对CUDA架构而言,主机端的内存被分为两种,一种是可分页内存(pageable memroy)和页锁定内存(page-lock或 pinned)。可分页内存是由操作系统API malloc()在主机上分配的,页锁定内存是由CUDA函数cudaHostAlloc()在主机内存上分配的,页锁定内存的重要属性是主机的操作系统将不会对这块内存进行分页和交换操作,确保该内存始终驻留在物理内存中。
GPU知道页锁定内存的物理地址,可以通过“直接内存访问(Direct Memory Access,DMA)”技术直接在主机和GPU之间复制数据,速率更快。由于每个页锁定内存都需要分配物理内存,并且这些内存不能交换到磁盘上,所以页锁定内存比使用标准malloc()分配的可分页内存更消耗内存空间。
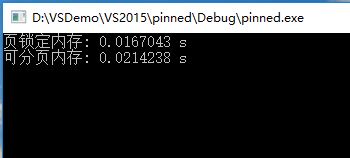
页锁定内存的内配、操作和可分页内存的对比:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "iostream"
#include <stdio.h>
using namespace std;
float cuda_host_alloc_test(int size, bool up)
{
//耗时统计
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
int *a, *dev_a;
//在主机上分配页锁定内存
cudaError_t cudaStatus = cudaHostAlloc((void **)&a, size * sizeof(*a), cudaHostAllocDefault);
if (cudaStatus != cudaSuccess)
{
printf("host alloc fail!
");
return -1;
}
//在设备上分配内存空间
cudaStatus = cudaMalloc((void **)&dev_a, size * sizeof(*dev_a));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!
");
return -1;
}
//计时开始
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
//从主机到设备复制数据
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Host to Device failed!
");
return -1;
}
//从设备到主机复制数据
cudaStatus = cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Device to Host failed!
");
return -1;
}
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaFreeHost(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return (float)elapsedTime / 1000;
}
float cuda_host_Malloc_test(int size, bool up)
{
//耗时统计
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
int *a, *dev_a;
//在主机上分配可分页内存
a = (int*)malloc(size * sizeof(*a));
//在设备上分配内存空间
cudaError_t cudaStatus = cudaMalloc((void **)&dev_a, size * sizeof(*dev_a));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!
");
return -1;
}
//计时开始
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
//从主机到设备复制数据
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Host to Device failed!
");
return -1;
}
//从设备到主机复制数据
cudaStatus = cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Device to Host failed!
");
return -1;
}
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
free(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return (float)elapsedTime / 1000;
}
int main()
{
float allocTime = cuda_host_alloc_test(100000, true);
cout << "页锁定内存: " << allocTime << " s" << endl;
float mallocTime = cuda_host_Malloc_test(100000, true);
cout << "可分页内存: " << mallocTime << " s" << endl;
getchar();
return 0;
}
对比效果,页锁定内存的访问时间约为可分页内存的访问时间的一半: