几种虚拟机镜像格式
从用户角度看,虚拟机镜像文件是一个安装有操作系统 的磁盘分区,客户操作系统需要经过一个驱动层才能访问到 .目前,有多种虚拟机镜像格式可供选择,包括raw,qcow2、vmdk、vdi、vhd、qed以及fvd等。表1列出了常 用的虚拟机及其支持的镜像格式。


虚拟机镜像文件及其访问方式
虚拟机镜像文件保存了虚拟机硬盘的全部信息,按照数据存储方式的不同,可以分为两种模式:全镜像模式(Flat Mode)和稀疏模式(SparseMode)。
全镜像模式保存了虚拟硬 盘中的所有字节数据,其中也包括对用户而言无效的数据; raw格式就是全镜像模式。
稀疏模式只保存对用户和文件系 统有效的数据,只占用必要的存储空间,这种模式的镜像文件在存放数据时使用的可能不是连续的物理磁盘空间;前文提到的qcow2、qed、vmdk等都是稀疏模式。
在整个虚拟机的体系中,I/O请求的处理过程大致如下:
当VM的客户操作系统中的用户有磁盘I/O请求的时候,VMM(VMMonitor或者称为hypervisor)会捕获其I/O指令,根 据虚拟机实现策略的不同进行必要的转换,最终通过宿主机 操作系统内核的系统调用来完成客户操作系统的I/O请求。
在Xen中,有一个tapdisk进程运行在Dom0中,来负责处理来 自其他DomU的I/O请求,完成地址转换过程。例如,虚拟机客户操作系统需要读或写一个磁盘块,VMM会调用宿主机内核的系统调用,定位到在镜像文件中的相应的文件块。在这 个过程中,由于虚拟化的原因,客户虚拟机的块地址需要经过 若干次的转换才能找到它在物理磁盘上的准确位置。在客户操作系统中,使用的是VBA(VirtualBlockAddress),在VMM 中使用的是IBA(ImageBlockAddress),就是镜像文件内的一 个偏移量,在宿主机内核的系统调用中使用的是PBA (PhysicalBlockAddress)。在定位到这些块的物理地址后,才 能进行客户操作系统所需要的各种操作。在全镜像模式中, 这种地址转换的过程相对简单,只需要一个线性的变换;而在 稀疏模式中,往往需要经过两次以上的地址变换,才能完成 VBA到PBA的转换过程。
几种虚拟机镜像格式的原理
raw
raw就是原始的,它直接将文件系统的存储单元分配给 虚拟机使用,采取直读直写的策略。在raw格式的文件中,虚 拟出来的磁盘数据块号的大小决定了该数据块在raw文件中 的偏移量,也就是说虚拟磁盘存放数据的顺序和raw文件中 存放数据的顺序是一致的,由于这个特性,VBA到IBA的转 换比较简单,而IBA实际上就是PBA。在很多的实际应用中, 模板镜像采用raw格式,以提高模板镜像的读性能,而增量镜 像则使用其他格式,方便支持其他辅助特性。
raw格式的优点有:一是寻址简单,访问效率较高;二是 可以通过格式转换工具方便地转换为其他格式;三是可以方 便地被宿主机挂载,可以在不启动虚拟机的情况下和宿主机 进行数据传输。但是,由于raw格式实现简单,不支持诸如压 缩、快照、加密和CoW等特性,另外,raw格式文件在创建时指 定大小之后,就占用了宿主机指定大小的空间,而不像qcow2 等稀疏模式的镜像格式可以从很小的文件按需地增长。
qcow2和qed
qcow2是qcow的一种改进,是Qemu实现的一种虚拟 机镜像格式。qcow2文件存储数据的基本单元是cluster,每一 个cluster由若干个数据扇区组成,每个数据扇区的大小是 512字节。在qcow2中,要定位镜像文件的cluster,需要经过两 次地址查询操作,类似于主存二级页表转换机制,如图2

客户操作系统的VBA,可以记为d,d=(d1,d2,d3),通过 d1所指示的L1表项的内容,找到L2表的位置A,再由d2指 示的L2表项的内容找到数据块的地址B,d3则指示数据块B 内的偏移量。在qcow2文件创建初始的时候,文件只有L1表 和文件头,L1表初始为空,当VM提供一个VBA需要写操作 的时候,qcow2的底层驱动会检查d1所指示的L1表项是否 为空,如果为空,就会在文件尾部新建一个L2表,并且把d1 所指示的L1表项赋值为L2表的地址,同理,也可以定位第一 次写数据块的地址和d2所指示的L2表项的值。当VM有读 数据操作的时候,qcow2驱动会首先确定该数据块是否在镜 像文件中,如果不在镜像文件中,则会从模板镜像中读取。在 qcow2中,数据块的IBA取决于第一次写操作,文件大小也会 随着写操作的增加而不断增长,基本上做到了用多少空间分 配多少空间,而不像raw格式一样,文件创建初始就是占用了 比较大的磁盘空间。qcow2格式不仅支持CoW,还支持快照、 压缩和加密等特性。
qed的实现是qcow2的一种改型,存储定位查询方式和 数据块大小和qcow一样不同的是,在实现Wqe将qcow的表Rt)重写标 DirtFlag来代替
vmdk
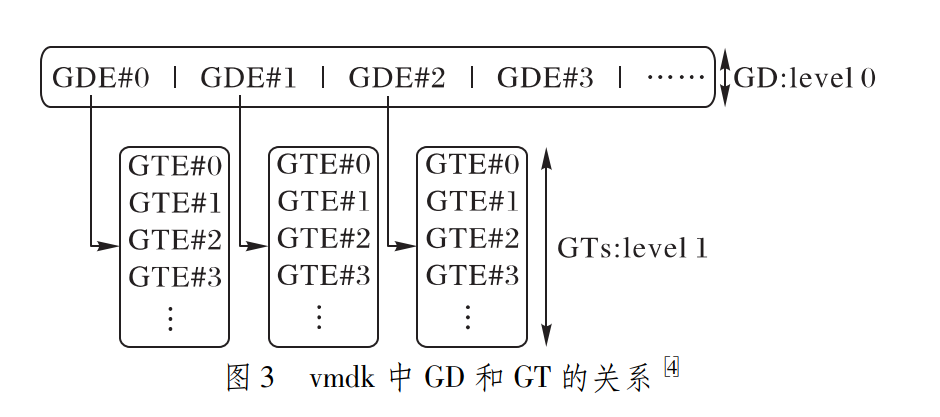
vmdk是VMware实现的虚拟机镜像格式,与qcow2类似, vmdk也可以支持CoW快照、压缩等特性,镜像文件的大小也 是随着数据写入操作的增长而增长,数据块的寻址也需要通 过两次查询。在vmdk镜像文件的头部,会有一个文本描述 符(TextDescriptor),该文本描述了数据在虚拟镜像文件中数 据的布局方式。文本描述符在vmdk镜像文件中可以以单独 的文件形式存在,也可以作为文件头包含在镜像文件中。 vmdk通常会由一个basedisk,若干个link和extent组成,link 指示的是basedisk和extent的关系,extent是一个物理上的存 储区域,通常是一个文件。vmdk数据存储的单位被叫作 grain,每个grain也由若干个512字节大小的sector组成。在 支持稀疏存储的vmdk中,通过二级的元数据查询机制进行 数据块的定位。0级元数据称为grain目录(GrainDirectory, GD),1级元数据称为grain表(GrainTable,GT),GD和GT的 关系如图3所示。在实现上,基本上和qcow2类似。
fvd
vd不仅支持上述qcow2和vmdk除了压缩以外的其他特
性,而且还支持CoR(copyonread)和预取(AdaptivePrefetching)。 fvd文件元数据的组织和实现主要基于以下三点:
1)使用位图(Bitmap)来实现CoW。位图里的一位表示
一个数据块(Block)的状态,为0时表示该数据块在模板镜像 中,为1时表示在fvd镜像中。和qcow2中的数据组织单元 cluster一样,fvd数据块的默认大小为64B。在fvd中,一个 2MB的位图可以代表1TB模板镜像数据块的状态,而这个 2MB的位图可以很方便地加载到内存中,可以大大提高CoW 的性能。在fvd中,位图也用在CoR和预取之中。
2)改变qcow2的二级查询方式,使用一级查询方式实现 存储定位。fvd把CoW和镜像文件的存储定位分开实现,在 CoW时,使用数据块是64KB,在虚拟镜像文件中存储定位 时,使用数据块(Chunk)大小为1MB。这样做的好处是大幅 度减小了查询表的大小,可以方便地将查询表一次载入内存,
减少磁盘I/O,而且一次查询就可以方便地定位到所需的数 据块。
3)对位图和一级查询表格的操作记录日志,日志满的时 候一次性提交更改,以减少对位图和查询表格的操作次数,提 高性能。由于位图和一级查询表格都可以方便地加载在内存 之中,所以对这些数据的操作比较快。在fvd中,元数据可以 和存储数据文件在一起,也可以和数据文件分开存储。fvd格 式的实现的架构如图4所示。
