原博客地址:https://testerhome.com/topics/4839
背景
最近自己开发了一个小的接口,功能测完了,突然想测下性能,原来做性能测试,我一直用的是HP的LoadRunner,前一段时间正好看过locust,想想就用这个来测测性能吧。
由于对LR比较熟,正好做个对比,这样更利于对新东西的理解。
基础
locust 的官网:http://locust.io/
也可以参考论坛里其他同学的介绍:https://testerhome.com/topics/2888
目前locust还只支持Python 2版本。
测试需求
验证在相同的服务器端的情况下,使用LR和locust分别进行性能测试,在相同并发用户的情况下,验证平均响应时间,TPS值等性能测试指标的差异。
为了方便,使用http协议,一个get请求,一个post请求,交易比例为1:1。
服务器端
为了简单易理解,用Python的bottle框架写了一个服务器端,2个交易,一个get,一个post请求,交易中加了2个不同的sleep。
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'among,lifeng29@163.com'
from bottle import *
from time import sleep
app = Bottle()
@app.route('/transaction_1', method='GET')
def tr1():
sleep(0.2)
resp = dict()
resp['status'] = 0
resp['value'] = 'xxx'
return resp
@app.route('/transaction_2', method='POST')
def tr2():
parm1 = request.forms.get('parm1')
parm2 = request.forms.get('parm2')
sleep(0.5)
resp = dict()
resp['status'] = 0
resp['value'] = 'yyy'
return resp
run(app=app, server='cherrypy', host='0.0.0.0', port=7070, reloader=False, debug=False)
服务器端部署在一个单独的Windows的机器中,基于Python 3,启动后,监听7070端口。
LR中的测试脚本
在另外的一个Windows机器中,使用LR 11,用的是http/html协议的脚本,主要代码如下:
用了2个action,用于划分交易比例。
action1:
Action1()
{
lr_start_transaction("get");
web_reg_find("Text=xxx",
LAST);
web_custom_request("Head",
"URL=http://10.0.244.108:7070/transaction_1",
"Method=GET",
"Resource=0",
"Referer=",
LAST);
lr_end_transaction("get", LR_AUTO);
return 0;
}
action2:
Action2()
{
lr_start_transaction("post");
web_reg_find("Text=yyy",
LAST);
web_custom_request("Head",
"URL=http://10.0.244.108:7070/transaction_2",
"Method=POST",
"Resource=0",
"Referer=",
"Body=parm1=123&parm2=abc",
LAST);
lr_end_transaction("post", LR_AUTO);
return 0;
}
使用1:1的比例设置2个transaction的执行比例:
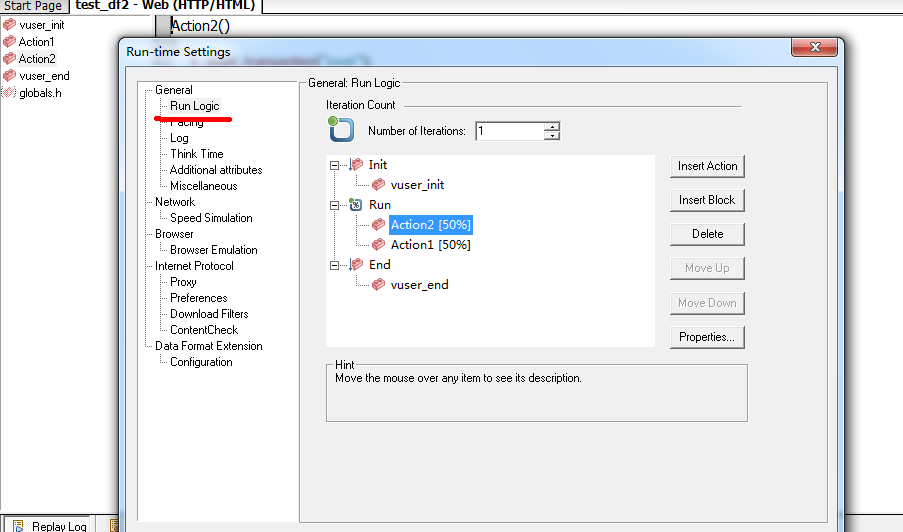
LR中的执行方法,直接放到场景中,执行即可。
locust中的测试脚本
在另外的mac中,使用locust执行测试,全部通过代码实现。代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'among,lifeng29@163.com'
from locust import *
class mytest(TaskSet):
@task(weight=1)
def transaction_1(self):
with self.client.get(name='get', url='/transaction_1', catch_response=True) as response:
if 'xxx' in response.content:
response.success()
else:
response.failure('error')
@task(weight=1)
def transaction_2(self):
dt = {
'parm1': '123',
'parm2': 'abc'
}
with self.client.post(name='post', url='/transaction_2', data=dt, catch_response=True) as response:
if 'yyy' in response.content:
response.success()
else:
response.failure('error')
class myrun(HttpLocust):
task_set = mytest
host = 'http://10.0.244.108:7070'
min_wait = 0
max_wait = 0
具体的参数可以查看官方文档。
其中:
- 主类继承HttpLocust,用于测试http协议的系统;
- min_wait和max_wait用于设置执行task过程中的等待时间,相当于LR中Pacing的设置,这里都设置为0;
- task装饰器类似于LR中的事务,可以做嵌套;
- weight相当于权重,如2个事务是1:1,保持比例一致就行;
- 这里写了2个事务,分别为get和post;对response的判断通过python的语法实现,类似于LR中的检查点。
执行方法,通过命令行启动:
如下图:

