一、java类,创建、编译、到运行的工程:
1、随便建一个Java类,保存后就是一个.java文件,
2、然后我们使用 javac命令编译 .java文件,生产 .class文件。
3、再然后使用 java 命令执行 .class文件。
注:javac命令执行的是 javac.exe,java命令执行是是 java.exe,
我们在编辑器(IDEA、eclipse)中点击的运行其实是 编译+运行 操作。

第三步中 的 java命令 运行.class文件,很明显是不能直接运行的,它不像C语言(编译cpp后生成exe文件直接运行)
实际上 这行 .class文件是交由JVM来解析运行的。
二、JDK JRE JVM 三者的关系:

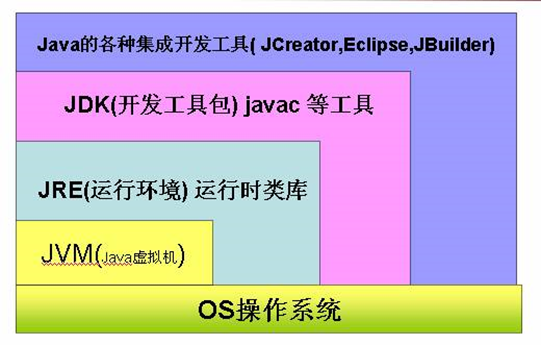
由图可直观的看出 JDK包含JRE包含JVM(Java Vritual Machine)
而且JVM是JDK最底层直接接触操作系统的。
JVM是运行在操作系统之上的,每个操作系统的指令是不同的,而JDK是区分操作系统的,
只要你的本地系统装了JDK,这个JDK就是能够和当前系统兼容的。
三、.class 文件与JVM
虚拟机规范则是严格规定了有且只有5种情况必须立即对类进行“初始化”(class文件加载到JVM中):
- 创建类的实例(new 的方式)。访问某个类或接口的静态变量,或者对该静态变量赋值,调用类的静态方法
- 反射的方式
- 初始化某个类的子类,则其父类也会被初始化
- Java虚拟机启动时被标明为启动类的类,直接使用java.exe命令来运行某个主类(包含main方法的那个类)
- 当使用JDK1.7的动态语言支持时(....)
所以说:
- Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(像是基类)完全加载到jvm中,
- 至于其他类,则在需要的时候才加载。这当然就是为了节省内存开销。
四、JVM的结构体系
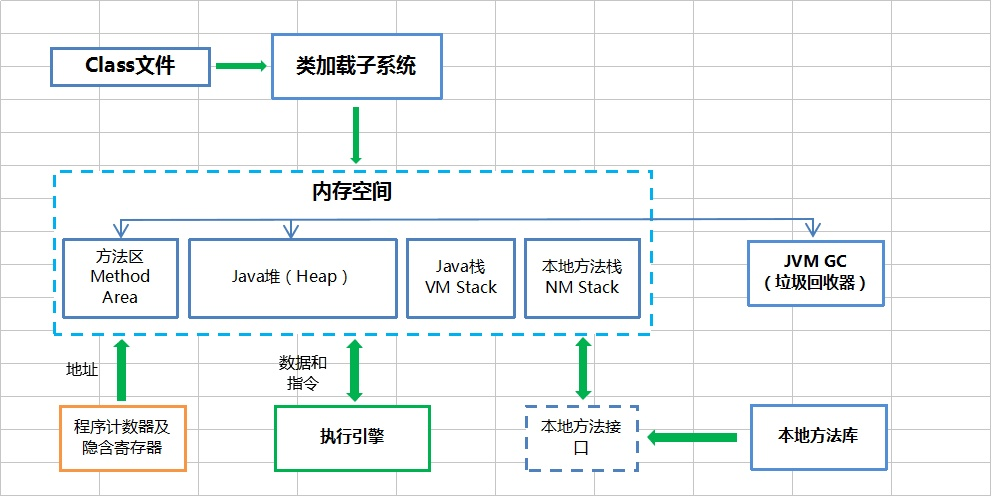
1、方法区(Method Area):
1)、类型信息和类静态变量都保存在方法区中,常量池也存放于方法区中,
2)、程序中所有的线程共享一个方法区,所以访问方法区的信息必须确保线程是安全的。
3)、如果有两个线程同时去加载一个类,那么只能有一个线程被允许去加载这个类,另一个必须等待。
4)、在程序运行时,方法区大小可变的,程序在运行时可以扩展。
5)、方法区也可以被垃圾回收,但条件非常严苛,必须在该类没有任何引用的情况下,
注:
一、类型信息包括:
1、类型的全名(The fully qualified name of the type) 2、类型的父类型全名(除非没有父类型,或者父类型是java.lang.Object)(The fully qualified name of the typeís direct superclass) 3、该类型是一个类还是接口(class or an interface)(Whether or not the type is a class ) 4、类型的修饰符(public,private,protected,static,final,volatile,transient等)(The typeís modifiers) 5、所有父接口全名的列表(An ordered list of the fully qualified names of any direct superinterfaces) 6、类型的字段信息(Field information) 7、类型的方法信息(Method information) 8、所有静态类变量(非常量)信息(All class (static) variables declared in the type, except constants) 9、一个指向类加载器的引用(A reference to class ClassLoader) 10、一个指向Class类的引用(A reference to class Class) 11、基本类型的常量池(The constant pool for the type)
二、方法列表(Method Tables) 为了更高效的访问所有保存在方法区中的数据,在方法区中,除了保存上边的这些类型信息之外,还有一个为了加快存取速度而设计的数据结构:方法列表。
每一个被加载的非抽象类,Java虚拟机都会为他们产生一个方法列表,这个列表中保存了这个类可能调用的所有实例方法的引用,保存那些父类中调用的方法。
2、Java堆(JVM堆、Heap)
1)、new 一个对象或者数组时,都在堆中为新的对象分配内存。
2)、虚拟机中只有一个堆,程序中所有的线程都共享它。
