Python进行KMeans聚类是比较简单的,首先需要import numpy,从sklearn.cluster中import KMeans模块:
import numpy as np from sklearn.cluster import KMeans
然后读取txt文件,获取相应的数据并转换成numpy array:
X = [] f = open('rktj4.txt') for v in f: regex = re.compile('s+') X.append([float(regex.split(v)[3]), float(regex.split(v)[6])]) X = np.array(X)
设置类的数量,并聚类:
n_clusters = 5
cls = KMeans(n_clusters).fit(X)
完整代码:
import numpy as np from sklearn.cluster import KMeans import matplotlib.pyplot as plt import re X = [] f = open('rktj4.txt') for v in f: regex = re.compile('s+') X.append([float(regex.split(v)[3]), float(regex.split(v)[6])]) X = np.array(X) n_clusters = 5 cls = KMeans(n_clusters).fit(X) cls.labels_ markers = ['^','x','o','*','+'] for i in range(n_clusters): members = cls.labels_ == i plt.scatter(X[members, 0], X[members, 1], s=60, marker=markers[i], c='b', alpha=0.5) print plt.title('') plt.show()
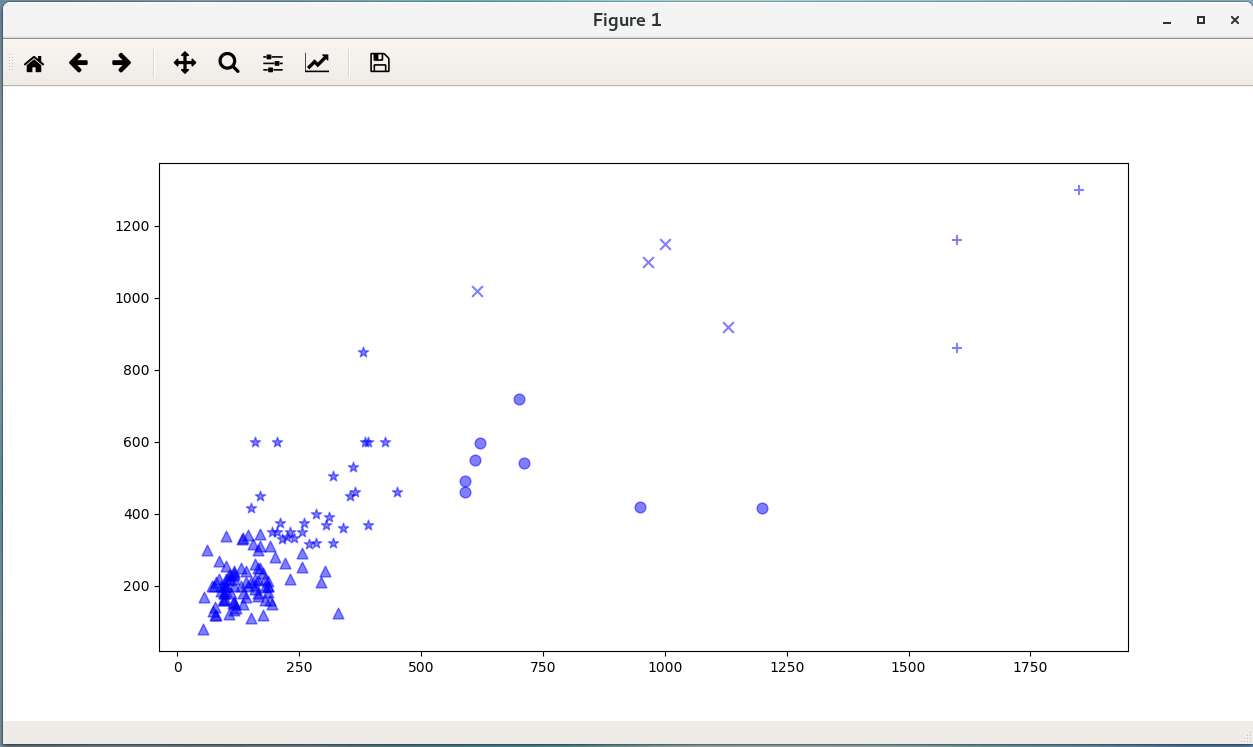
运行结果: