此文只做安装相关的讲解
版本的话:大家可以去dockerhub去安装对应的版本:https://hub.docker.com/
-
docker pull elasticsearch:6.5.4
-
docker create --name elasticsearch --net host -e "discovery.type=single-node" -e "network.host=192.168.0.150" elasticsearch:6.5.4
-
docker start elasticsearch
-
docker logs elasticsearch (查看启动日志,一般在修改配置文件后,应该查看一下)
-
访问:ip:9200
elasticsearch-head安装
-
docker pull mobz/elasticsearch-head:5
-
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
-
docker start elasticsearch-head
-
访问:ip:9100
连接elasticsearch,需要elasticsearch服务开启允许跨域配置
进入elasticsearch容器内,修改配置文件
docker exec -it elasticsearch /bin/bash
可以看一下相关的目录,我们进入config目录,vi elasticsearch.yml,追加配置
http.cors.enabled重启elasticsearch 容器即可:docker restart elasticsearch
-
访问:ip:9100,键入elasticsearch机器的ip和端口,进行连接测试即可
数据浏览不显示的问题
-
在我们使用ElasticSearch Head的时候,在数据浏览Tab栏下并没有展现相关的数据出来,F12发现控制台报错
-
解决方法:
-
复制Head镜像内部配置文件到宿主机进行修改
docker cp elasticsearch-head:/usr/src/app/_site/vendor.js ./
-
:set nu // 显示行号
-
:6886 //跳转到6886行进行修改
-
contentType: "application/json;charset=UTF-8"
-
-
:7574 //再跳到7574行进行修改
-
var inspectData = s.contentType === "applicdocker cp vendor.js es_head:/usr/src/app/_siteation/json;charset=UTF-8" &&
-
-
:wq //保存退出,准备复制进容器内
-
docker cp vendor.js elasticsearch-head:/usr/src/app/_site/vendor.js
-
无需容器重启,刷新浏览器即可
-
受制于机器,我们就在一台机器上搭建相关环境,创建相应文件夹存放各自实例的配置文件
mkdir /ninja_data/elasticsearch_cluster/node1
mkdir /ninja_data/elasticsearch_cluster/node2
启动一个elasticsearch容器,往外复制一些必要的配置文件,其实只需要下面这两个配置文件,但我索性全部将config下的所有配置文件copy出来好了
-
elasticsearch.yml
-
jvm.options
docker cp elasticsearch:/usr/share/elasticsearch/config/ /ninja_data/elasticsearch_cluster/node1/
docker cp elasticsearch:/usr/share/elasticsearch/config/ /ninja_data/elasticsearch_cluster/node2/
然后我们分别修改node1和node2下的elasticsearch.yml如下
cluster.name: "ninja_elasticsearch-cluster" network.host: 192.168.0.150 node.name: master node.master: true node.data: true http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.0.150"] discovery.zen.minimum_master_nodes: 1 http.cors.enabled: true http.cors.allow-origin: "*"
cluster.name: "ninja_elasticsearch-cluster" network.host: 192.168.0.150 node.name: node1 node.master: false node.data: true http.port: 9201 discovery.zen.ping.unicast.hosts: ["192.168.0.150"] discovery.zen.minimum_master_nodes: 1 http.cors.enabled: true http.cors.allow-origin: "*"
分别创建node1和node2两个容器,并分别指定对应的配置文件已经数据储存目录映射
-
data目录,用于存放持久化数据,宿主机mkidr 创建之
docker create --name es-node01 --net host -v /ninja_data/elasticsearch_cluster/node1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /ninja_data/elasticsearch_cluster/node1/config/jvm.options:/usr/share/elasticsearch/config/jvm.options -v /ninja_data/elasticsearch_cluster/node1/data:/usr/share/elasticsearch/data elasticsearch:6.5.4
docker create --name es-node02 --net host -v /ninja_data/elasticsearch_cluster/node2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /ninja_data/elasticsearch_cluster/node2/config/jvm.options:/usr/share/elasticsearch/config/jvm.options -v /ninja_data/elasticsearch_cluster/node2/data:/usr/share/elasticsearch/data elasticsearch:6.5.4
一些常见启动错误
-
权限不足
docker start es-node01 && docker logs -f es-node01:启动容器报错权限不足分析
首先来看一下异常:java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes
ES启动是不允许root用户启动的,我们用的是容器技术,所以容器会创建一个用户,当ES往/usr/share/elasticsearch/data/nodes写数据的时候,该目录已经被我挂载到了/ninja_data/elasticsearch_cluster/node1/data,而你可以看看,这个data目录的权限是root,所以容器内的用户无法操作该目录,爆出权限不足异常
暴力一点: chmod -R 777 /ninja_data/elasticsearch_cluster/
这样,另一个节点就懒得去修改了,将整个目录开放
-
虚拟内存不足
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
我们将虚拟内存调大两种方式
重启失效:sysctl -w vm.max_map_count=262144
配置永久:/etc/sysctl.conf 追加一行:vm.max_map_count=262144
-
集群通信不成功
这个就是防火墙没关,大家一定要记得在测试环境把防火墙给干掉,生产环境还是需要啥端口开啥端口吧,记下命令吧
systemctl status firewalld //查看防火墙状态
systemctl stop firewalld //重启失效关闭防火墙
systemctl disable firewalld //永久关闭防火墙 ()
systemctl enable firewalld //重启防火墙
核心概念理解
索引:index
有点类似与关系型数据库的中的”表“,他是我们储存数据和索引关联数据的地方,可以这么理解,实际上是:我们的数据和索引都储存在分片中,索引只是把一个或者多个分片进行分组的名词,就像关系型数据库中,每个表把当前数据库分组开来,各自管理一样,而我们的文档就储存在索引中
类型:type
在关系型数据库中,我们将相同数据结构的数据放到一张表中,在es中,我们用文档来表示这个相同数据结构的集合
文档:document
相当于表中的一条数据,只不过格式是Json的,可以是复杂的
映射:mapping
而在每个类型中,每个字段都有自己的映射,就像关系型数据库中,每个字段都有自己类型约束一样
-
在ES中,创建索引的时候,会指定分片和备份数,分片相当于分库,把一个库的数据分成几分,存储在分片中,对数据做横向拆分,分担压力,而备份就是备份,一个分片对应一个或者多个备份,当分片崩溃后,可以从备份中拿到备份的数据,然后一个索引创建完成
-
然后我们制定相同数据结构的数据为一个类型,就像建了一个表一样,这样类型也制定好了
-
类型中每个数据都有自己的映射,就像表中的单个字段都有自己的类型一样
-
然后我们往关系型数据库中插入一条数据,在ES中被称为document即文档
配置文件参数
首先我们对ES的解压目录做一个简单的了解:
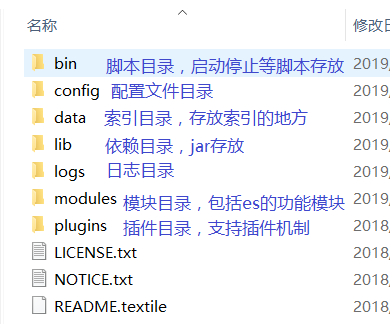
然后就是配置文件目录中的三个配置文件做一个说明:
-
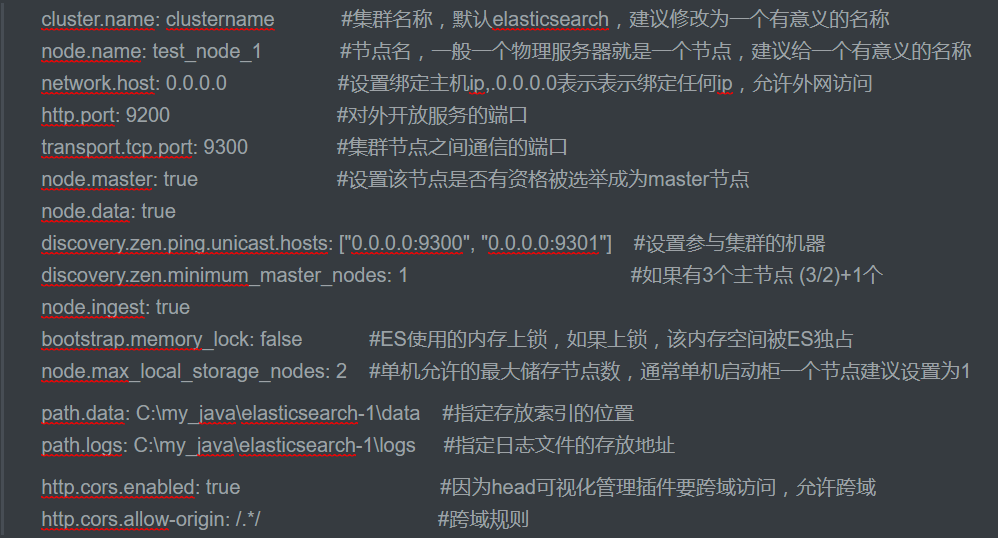
elasticsearch.yml
点击进去里面的配置全是被注释掉的,我们可以加入下面的数据作为配置
-
jvm.options
有关JVM属性的配置,一般我们就设置堆的最小最大值,一般设为相等,不能超过物理内存的一半
-Xms2g -Xmx2g
-
log4j2.properties
日志文件的配置,ES使用log4j,配置一下日志级别就OK
面向Restful的api接口
-
创建索引库
put http://localhost:9200/索引库名称