3)、堆占用的内存空间是最多的。
4)、堆的存取类型为管道类型,先进先出。
5)、在程序运行中,可以动态的分配堆的内存大小。
6)、堆的内存资源回收是交给JVM GC进行管理的,
3、Java栈(JVM栈、Stack)
1)、在Java栈中只保存基础数据类型和自定义对象的引用,注意只是对象的引用而不是对象本身哦,对象是保存在堆区中的。
2)、栈的存取类型为类似于水杯,先进后出。
3)、每一个线程都包含一个栈区,每个栈中的数据都是私有的,其他栈不能访问。
4)、栈内的数据在超出其作用域后,会被自动释放掉,它不由JVM GC管理。
5)、每个线程都建立一个操作栈,每个栈又包含若干个栈帧,每个栈帧对应每个方法的每次调用,
栈帧包含了三部分:
局部变量区(方法内基本类型变量、变量对象指针)
操作数栈区(存放方法执行过程中产生的中间结果)
运行环境区(动态连接、正确的方法返回相关信息、异常捕捉)
注:像String、Integer、Byte、Short、Long、Character、Boolean这六个属于包装类型,它们是存放于堆中的。
4、本地方法栈
1)、本地方法栈的功能和JVM栈非常类似,用于存储本地方法的局部变量表,本地方法的操作数栈等信息。
2)、栈的存取类型为类似于水杯,先进后出。
3)、栈内的数据在超出其作用域后,会被自动释放掉,它不由JVM GC管理。
4)、每一个线程都包含一个栈区,每个栈中的数据都是私有的,其他栈不能访问。
5)、本地方法栈是在程序调用或JVM调用本地方法接口(Native)时候启用。
6)、本地方法都不是使用Java语言编写的,比如使用C语言编写的本地方法,
本地方法也不由JVM去运行,所以本地方法的运行不受JVM管理。
HotSpot VM将本地方法栈和JVM栈合并了。
5、程序计数器
1)、字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令。
分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
2)、JVM的多线程是通过 线程 轮流切换 并 分配处理器执行时间 的方式来实现的,
为了各条线程之间的切换后计数器能恢复到正确的执行位置,
所以每条线程都会有一个独立的程序计数器。
3)、程序计数器占很小的内存空间。
4)、当线程正在执行一个Java方法,程序计数器 记录 地址 :是正在执行的 JVM字节码指令地址。
如果正在执行的是一个Natvie(本地方法),那么这个计数器的值则为空(Underfined)。
5)、程序计数器这个内存区域是唯一一个在JVM规范中没有规定任何OutOfMemoryError(内存不足错误)的区域。
6、JVM执行引擎
1)、Java虚拟机相当于一台虚拟的“物理机”,这两种机器都有代码执行能力,其区别主要:
物理机的执行引擎是直接建立在处理器、硬件、指令集和操作系统层面上的。
JVM的执行引擎是自己实现的,因此程序员可以自行制定指令集和执行引擎的结构体系,
因此能够执行那些不被硬件直接支持的指令集格式。
2)、JVM规范中制定了虚拟机字节码执行引擎的概念模型,这个模型称为JVM执行引擎的统一外观。
JVM中,可能有两种的执行方式:解释执行(解释器执行)和编译执行(即时编译器产生本地代码)。
有些虚拟机只采用一种执行方式,有些可能同时采用两种,甚至包含几个不同级别的编译器执行引擎。
输入的是字节码文件、处理过程是等效字节码解析过程、输出的是执行结果。
在这三点上每个JVM执行引擎都是一致的。
7、本地方法接口(JNI)
JNI是Java Native Interface的缩写,它提供API实现Java和其他语言的通信(主要是C和C++)。
1)、JNI的适用场景
当我们有一些旧的库,已经使用C语言编写好了,如果要移植到Java上来,非常浪费时间,
而JNI支持Java程序与C语言编写的库进行交互,这样就不必要进行移植了。
或者是与硬件、操作系统进行交互、提高程序的性能等,都可以使用JNI。
需要注意的一点是需要保证本地代码能工作在任何Java虚拟机环境。
2)、JNI的副作用
一旦使用JNI,Java程序将丢失了Java平台的两个优点:
1、程序不再跨平台,要想跨平台,必须在不同的系统环境下程序编译配置本地语言部分。
2、程序不再是绝对安全的,本地代码的使用不当可能会导致整个程序崩溃。一个通用规则是,
调用本地方法应该集中在少数的几个类当中,这样就降低了Java和其他语言之间的耦合。
8、JVM GC(垃圾回收机制)
GC的内容太多,另开一篇吧。待续。。。。
参考:https://zhuanlan.zhihu.com/p/25713880
参考:https://www.cnblogs.com/lfs2640666960/p/9297176.html