- 衡量 CPU 的计算能力:
- 比如一个 Intel 的 i5-2520M @2.5 Ghz 的处理器,
则其计算能力 2.5 * 4(4核) = 10 GFLOPS
- 比如一个 Intel 的 i5-2520M @2.5 Ghz 的处理器,
- FLOP/s,Floating-point operations per second,每秒峰值速度,
- 一个 MFLOPS(megaFLOPS)等於每秒一佰万(=10^6)次的浮点运算,
- 一个 GFLOPS(gigaFLOPS)等於每秒拾亿(=10^9)次的浮点运算,
- 一个 TFLOPS(teraFLOPS)等於每秒万亿(=10^12)次的浮点运算,
- 一个 PFLOPS(petaFLOPS)等於每秒千万亿(=10^15)次的浮点运算,
- 一个 EFLOPS(exaFLOPS)等於每秒百亿亿(=10^18)次的浮点运算。
0. 初步
局部变量即内存,也即空间复杂度;当某算法对空间复杂度也要求严格时,如果仍要存储某些局部变量,比如棋盘对应的二维数组,当棋盘的大小显著时,比如
1. 量化分析
假设我们将矩阵和一个向量相乘:
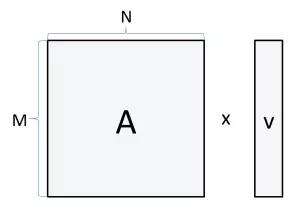
如果 M = 1024,N = 512,
那么我们需要读取和存储的字节数是:
4 bytes * (1024*512 + 512 + 1024) = 2.1e+06
计算次数是:
1024*(512+512) = 1.0e+06
如果我们有块6 TFLOP/s 的 GPU,带宽 300GB/s 的内存,那么运行总时间是:
max{2.1e6 bytes /(300e9 bytes/s),1e6 FLOPs/(6e12 FLOP/s)}=max{7μs,0.16μs}
这意味着处理过程的瓶颈在于从内存中复制或向内存中写入消耗的7μs,而且使用更快的 GPU 也不会提升速度了。你可能会猜到,在进行矩阵-矩阵操作时,当矩阵/向量变大时,这一情况会有所好转。