-
number_of_shards:设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力和高可用性,入门程序使用单机环境,这里设置为1。
-
number_of_replicas:设置副本的数量,设置副本是为了提高ES的高可靠性,单机环境设置为0.
-
-
-
删除索引库
delete : http://localhost:9200/索引库名称
-
{ "acknowledged": true }
-
-
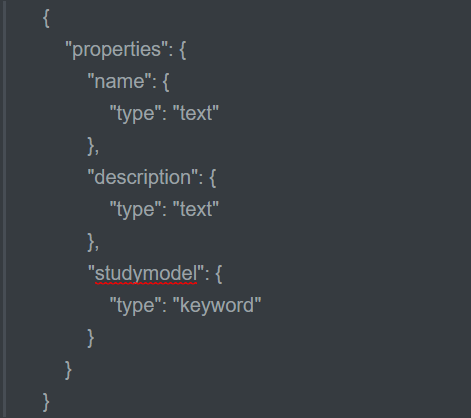
创建映射
- post http://localhost:9200/索引库名称/类型名称/_mapping
-
类型名称暂时没有意义存在,随便取一个即可,比如doc这种没有意义的
-
- post http://localhost:9200/索引库名称/类型名称/_mapping
-
插入文档
put 或Post http://localhost:9200/索引库名称/类型名称/文档id
关于最后的文档id,我们如果有设置就会使用我们自己的,若不设置,ES会自动生成

-
搜索文档
根据文档id查询:
-
get http://localhost:9200/索引库名称/类型名称/文档id
查询所有文档:
-
get http://localhost:9200/索引库名称/类型名称/_search
根据某个属性的的值插叙:
-
get http://localhost:9200/索引库名称/类型名称/_search?q=name:bootstrap
-
根据name属性的值为bootstrap进行查询,前面固定格式
-
-
查询结果参数解析
查询结果一般会有如下数据显示

IK分词器
简单上手
ES默认自带的分词器对于中文而言是单字分词,比如我爱祖国,ES会一个字一个字的分词,这样很明显不行
我们查看下面的分词效果
post:localhost:9200/_analyze
{"text":"测试分词器,我爱祖国"}
ES在之前的文件目录说明哪里也有说到,ES是支持插件机制的,我们将IK丢pligins包里就好,记得重启ES
我们手动指定使用的分词器,查看下面的分词效果
post:localhost:9200/_analyze
{"text":"测试分词器,我爱我自己","analyzer":"ik_max_word"}
然后发现好像有点复合我们国人的口味了,这里ik分词有两个模式
ik_max_word ,这个就是我们上面使用到的一个模式,划分粒度比较细,一般用于存储的时候,进行分词存储索引
ik_smart ,相对而言,这个就要粗旷一些了,一般在检索索引时,对检索条件的字段进行粗旷的分词
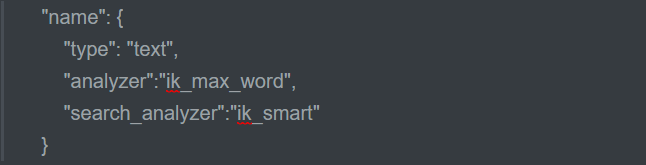
比如:下面这句话的意思就是name属性在索引和在搜索时都是用ik_max_word模式
"name": { "type": "text", "analyzer":"ik_max_word" }
再比如:索引时使用“ik_max_word”分词,搜索时使用“ik_smart”提高搜索精确性
"name": { "type": "text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart" }
自定义词库
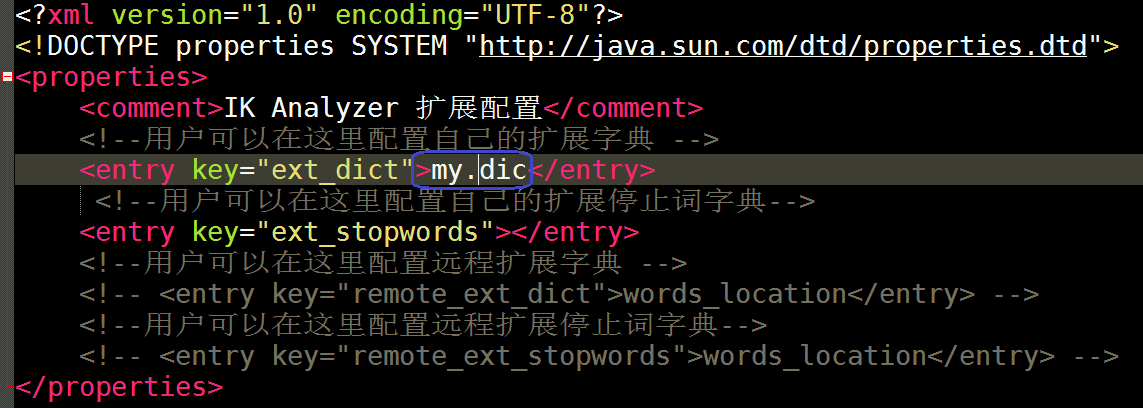
有一些特殊的领域是有一些专有的词语的,而Ik是分辨不出来,所以这里需要使用到IK的自定义词库
-
首先定义我们自己的词库:my.dic
记得保存为UTF-8格式,不然读取不到

