前言
假如你想到某个在线约会网站寻找约会对象,那么你很可能将该约会网站的所有用户归为三类:
1. 不喜欢的
2. 有点魅力的
3. 很有魅力的
你如何决定某个用户属于上述的哪一类呢?想必你会分析用户的信息来得到结论,比如该用户 "每年获得的飞行常客里程数","玩网游所消耗的时间比","每年消耗的冰淇淋公升数"。
使用机器学习的K-近邻算法,可以帮助你在获取到用户的这三个信息后(或者更多信息 方法同理),自动帮助你对该用户进行分类,多方便呀!
本文将告诉你如何具体实现这样一个自动分类程序。
第一步:收集并准备数据
首先,请搜集一些约会数据 - 尽可能多。
然后将自行搜集到的数据存放到一个txt文件中,例如,可以将每个样本数据各为一行,
前言中提到的那三个分析数据(特征)以及分析结果(整数表示)各为一列,如下所示:
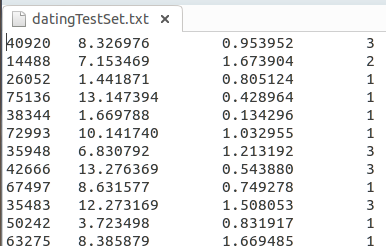
再编写函数将这些数据从文件中取出并存放到数据结构中:
1 # 导入numpy数学运算库 2 import numpy 3 4 # ============================================== 5 # 输入: 6 # 训练集文件名(含路径) 7 # 输出: 8 # 特征矩阵和标签向量 9 # ============================================== 10 def file2matrix(filename): 11 '获取训练集数据' 12 13 # 打开训练集文件 14 fr = open(filename) 15 # 获取文件行数 16 numberOfLines = len(fr.readlines()) 17 # 文件指针归0 18 fr.seek(0) 19 # 初始化特征矩阵 20 returnMat = numpy.zeros((numberOfLines,3)) 21 # 初始化标签向量 22 classLabelVector = [] 23 # 特征矩阵的行号 也即样本序号 24 index = 0 25 26 for line in fr: # 遍历训练集文件中的所有行 27 # 去掉行头行尾的换行符,制表符。 28 line = line.strip() 29 # 以制表符分割行 30 listFromLine = line.split(' ') 31 # 将该行特征部分数据存入特征矩阵 32 returnMat[index,:] = listFromLine[0:3] 33 # 将该行标签部分数据存入标签矩阵 34 classLabelVector.append(int(listFromLine[-1])) 35 # 样本序号+1 36 index += 1 37 38 return returnMat,classLabelVector
获取到数据后就可以print查看获取到的数据内容了,如下:
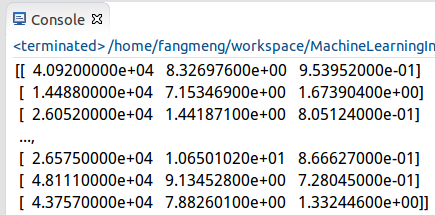
很显然,这样的显示非常的不友好,可采用Python的Matplotlib库来图像化地展示获取到的数据。
如果你是在Ubuntu下使用Eclipse插件编译PyDev的话,安装Matplotlib是很坑的。
在获取到安装包后,还得在插件设置那里添加新的库路径,因为Matplotlib不会自动安装到Python2.7的库目录下,这和NumPy不同。
下面这个才是正确的库路径:

然后就可以编写以下代码进行数据的分析了:
1 # 新建一个图对象 2 fig = plt.figure() 3 # 设置1行1列个图区域,并选择其中的第1个区域展示数据。 4 ax = fig.add_subplot(111) 5 # 以训练集第一列(玩网游所消耗的时间比)为数据分析图的行,第二列(每年消费的冰淇淋公升数)为数据分析图的列。 6 ax.scatter(datingDataMat[:,1], datingDataMat[:,2]) 7 # 展示数据分析图 8 plt.show()
另外在代码顶部记得包含所需的matplotlib库:
1 # 导入Matplotlib库 2 import matplotlib.pyplot as plt 3 import matplotlib
运行完后,输出数据分析图如下:
