Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- 对于 dropout 层,在训练时节点保留率(keep probability)为某一概率
p (0.5),在预测时(前向预测时)为 1.0;
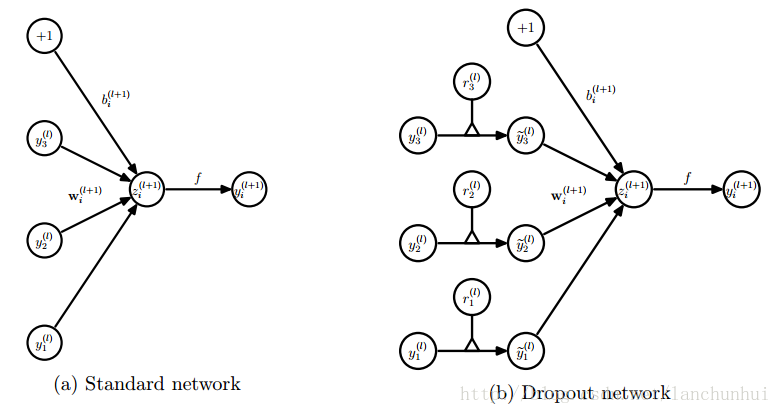
1. dropout 网络与传统网络的区别
传统网络:
z(ℓ+1)i=∑jw(ℓ+1)ij⋅y(ℓ)j+b(ℓ+1)i=w(ℓ+1)iy(ℓ)+b(ℓ+1)i y(ℓ+1)i=f(z(ℓ+1)i)
而对于 dropout 型网络:
r(ℓ)j∼Bernoulli(p) y˜(ℓ)=r(ℓ)∗y(ℓ) z(ℓ+1)i=∑jw(ℓ+1)ij⋅y˜(ℓ)j+b(ℓ+1)i=w(ℓ+1)iy˜(ℓ)+b(ℓ+1)i y(ℓ+1)i=f(z(ℓ+1)i)
由此可见 dropout 的应用应在 relu 等非线性激活函数之后,
-> CONV/FC -> BatchNorm -> ReLu(or other activation) -> Dropout -> CONV/FC ->;