码实现相应的功能,再将函数封装优化。也学习了GitHub的使用,了解了《构建之法》中讲的一个项目从需求分析到开发的具体流程,所花时间的PSP记录,单元测试,异常处理等步骤。由于做的比较仓促,项目中还有很多不足,如接口封装没有做好,要学习的还有很多,好好努力吧!