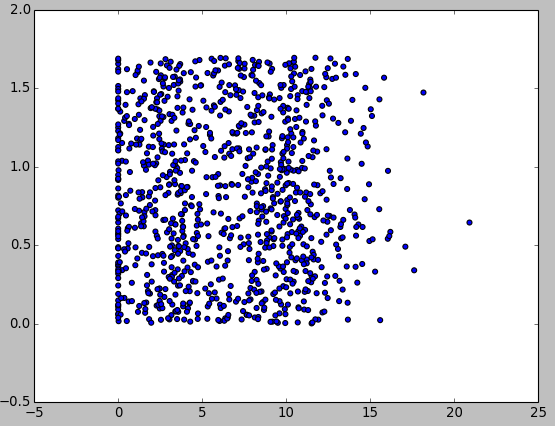
这里发现一个问题,上面的数据分析图并没有显示分类的结果。
进一步优化数据分析图显示部分代码:
1 # 新建一个图对象 2 fig = plt.figure() 3 # 设置1行1列个图区域,并选择其中的第1个区域展示数据。 4 ax = fig.add_subplot(111) 5 # 以训练集第一列(玩网游所消耗的时间比)为数据分析图的行,第二列(每周消费的冰淇淋公升数)为数据分析图的列。 6 ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*numpy.array(datingLabels), 15.0*numpy.array(datingLabels)) 7 # 坐标轴定界 8 ax.axis([-2,25,-0.2,2.0]) 9 # 坐标轴说明 (matplotlib配置中文显示有点麻烦 这里直接用英文的好了) 10 plt.xlabel('Percentage of Time Spent Playing Online Games') 11 plt.ylabel('Liters of Ice Cream Consumed Per Week') 12 # 展示数据分析图 13 plt.show()
得到如下数据分析图:
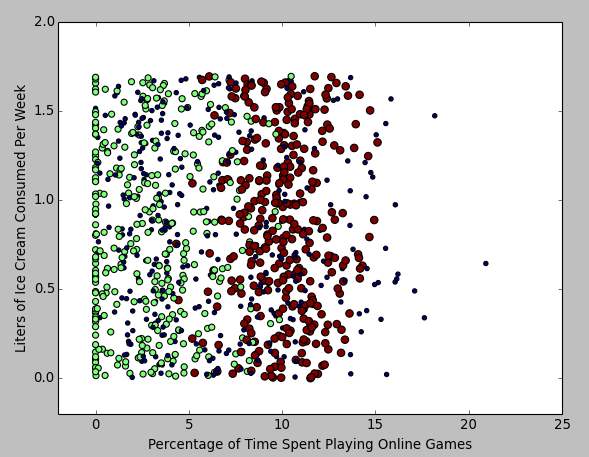
也可以用同样方法得到 "每年获得的飞行常客里程数" 和 "玩网游所消耗的时间比" 为轴的图:
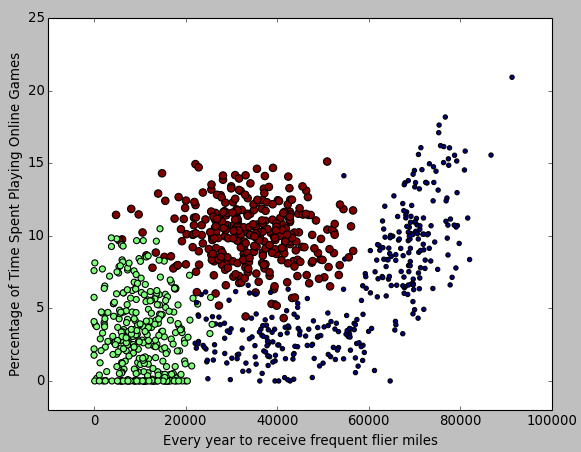
第三步:数据归一化
想必你会发现,我们分析的这三个特征,在距离计算公式中所占的权重是不同的:飞机历程肯定要比吃冰淇淋的公升数大多了。
因此,需要将它们转为同样的一个数量区间,再进行距离计算。 --- 这个步骤就叫做数据归一化。
可以使用如下公式对数据进行归一化:
newValue = (oldValue - min) / (max - min)
即用旧的特征值去减它取到的最小的值,然后再除以它的取值范围。
很显然,所有得到的新值取值均在 0 -1 。
这部分代码如下:
1 # ============================================== 2 # 输入: 3 # 训练集 4 # 输出: 5 # 归一化后的训练集 6 # ============================================== 7 def autoNorm(dataSet): 8 '数据归一化' 9 10 # 获得每列最小值 11 minVals = dataSet.min(0) 12 # 获得每列最大值 13 maxVals = dataSet.max(0) 14 # 获得每列特征的取值范围 15 ranges = maxVals - minVals 16 # 构建初始矩阵(模型同dataSet) 17 normDataSet = numpy.zeros(numpy.shape(dataSet)) 18 19 # 数据归一化矩阵运算 20 m = dataSet.shape[0] 21 normDataSet = dataSet - numpy.tile(minVals, (m,1)) 22 # 注意/是特征值相除法。/在别的函数库也许是矩阵除法的意思。 23 normDataSet = normDataSet/numpy.tile(ranges, (m,1)) 24 25 return normDataSet
第四步:测试算法
测试的策略是随机取10%的数据进行分析,再判断分类准确率如何。
这部分代码如下:
1 # ================================================ 2 # 输入: 3 # 空 4 # 输出: 5 # 对指定训练集文件进行K近邻算法测试并打印测试结果 6 # ================================================ 7 def datingClassTest(): 8 '分类算法测试' 9 10 # 设置要测试的数据比重 11 hoRatio = 0.10 12 # 获取训练集 13 datingDataMat,datingLabels = file2matrix('datingTestSet.txt') 14 # 数据归一化 15 normMat, ranges, minVals = autoNorm(datingDataMat) 16 # 计算实际要测试的样本数 17 m = normMat.shape[0] 18 numTestVecs = int(m*hoRatio) 19 # 存放错误数 20 errorCount = 0.0 21 22 # 对测试集样本一一进行分类并分析打印结果 23 print "错误的分类结果如下:" 24 for i in range(numTestVecs): 25 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) 26 if (classifierResult != datingLabels[i]): 27 print "分类结果: %d, 实际结果: %d" % (classifierResult, datingLabels[i]) 28 errorCount += 1.0 29 print "总错误率: %.2f" % (errorCount/float(numTestVecs)) 30 print "总错误数:%.2f" % errorCount
其中,classify0 函数在文章K-近邻分类算法原理分析与代码实现中有具体实现。
打印出如下结果:

错误率为5%左右,这是应该算是比较理想的状况了吧。
第五步:使用算法构建完整可用系统
下面,可以在这个训练集和分类器之上构建一个完整的可用系统了。
系统功能很简单:用户输入要判断对象三个特征 - "每年获得的飞行常客里程数","玩网游所消耗的时间比","每年消耗的冰淇淋公升数"。
PS:在真实系统中,这部分输入可不由用户来输入,而从网站直接下载数据。
程序帮你判断你是不喜欢还是有点喜欢,抑或是很喜欢。
这部分代码如下:
1 # =========================================================== 2 # 输入: 3 # 空 4 # 输出: 5 # 对用户指定的对象以指定的训练集文件进行K近邻分类并打印结果信息 6 # =========================================================== 7 def classifyPerson(): 8 '约会对象分析系统' 9 10 # 分析结果集合 11 resultList = ['不喜欢', '有点喜欢', '很喜欢'] 12 13 # 获取用户输入的目标分析对象的特征值 14 percentTats = float(raw_input("玩网游所消耗的时间比:")) 15 ffMiles = float(raw_input("每年获得的飞行常客里程数:")) 16 iceCream = float(raw_input("每年消费的冰淇淋公升数:")) 17 18 # 获取训练集 19 datingDataMat, datingLabels = file2matrix('datingTestSet.txt') 20 # 数据归一化 21 normMat, ranges, minVals = autoNorm(datingDataMat) 22 # 获取分类结果 23 inArr = numpy.array([ffMiles, percentTats, iceCream]) 24 classifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels, 3) 25 26 print "分析结果:", resultList[classifierResult-1]
运行结果:
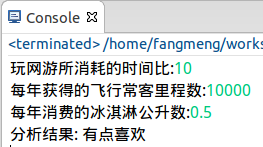
至此,该系统编写完毕。
小结
1. KNN算法其实并没有一个实际的 "训练" 过程。取得了数据就当作是训练过了的。在下下篇文章将讲解决策树,它就有详细的训练,或者说知识学习的过程。
2. 可采用从网站自动下载数据的方式,让这个系统的决策更为科学,再加上良好的界面,就能投入实际使用了。
3. 下篇文章将讲解KNN算法一个更为高级的应用 - 手写识别系统。
4. 这个程序也看出,处理文本/字符串方面,Python比C++好用多了。