1. 首先安装Scala插件,File->Settings->Plugins,搜索出Scla插件,点击Install安装;
2. File->New Project->maven,新建一个Maven项目,填写GroupId和ArtifactId;
3. 编辑pom.xml文件,添加项目所需要的依赖:
<properties> <scala.version>2.10.5</scala.version> <hadoop.version>2.6.5</hadoop.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.10</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies>
4. File->Project Structure->Libraries,选择和Spark运行环境一致的Scala版本:
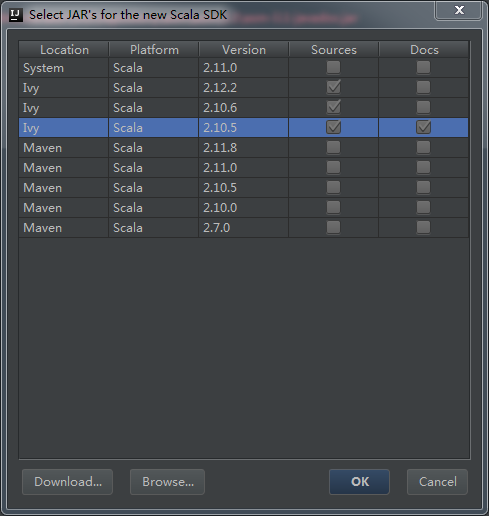
5. File->Project Structure->Modules,在src/main/下面增加一个scala文件夹,并且设置成source文件夹;
6. 在scala文件夹下面新建一个scala文件SparkPi:
import scala.math.random
import org.apache.spark._
object SparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").setMaster("spark://master:7077").setJars(Seq("E:\Intellij\Projects\SparkExample\SparkExample.jar"))
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
println("Time:" + spark.startTime)
val n = math.min(1000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
7. File->Project Structure->Artifacts,新建一个Jar->From modules with dependencies...,选择Main Class:

设置Output directory,删掉不必要的jar:

7. Build->Build Artifacts...,生成jar,然后再运行,成功!
