zoukankan
html css js c++ java
TensorFlow 学习(八)—— 梯度计算(gradient computation)
maxpooling 的 max 函数关于某变量的偏导也是分段的,关于它就是 1,不关于它就是 0;
BP 是反向传播求关于参数的偏导,SGD 则是梯度更新,是优化算法;
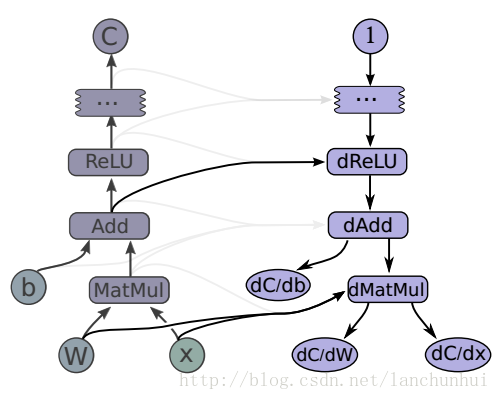
1. 一个实例
relu = tf.nn.relu(tf.matmul(x, W) + b) C = [
...
] [db, dW, dx] = tf.gradient(C, [b, w, x])
查看全文
相关阅读:
5分钟造出好记又难猜的密码!
拯救你的文档 – 【DevOps敏捷开发动手实验】开源文档发布
VSALM 动手实验
#VSTS日志# TFS 2015 Update 2 RC2新功能
用户故事驱动的敏捷开发 – 1. 规划篇
精益软件开发与精益管理:从一家关闭的汽车厂重焕青春说起
创建用户故事地图(User Story Mapping)的8个步骤
用户故事地图(User Story Mapping)之初体验
(视频) 基于HTML5的服务器远程访问工具
比较php字符串连接的效率
原文地址:https://www.cnblogs.com/mtcnn/p/9421994.html
最新文章
STL源码学习----lower_bound和upper_bound算法
CodeForces 589J Cleaner Robot
NEFU 558 迷宫寻路
NEFU 560 半数集
NEFU 561 方块计算
百练2815 城堡问题
Gym
Gym
Gym
【转载】objective-c强引用与弱引用
热门文章
单独编译和使用webrtc音频增益模块(附完整源码+测试音频文件)
VS2010版的Speex音频处理模块(附源码+测试demo)
C++模拟实现Objective-C协议和代理模式
C++模拟实现Objective-C动态类型(附源码)
单独编译和使用webrtc音频降噪模块(附完整源码+测试音频文件)
【转载】音频基础知识
STL vector容器需要警惕的一些坑
Google 打算用 QUIC 协议替代 TCP/UDP
高速网络下的http协议优化
TFS 10周年生日快乐 – TFS与布莱恩大叔的故事
Copyright © 2011-2022 走看看