-
然后我们再配置文件中去加载我们的自定义词库:IKAnalyzer.cfg.xml
-
然后重启ES,查看分词效果
post:localhost:9200/_analyze
{"text":"死亡野格儿","analyzer":"ik_max_word"}
映射
-
查询所有索引的映射:
-
创建映射
post :http://localhost:9200/索引库名/类型名_mapping
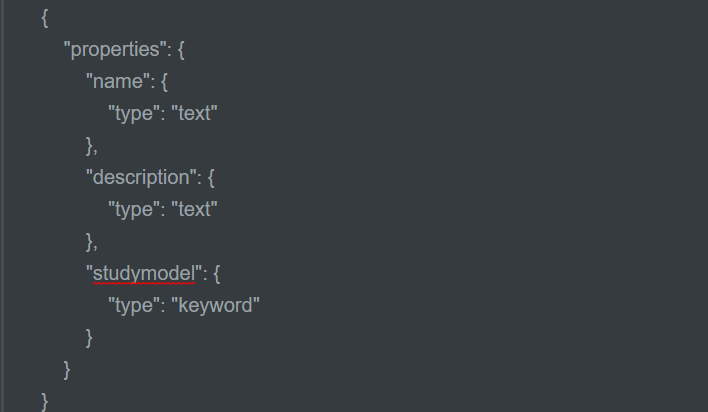
-
映射一旦创建,已有的映射是不允许更改,只能新增或者删除重建
-
删除映射也只能通过删除索引来完成
映射的类型_text
核心的字段类型:

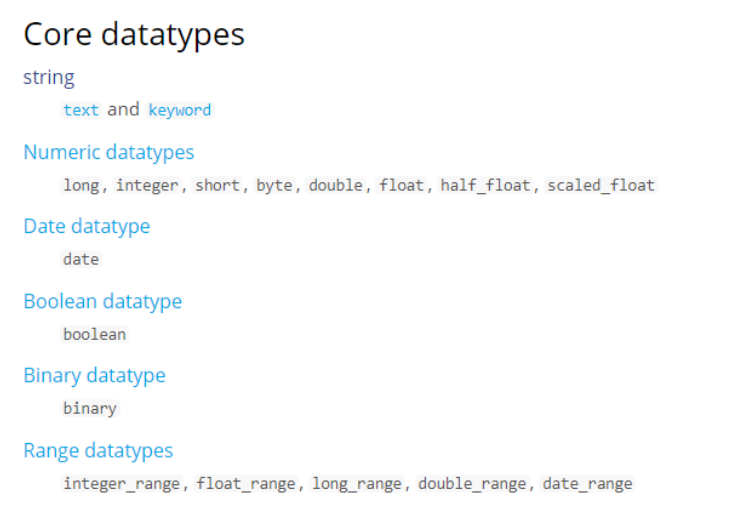
映射的类型选好了,还有一些其他的属性可以设置
analyzer :通过该属性指定分词器及模式
name属性的类型为text,在索引时使用“ik_max_word”分词器模式
在搜索时使用"ik_smart "分词器模式分词
一般都是建议在索引的时候词语最细化,在搜索时,对搜索条件粗旷化提高搜索精度
index:通过该属性指定是否索引,默认为true
只有在设置为false时,该属性的值是不会存入索引库的,也不会被检索到
比如pic属性表示的是图片的地址,一般我们不uhi把这个地址作为搜索条件进行检索,故而设置为false
store:额外存储,一般不用理会
是否在source之外存储,每个文档索引后会在 ES中保存一份原始文档,存放在"source"中,一般情况下不需要设置 store为true,因为在source中已经有一份原始文档了。

映射的类型_keyword关键字
上面我们说明了text类型的属性在映射时都可以is盒子分词器,keyword字段是一个关键字字段,通常搜索keyword是按照整体搜索的,是不会做分词,所以查询的时候是需要精确匹配的,比如邮政编码,身份证号等是不会且不应该做分词的,keywoed文本一般用于过滤,排序,聚合等场合
-
映射如下:
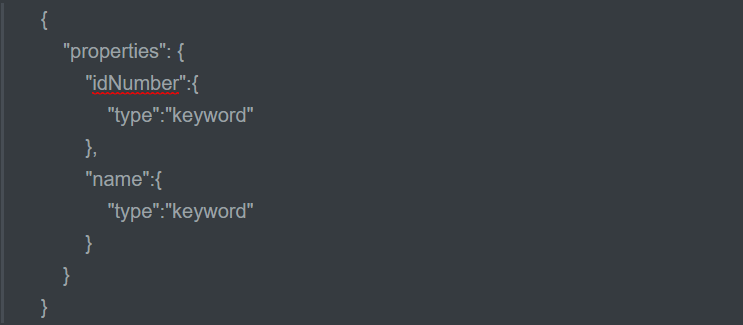
-
插入文档
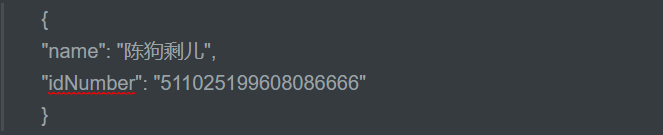
-
根据name或者身份证号查询
Get:http://localhost:9200/索引库/类型名称/_search?q=name:狗剩儿
这样是查询不到的,因为name属性是keyword类型,必须精确匹配
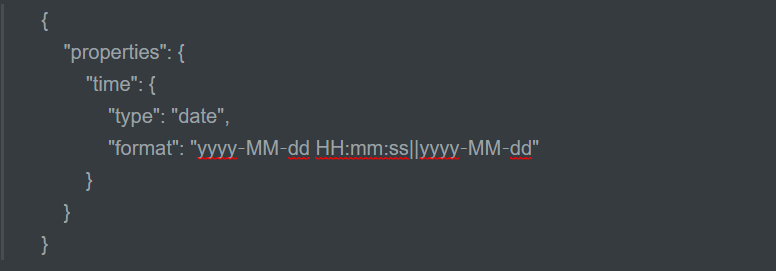
映射的类型_data日期类型
日期类型也是不用设置分词器的一种类型,一般日期类型用于排序
通过format设置日期的格式,上面的这个列子允许date字段储存年月日时分秒||年月日这两种格式
插入文档如下:Post:Post :http://localhost:9200/索引库/类型名/文档id
{ "time":"2018‐08‐15 20:28:58" }
映射的类型_数值类型


-
尽量选择范围晓得类型,提高检索效率节省空间
-
对于浮点数,尽量用比列因子,比如一个鸡蛋的单价是1.2元/个,我们将别列因子设置为100,这在ES中会按照分储存,映射如下:

因为我们将比列因子设置为100,所以储存的时候,会将1.2 * 100 进行储存
使用比列因子的好处就在与整型比浮点型更容易压缩,节约空间,当然如果比列因子不合适,我们再选范围小的去存
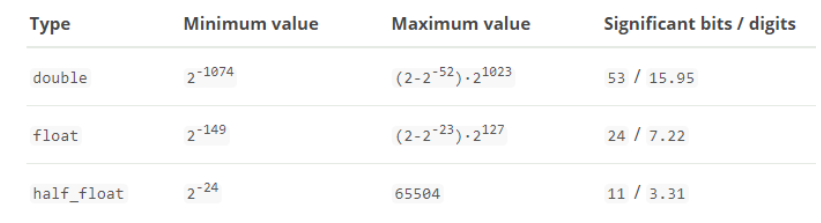
ES客户端(Java)
-
pom.xml:核心依赖
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>6.2.1</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>6.2.1</version> </dependency>
-
Spring容器注入客户端
注意这里注入两个版本的客户端一个是高版本,推荐使用的RestHighLevelClient,但功能可能不是很完善
RestClient低版本的客户端,当我们高版本的客户端不能使用时,考虑使用这个
@Configuration public class ElasticsearchConfig { @Value("${test.elasticsearch.hostlist}") private String hostlist; //获取高版本的客户端 @Bean public RestHighLevelClient restHighLevelClient(){ //解析hostlist配置信息 String[] split = hostlist.split(","); //创建HttpHost数组,其中存放es主机和端口的配置信息 HttpHost[] httpHostArray = new HttpHost[split.length]; for(int i=0;i<split.length;i++){ String item = split[i]; httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http"); } //创建RestHighLevelClient客户端 return new RestHighLevelClient(RestClient.builder(httpHostArray)); } //项目主要使用RestHighLevelClient,对于低级的客户端暂时不用 @Bean public RestClient restClient(){ //解析hostlist配置信息 String[] split = hostlist.split(","); //创建HttpHost数组,其中存放es主机和端口的配置信息 HttpHost[] httpHostArray = new HttpHost[split.length]; for(int i=0;i<split.length;i++){ String item = split[i]; httpHostArray[i] = new HttpHost(item.split(":")[0], Integer.parseInt(item.split(":")[1]), "http"); } return RestClient.builder(httpHostArray).build(); } }
创建索引库
首先注入Java客户端,我们使用第一个即可:
//高版本的客户端
@Autowired
RestHighLevelClient highClient;
//低版本的客户端
@Autowired
RestClient restClient;
//创建索引库
@Test
public void CreateIndexTest() throws IOException {
//创建索引请求对象,并设置索引名称
CreateIndexRequest createIndexRequest = new CreateIndexRequest("test_index");
//设置索引参数
createIndexRequest.settings(Settings.builder().put("number_of_shards",1)
.put("number_of_replicas",0));
//设置映射
createIndexRequest.mapping("doc"," {
" +
" "properties": {
" +
" "name": {
" +
" "type": "text",
" +
" "analyzer":"ik_max_word",
" +
" "search_analyzer":"ik_smart"
" +
" },
" +
" "description": {
" +
" "type": "text",
" +
" "analyzer":"ik_max_word",
" +
" "search_analyzer":"ik_smart"
" +
" },
" +
" "studymodel": {
" +
" "type": "keyword"
" +
" },
" +
" "price": {
" +
" "type": "float"
" +
" }
" +
" }
" +
"}", XContentType.JSON);
//创建索引操作客户端
IndicesClient indices = highClient.indices();
//创建响应对象
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest);
//得到响应结果
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
添加文档

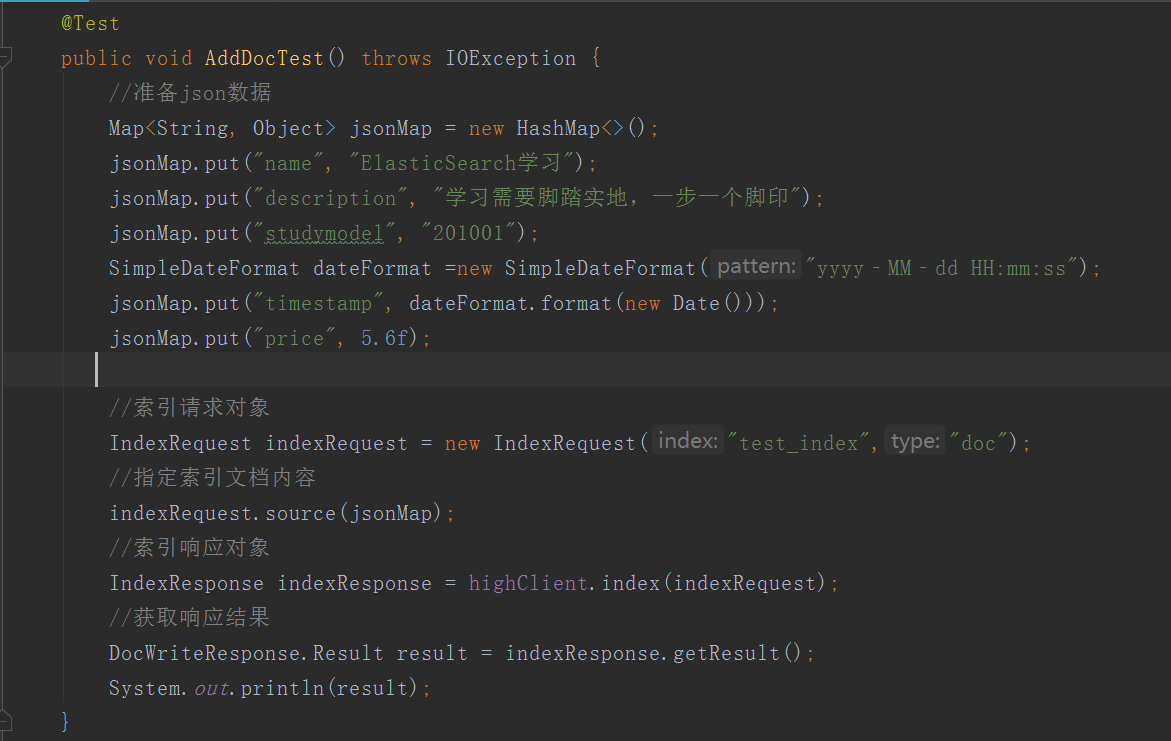
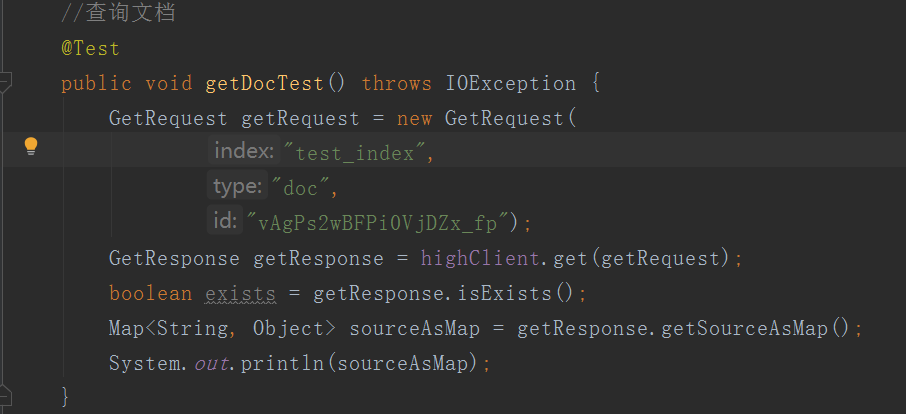
查询文档

