转换数据,求均值:
转换数据
步骤大概是:建立一个train文件夹,里面放一个train.txt;建立一个test文件夹,里面放一个test.txt,然后分别运行以下两条bat命令:
SET GLOG_logtostderr=1
convert_imageset.exe train/ train/train.txt convert_data_train
pause
SET GLOG_logtostderr=1
convert_imageset.exe test/ test/test.txt convert_data_test
pause
当然,也会出现错误,可能有以下几点原因:
1、路径没有设置正确;2、txt里面包含了本来没有的文件;3、如果convert_data_train和convert_data_test文件夹本来就存在,那么也会报错。
生成的数据将会保存在:convert_data_train和convert_data_test文件夹内。
求均值:
SET GLOG_logtostderr=1
compute_image_mean.exe convert_data_train image_mean.binaryproto
pause
注意文件夹是不是存在的。
微调Finetune:
由于要用caffe做人脸识别,自己刚入手又不可能配置网络,那么只有下载已经有的模型进行微调。我对微调概念的理解就是,让这个caffemodel能够更加合你的数据。
然后被小坑了一下。我下载了vgg的模型,一个caffemodel,一个deploy.prototxt,然后上网查如何进行微调,思路是:自己的train,test数据转换–>求均值–>改写deploy.prototxt文件–>撰写solver.prototxt。
前两步都还好,没有问题,在改写的时候,要先加入数据层,也就是要删掉原来的:
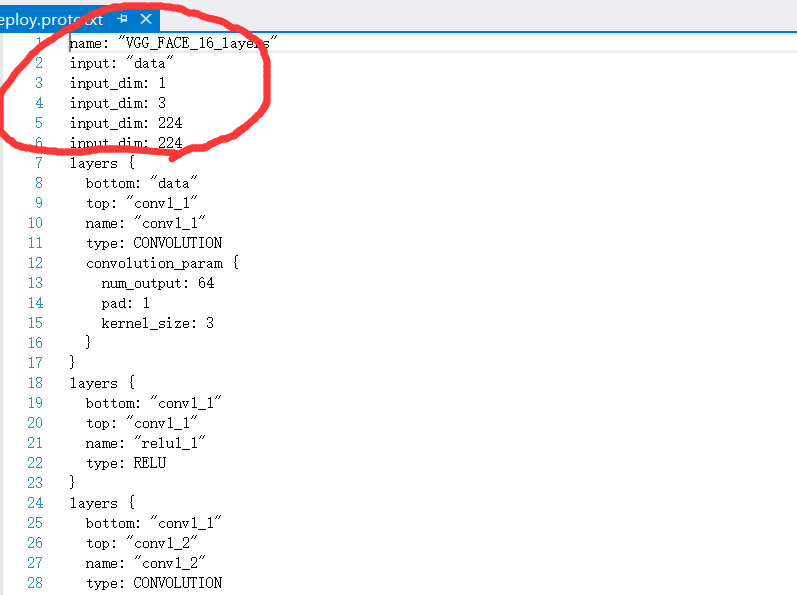
然后加入一个数据层。看网上有一个教程是这么加的:
name: "vggface_train_test.prototxt"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 224
mean_file: "vggface/face_mean.binaryproto"
}
data_param {
source: "vggface/face_train_lmdb"
batch_size: 20
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 224
mean_file: "vggface/face_mean.binaryproto"
}
data_param {
source: "vggface/face_val_lmdb"
batch_size: 20
backend: LMDB
}
}
然后我第一次运行,提示只能定义一种layer,我把上面的layer改为了layers,继续运行时,发现提示有错,由于没有什么基础弄这个,查了一下,大意是说第四行有意料之外的字符。我又看了一些其他的finetune例子,修改了以上代码:
name: "vggface_train_test.prototxt"
layer {
name: "data"
type: DATA
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 224
mean_file: "vggface/face_mean.binaryproto"
}
data_param {
source: "vggface/face_train_lmdb"
batch_size: 20
backend: LMDB
}
}
layer {
name: "data"
type: DATA
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 224
mean_file: "vggface/face_mean.binaryproto"
}
data_param {
source: "vggface/face_val_lmdb"
batch_size: 20
backend: LMDB
}
}神奇的成功了。把type后的这个改成了大写的DATA。但是原po主说他的那个在他的电脑上是对的,我也不知道怎么回事。如果有好心人看到了希望能够给我这个小白讲解一下。
这里还是给出finetune的bat命令以及solver文件:
bat:
Buildx64Debugcaffe train –solver=vggface/solver.prototxt –weights=vggface/vgg_face.caffemodel
(注意自己的路径)
solver.prototxt:
net: "vggface/vggface_train_test.prototxt"
test_iter: 500
test_interval: 500
test_initialization: false
display: 40
average_loss: 40
base_lr: 0.00005
lr_policy: "step"
stepsize: 320000
gamma: 0.96
max_iter: 1000
momentum: 0.9
weight_decay: 0.0002
snapshot: 500
snapshot_prefix: "vggface/mymodel"
solver_mode: GPU可自行修改。
fine-tune时用已经训练好的权值进行初始化,结果一般比直接训练会好很多,尤其是训练数据不多的情况下。solver文件中最重要的可能是学习率了,一般fine-tune时学习率比直接train时小一些,一般训练的学习率0.001~0.01之间,可以多试试。
提取某一层特征:
这个被大坑了一下。网上的教程大多是用extract_features.bin ,就连官方自带的教程也是extract_features.bin,我却没有找到。难道是我用的是微软的caffe导致的?(逃
然后在build文件夹里还是找到了一个好像是一样的exe文件:extract_features.exe
需要运行这个我们得准备几样东西:
1、一张图片(也可以是几张。。尺寸问题!要注意)
2、一个file_list.txt文件,而且后面要加个0(标签?不像啊)

3、一个imagenet_val文件,因为我用的网络是caffenet,而且这个东西就在extract例程的文件夹下,然后要改东西,依据自己的路径:

4、一个caffemodel,我下载了bvlc_reference_caffenet.caffemodel 。
然后就要开始了:
bat:
Buildx64Debugextract_features caffenet/bvlc_reference_caffenet.caffemodel caffenet/imagenet_val.prototxt conv5 caffenet/features 10 lmdb==========================8月11日更新===================================
调参:
网络训练参数调节,可以参考mnist或者cifar10中的demo。
调参根据经验,或者参考docs/tutorial/solver.md
需要调节的参数(solver.prototxt)主要包括:
base_lr:初始学习率,这个是非常重要的一个参数;
momentum:一般设置为0.9,如果base_lr特别低的话也可以设置为0.99或0.999等
weight_decay:默认0.005,可以适当调整,类似于正则化项;
lr_policy:学习率变化策略,常见的有fixed(固定), inv,step等
详细的说明见 http://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe
或者参考源代码src/caffe/solver.cpp中的GetLerningRate函数
常见的调参方式包括:examples/mnist中的各种方式 fixed,inv,step等,或者cifar10中的quick两步调参的方法。
主要是控制初始的学学习率,并对应的调节学习率的策略,batch size需要适当控制大小防止某一层未注册:
也就是下面的:
I0808 16:09:36.428869 12912 layer_factory.hpp:77] Creating layer data
F0808 16:09:36.428869 12912 layer_factory.hpp:81] Check failed: registry.count(type) == 1 (0 vs. 1) Unknown layer type: MemoryData (known types: )
*** Check failure stack trace: ***只要加上以下就好,适当调整。
#include "caffe/common.hpp"
#include "caffe/layers/input_layer.hpp"
#include "caffe/layers/inner_product_layer.hpp"
#include "caffe/layers/dropout_layer.hpp"
#include "caffe/layers/conv_layer.hpp"
#include "caffe/layers/relu_layer.hpp"
#include "caffe/layers/pooling_layer.hpp"
#include "caffe/layers/lrn_layer.hpp"
#include "caffe/layers/softmax_layer.hpp"
namespace caffe
{
extern INSTANTIATE_CLASS(InputLayer);
extern INSTANTIATE_CLASS(InnerProductLayer);
extern INSTANTIATE_CLASS(DropoutLayer);
extern INSTANTIATE_CLASS(ConvolutionLayer);
REGISTER_LAYER_CLASS(Convolution);
extern INSTANTIATE_CLASS(ReLULayer);
REGISTER_LAYER_CLASS(ReLU);
extern INSTANTIATE_CLASS(PoolingLayer);
REGISTER_LAYER_CLASS(Pooling);
extern INSTANTIATE_CLASS(LRNLayer);
REGISTER_LAYER_CLASS(LRN);
extern INSTANTIATE_CLASS(SoftmaxLayer);
REGISTER_LAYER_CLASS(Softmax);
}Blob:
Blob是用以存储数据的4维数组,例如
对于数据:Number*Channel*Height*Width
对于卷积权重:Output*Input*Height*Width
对于卷积偏置:Output*1*1*1
一般在提取向量时,Blob变化的是:channel。
Layer和Layers:
一定一定注意进行区分,他们的格式类型颇有不同。
Caffe层的定义由2部分组成:层属性与层参数,例如(layer)
name:"conv1"
type:CONVOLUTION
bottom:"data"
top:"conv1"
convolution_param{
num_output:<span>20
kernel_size:5
stride:1
weight_filler{
type: "<span style="color: #c0504d;">xavier</span>"
}
}这段配置文件的前4行是层属性,定义了层名称、层类型以及层连接结构(输入blob和输出blob);而后半部分是各种层参数。
2017-1-31更新
caffe中的层是根据top: “”排序的,和name无关。打个比方,你在fc7层后面接了2个fc8层,一个的top:“fc8_type”,另一个的top:”fc8_surface”,那么”fc8_surface”层是排在“fc8_type”前面的。为什么呢?
fc8_部分都是一样的,但是s的值转换为int是比t的值要小的,所以”fc8_surface”排前面。
最近在弄多loss方面的东西,注意这个细节防止数据输入错误。比如把层命名为:fc8_1_type什么的就会好很多啦。