LR中的测试过程和结果
测试过程:
直接设置并发用户数和加载方式,10个用户并发,同时加载就可以了。

测试结果:
平均响应时间:

TPS:

事务:

Locust中的测试过程和结果
测试过程:
使用浏览器打开http://127.0.0.1:8089

设置需要的并发用户数和用户加载策略。
这里设置相同的10用户并发,Hatch Rate是每秒启动多少用户的意思。这里设置为10,就是同时启动10个了。注意,这里不好设置执行多久,和LR不一样。(可以不启动浏览器,直接在启动参数中设置并发用户数,执行多少个事务后结束,具体用-h可以看到帮助)
启动执行后:

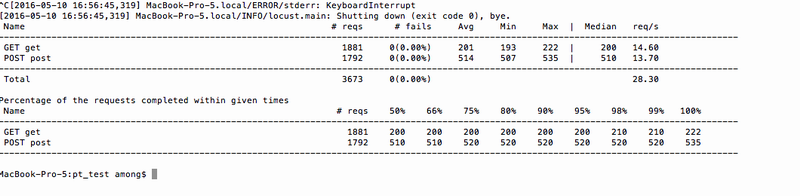
其中,Average中为平均响应时间等测试指标,最后一列的reqs/sec相当于LR中的TPS。(这里locust把它叫做rps),其他指标都比较好理解了。
最后的结果:
在web页面中可以下载原始的测试结果数据。
在停掉python命令后,在终端中也可以看到一些信息,最后的一行是百分之X的响应时间,表示百分之多少的交易在XXX响应时间内。
这里比LR中的要多点,包括了50%到100%的响应时间。
结果比较
在相同的服务器端环境,测试的结果值相似,没有多大的区别。
在设置交易比例的过程中,可以看到get和post交易的比例都存在差异。这个也无法避免(除非自己写脚本划分)。所以tps方面存在些差异。不过总体差距很小。
总结
性能测试,重点是考察并发用户数、响应时间、tps这类指标。
一直用的是LR,LR在一起概念上更易于理解,在有lr的基础上,在看其他的工具,就比较容易了。
locust也可以支持分布式执行(多执行机),用来简单测试这类http的接口,也算比较方便。
而且,locust全部基于Python脚本,扩展性不错,号称可以测试任何协议和系统。
最后,我还是那句话,看什么事情,用什么工具最高效易用,用合适的工具做合适的事情即可。
欢迎大家讨论。