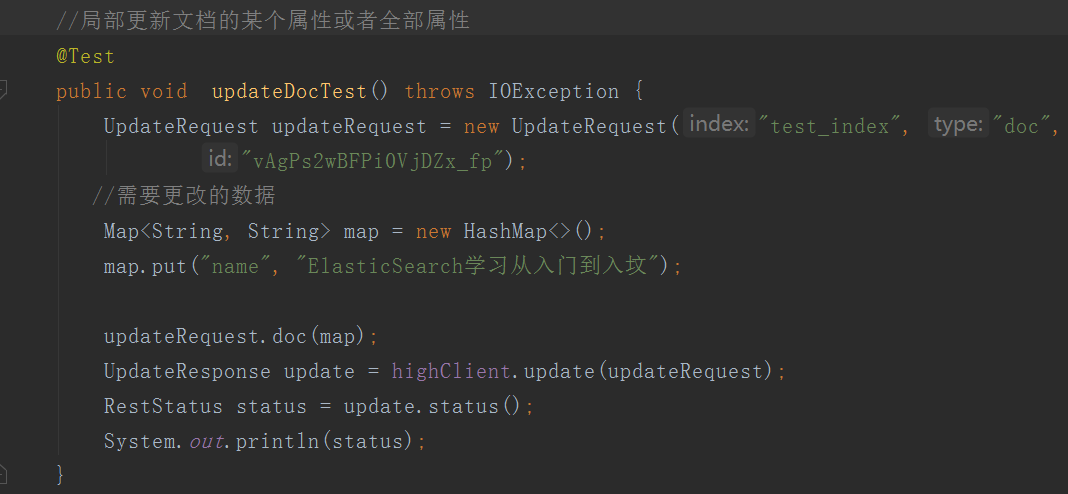
更新文档
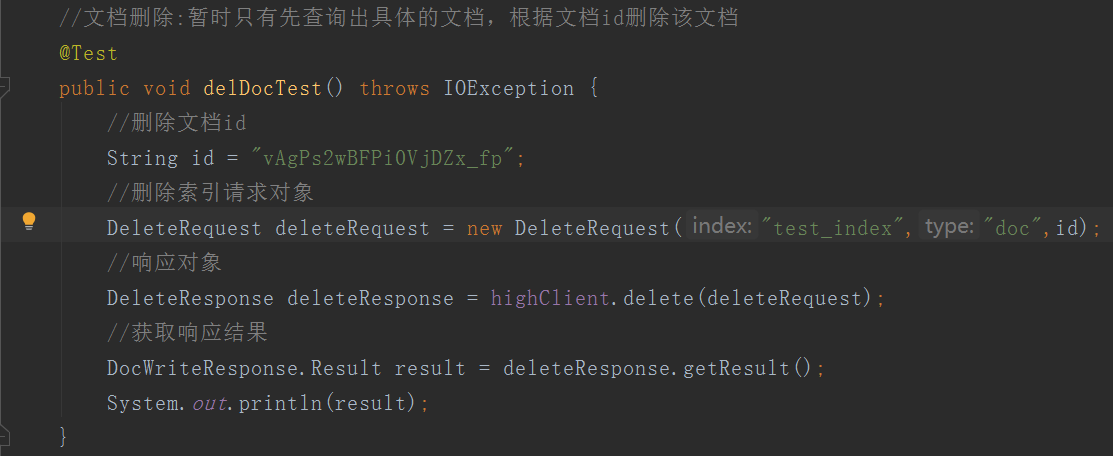
删除文档
搜索 [ 核心用法 ]
环境准备
首先我们创建一个名为“test_index”的索引库
并创建如下索引:


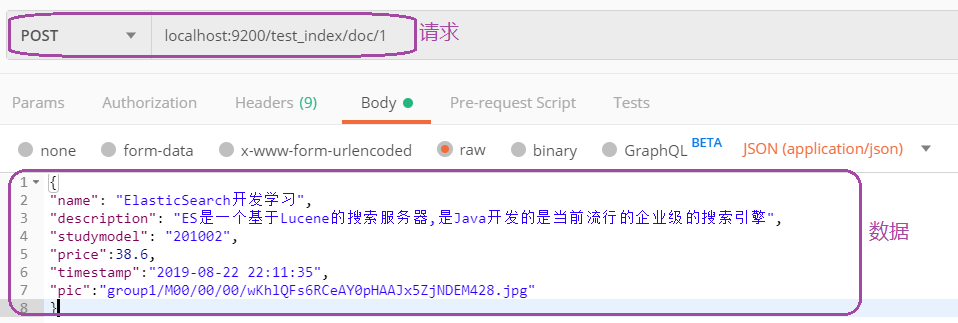
插入以下数据作为测试数据:id分别为1、2、3
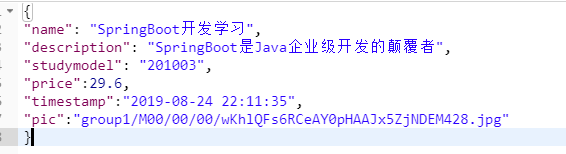


最基本的搜索我们前面意思使用过了:
-
以这样的格式: get ../_search?q=.....
DSL_搜索介绍
-
DSL:"Domain Specific Language "
-
是ES提出的基于json的搜索方式,在搜索时键入特定的json格式的数据来哇称搜索,全部POST请求
-
一般项目中都是使用的DSL搜索
DSL_查询所有文档
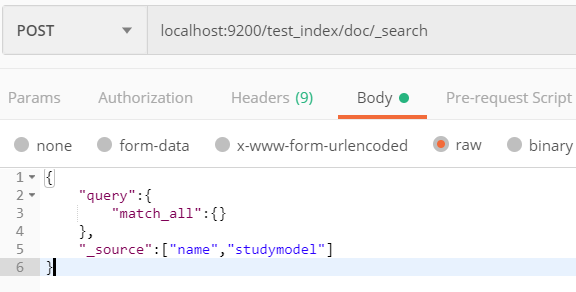
@Test public void queryAllTest() throws IOException { //创建搜索请求对象,绑定索引库和类型 SearchRequest searchRequest = new SearchRequest("test_index"); searchRequest.types("doc"); //创建:搜索源构建对象 SearchSourceBuilder builder = new SearchSourceBuilder(); //指定搜索方式:matchAllQuery builder.query(QueryBuilders.matchAllQuery()); //设置源字段过滤,第一个数组表示要包含的字段,第二个数组表示不包括的字段 builder.fetchSource(new String[]{"name","studymodel"},new String[]{}); //向搜索请求中设置搜索源 searchRequest.source(builder); //使用客户端发起搜索,获得结果 SearchResponse searchResponse = highClient.search(searchRequest); //搜索结果 SearchHits hits = searchResponse.getHits(); //从搜索结果中得到 : 匹配分高位于前面的文档 SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { Map<String, Object> map = hit.getSourceAsMap(); System.out.println(map.get("name")); System.out.println(map.get("studymodel")); } }
使用注意事项:
在我们设置源字段过滤的时候,我们只选取了着两个字段,当我们获取对结果后,也只能获取这两个字段的数据
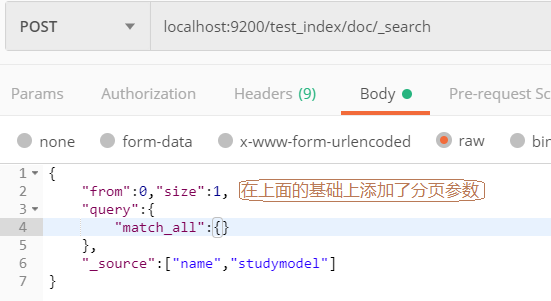
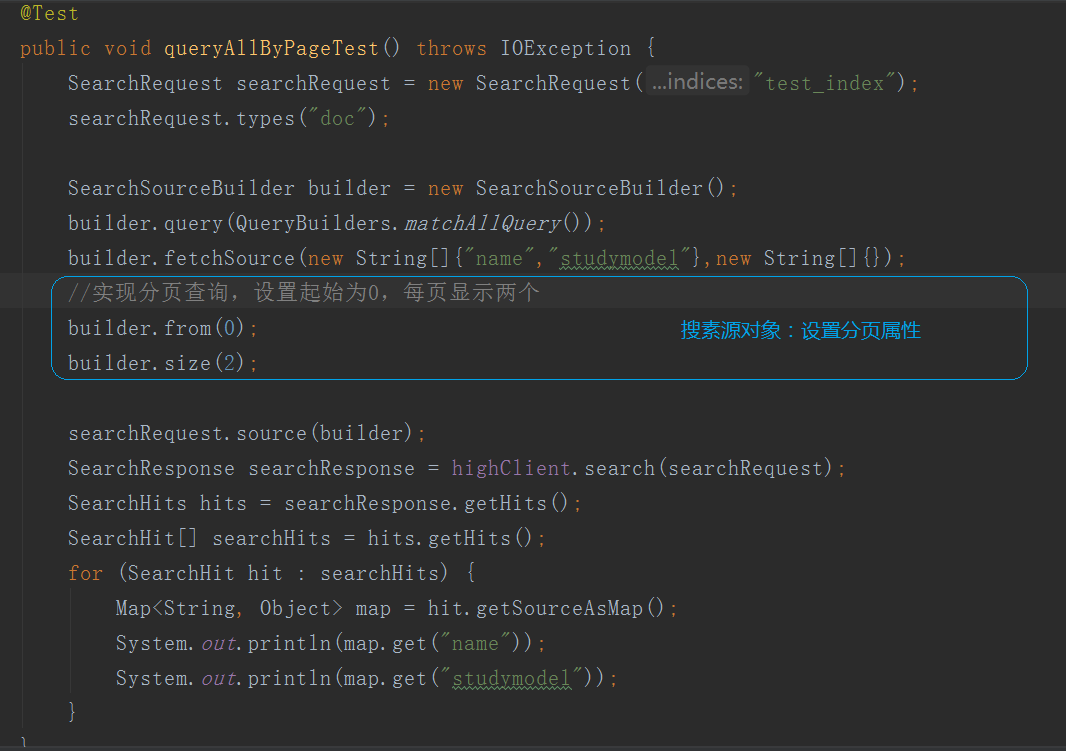
DSL_分页查询

不分词精确查询Term Query
Term Query为精确查询,在搜索时会整体匹配关键字,不再将关键字分词做搜索

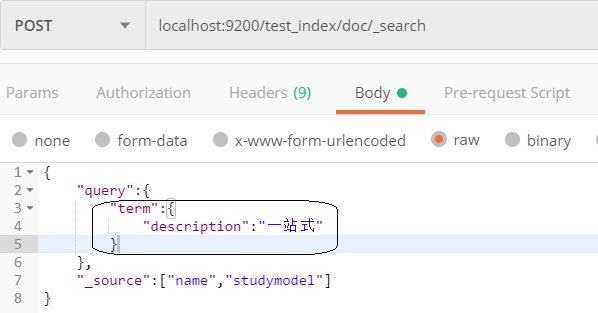


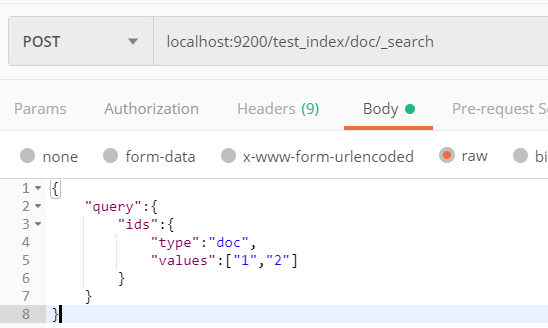
根据Id精确匹配:ids
-
请求方式:根据id 1和2精确匹配数据
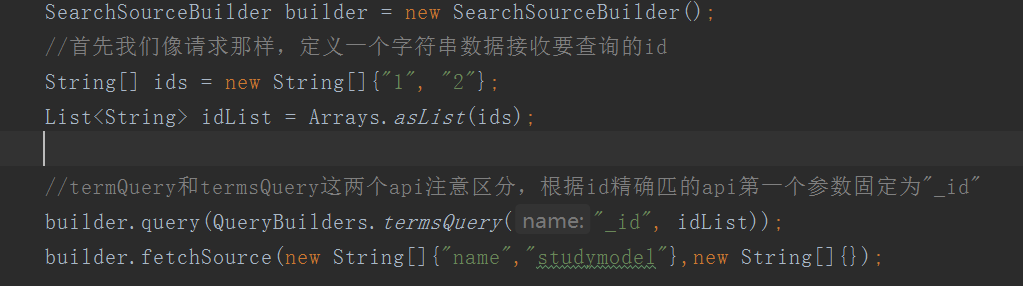
-
Java,注意事项已经在图片中给出

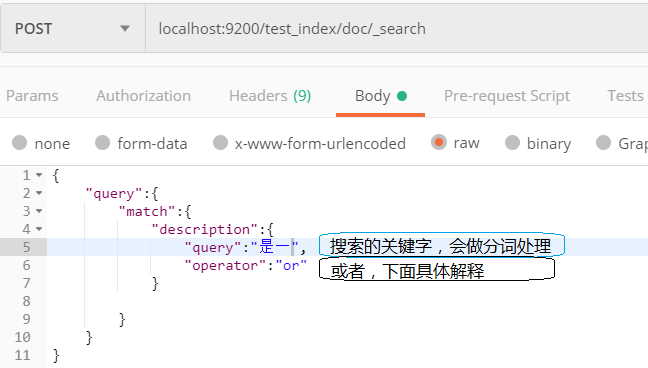
分词全文检索:match Query
match Query:全文检索,先对我们搜索的词条进行分词,然后将分好的词再拿去意义匹配查询
Term Query是不做分词,match Query是要做分词,这里做个对比,利于记忆
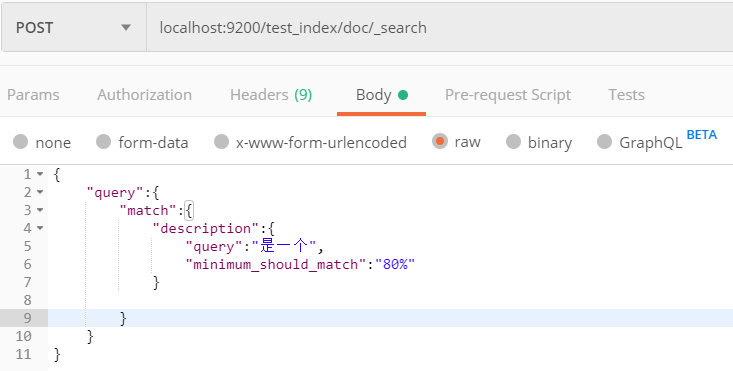
在这个请求中,query的值为我们搜索的关键词,会被分词,在这个列子中会被分为“是”、“一”两个字
operator:我们分词后出现了两个词条,只要有一个词条匹配上就命中,与之相应的还有and,表示两个或多个词条必须同时匹配上才能命中,在这里还有扩展,比如我们搜索的关键字分词后为三个字,是一个字匹配上就命中呢?还是两个字匹配上算命中呢?还是全部匹配词条匹配上才能算命中呢?ES提供了占比的方式来检索数据,见下:
minimum_should_match :关键字检索分词时,匹配文档的关键字分词词条百分比指定
"是一个"这个词再被分词时,ik会把它分为四个词,分别为:"是"、"一"、"一个"、"个";
我们设的80%,表示的意思,一共4个词条,占比8成为 4 * 80% = 3.2 取整为3,表示命中的文档必须有三个词条匹配上



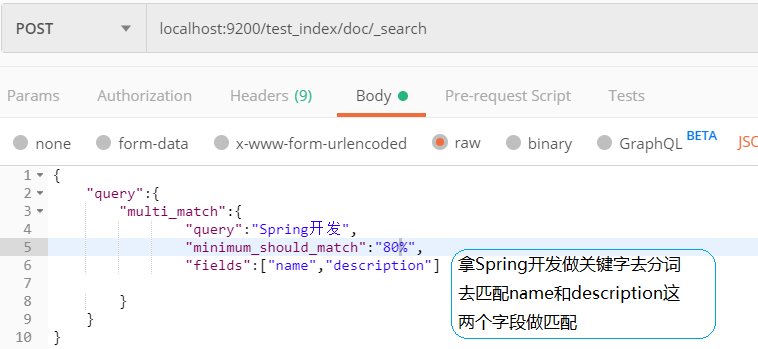
多个字段分词检索:multi Query
扩展玩法:提升权重boost
搜索关键词是"Spring开发",在我们检索该条数据的时候,一般希望的的是名字为"Spring开发",而不是描述中包含这个关键字,所以我们想提高这个关键字在搜索时,对于name字段做特殊照顾,这样就可以将name字段与Spring开发匹配上的文档得分提高,排在命中的前面




布尔查询:bool
布尔查询实现将多个查询组合起来
三个参数
-
must:文档必须匹配must所包含的查询条件
-
should:文档必须匹配should所包含的条件的一个或多个
-
must_not:文档不能匹配must_not包含的任意一个查询条件
下面这个列子自行替换关键字进行测试

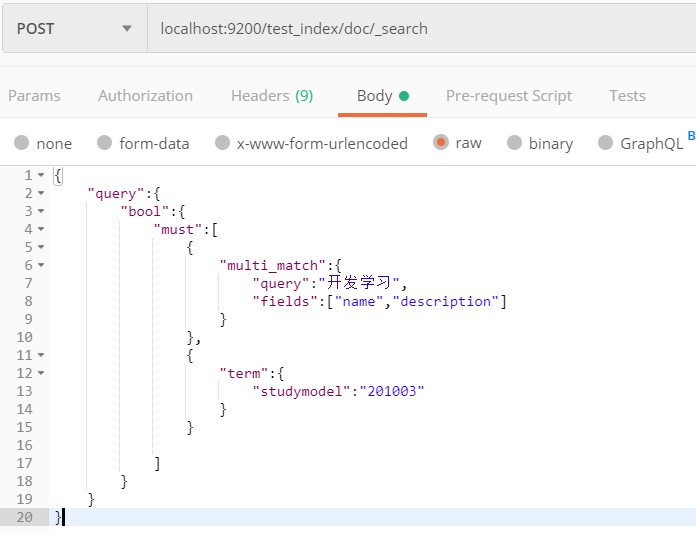
有点绕,我给圈出来了,很好看明白。
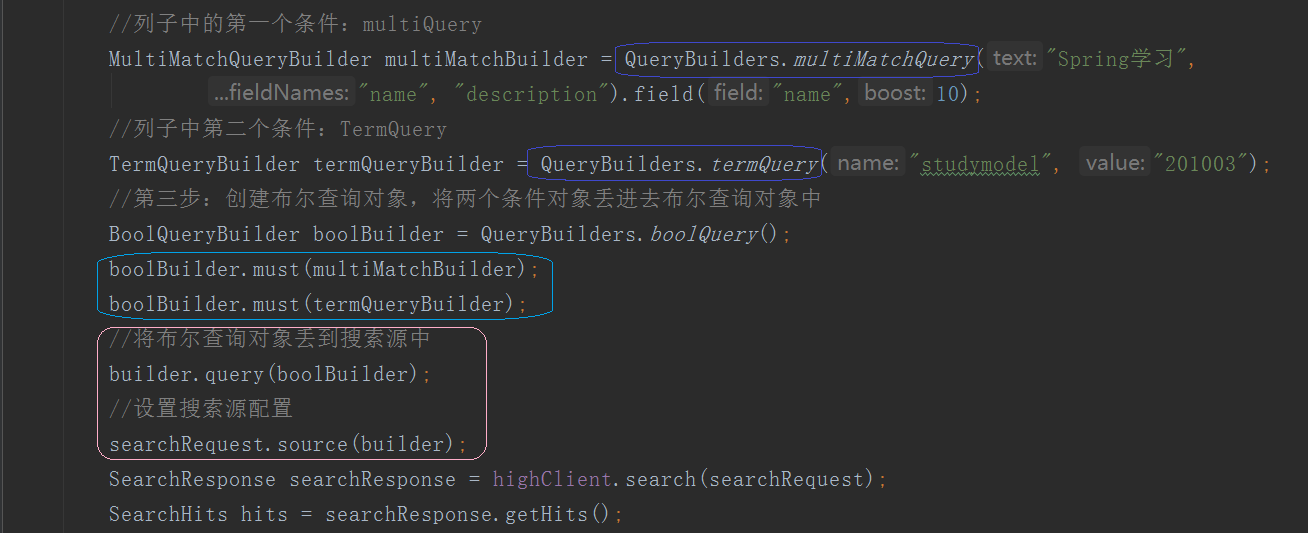
过滤器:filter
含义就很重要,需要划线要考:是针对结果进行过滤
过滤器的作用为判断该文档是否匹配,不会去计算匹配得分,性能比查询要高,缓存也方便,推荐的话:
尽量使用过滤器是显示查询或者通过过滤器 + 查询共同检索
过滤器在布尔查询中使用:
filter:过滤,term和range一次只能对一个字段进行设置过滤条件
term:项匹配过滤,留下studymodel为201004的文档
range:范围查询,价格price>60 且 <100的文档
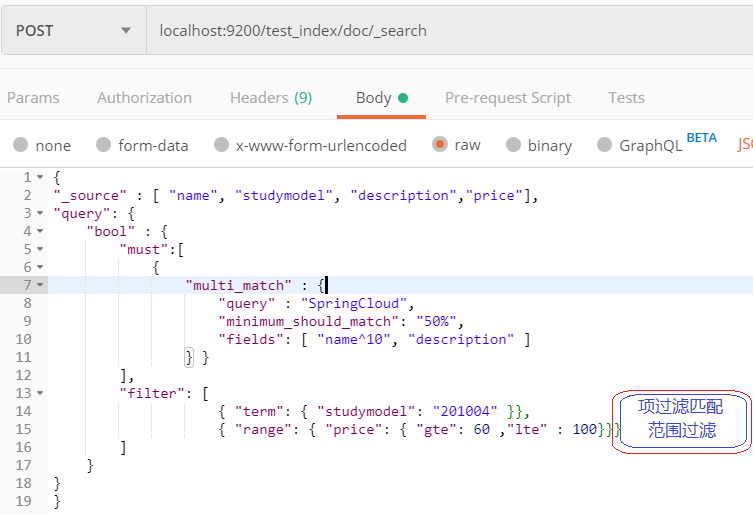


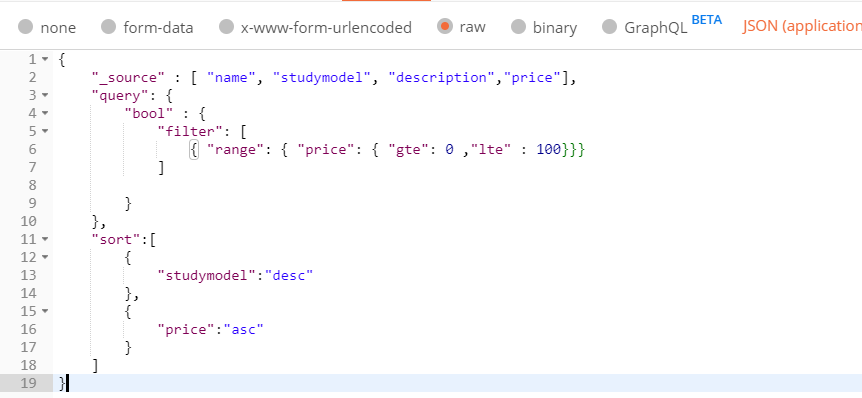
排序:sort
可以对一个字段进行设置排序,支持在keyword,date,float等类型上添加排序,text不允许排序
过滤价格在0—100区间的所有文档,优先按照studymodel降序排序,其次在根据价格升序排序


高亮显示:highlight
高亮显示可以将搜索结果一个或多个字突出显示,以便向用户展示匹配关键字的位置
在搜索语句中添加highlight即可实现,这个我把检索结果也贴出来方便查看
---------------------------------------------------------------------
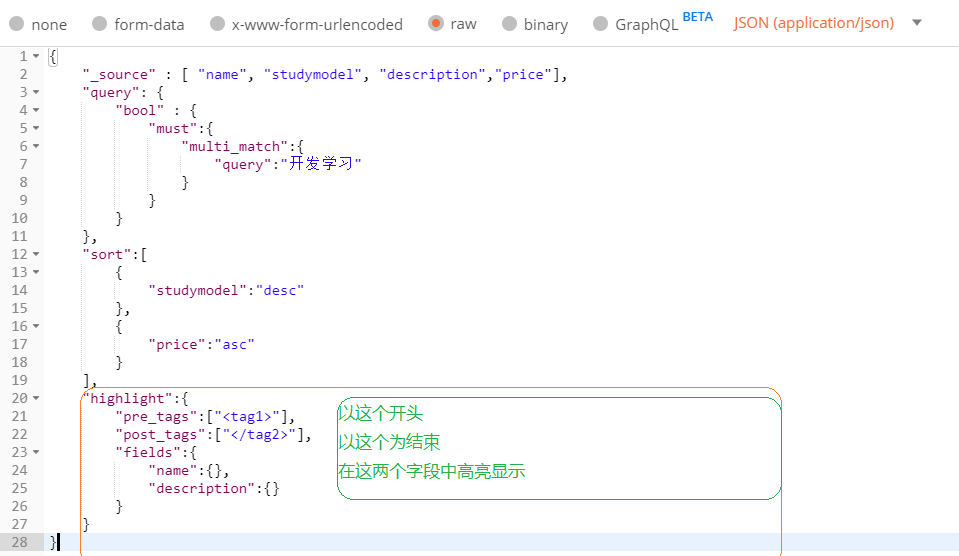

最后因为我们只获取了高亮里面的name:ElasticSearch<tag1>开发</tag2><tag1>学习</tag2>
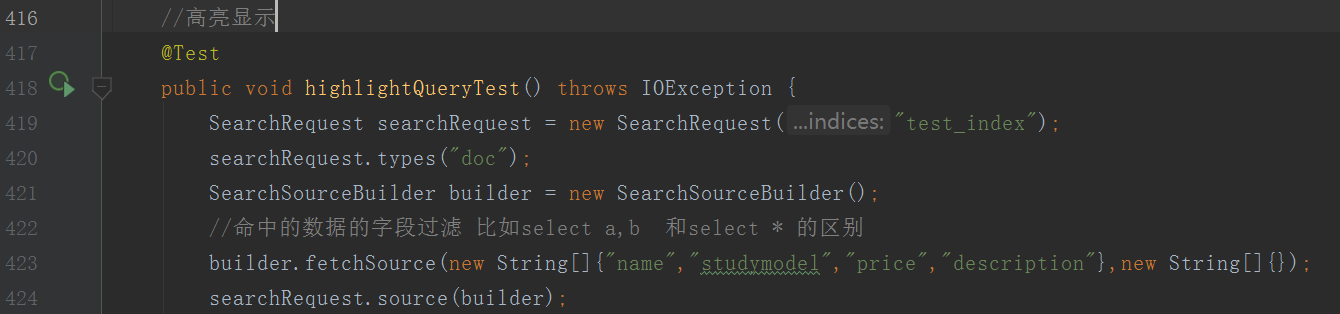

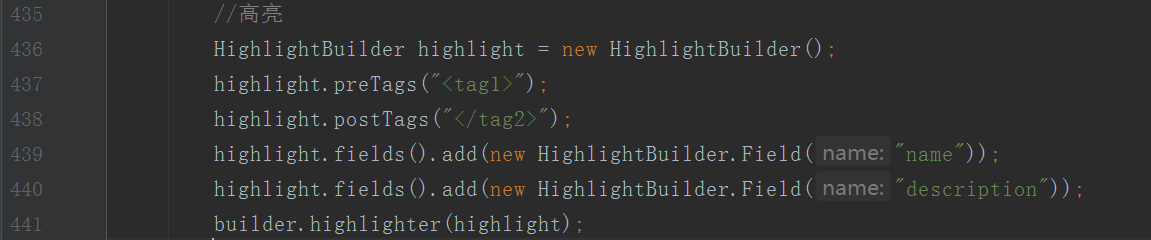
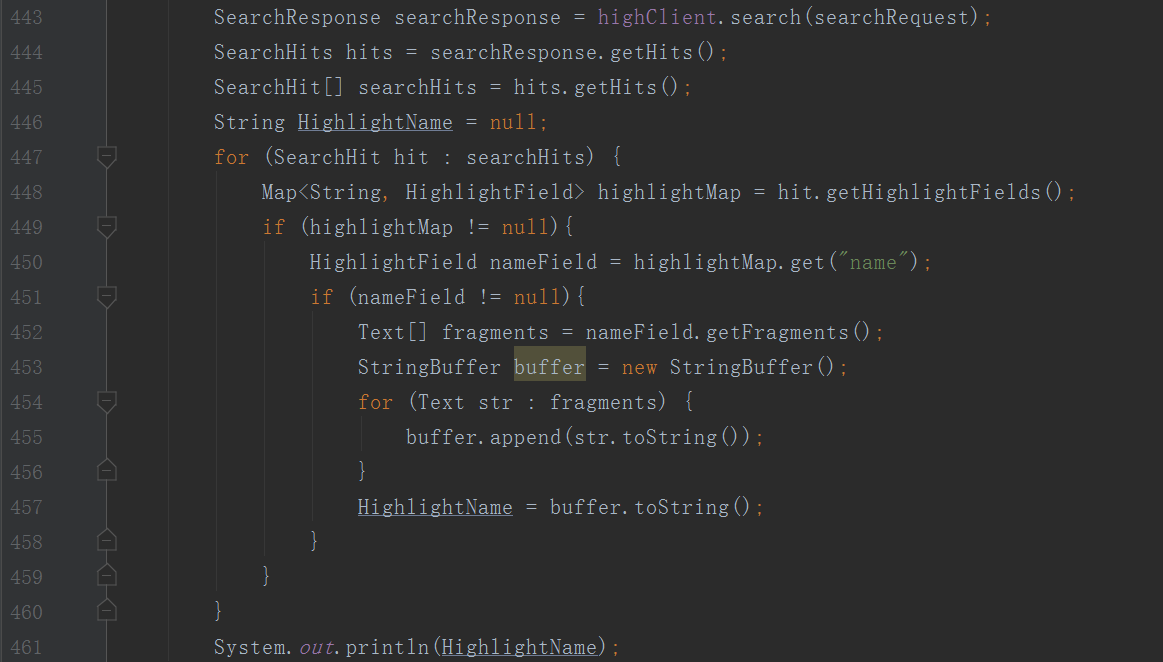
因为可读性,Json我都是截图的的方式展示的,索性代码也是截图了,后续可能还有补充......
献上Es相关的资源:https://pan.baidu.com/s/10LZyR2jX2WAnEsLibHLAfA 提取码:yc90