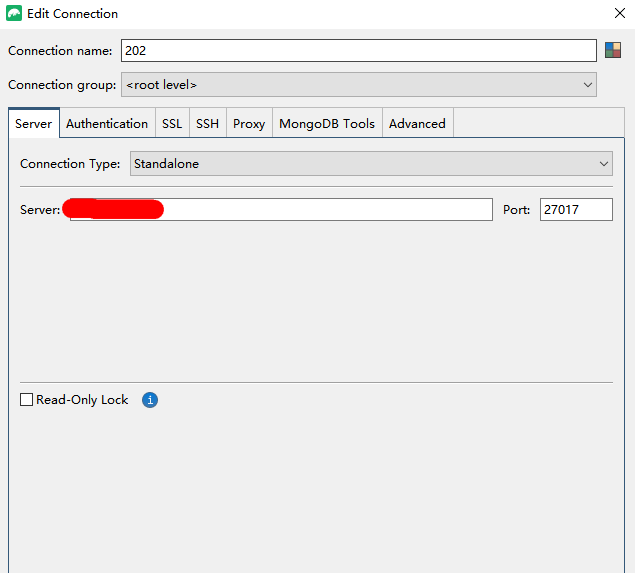
链接到mongo
新建超级用户
上文中我们提到mongo用户库表管理。为了方便我们先新建一个root权限的用户。
db.createUser({user:'dbadmin',pwd:'123456', roles:[{role:'userAdminAnyDatabase', db:'admin'}]})
使用studio-3t链接到mongo

新建爬虫库
打开连接后,在连接上右键,然后Add Database ->输入数据库名称spider001
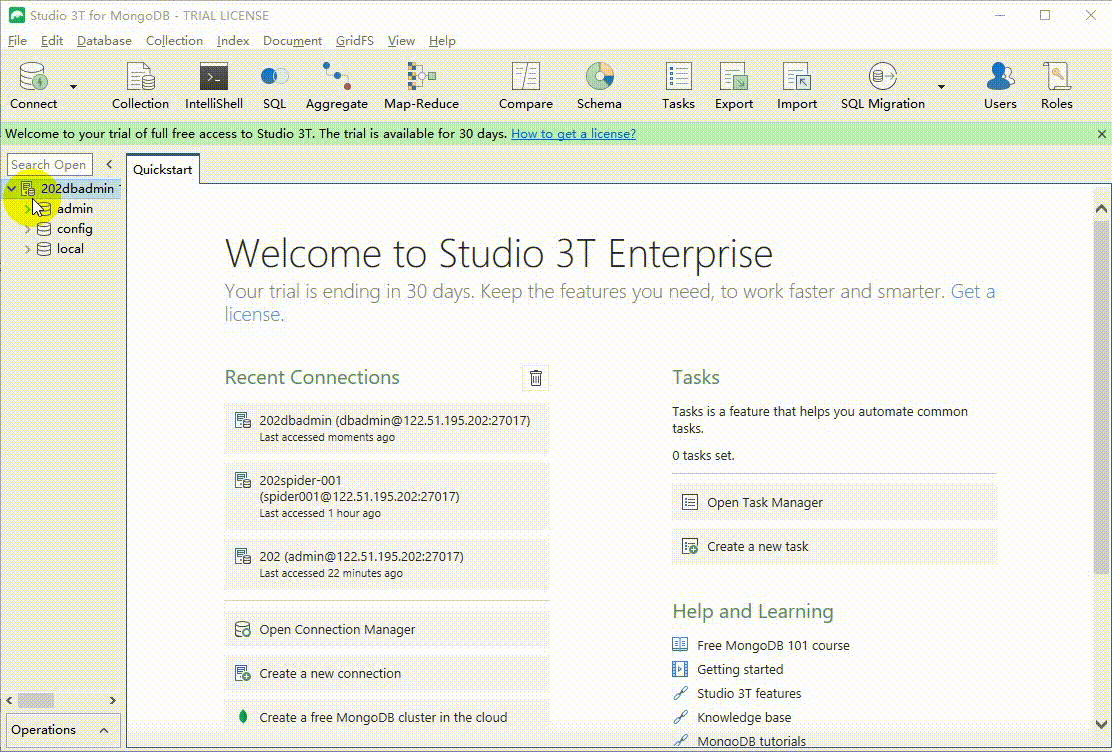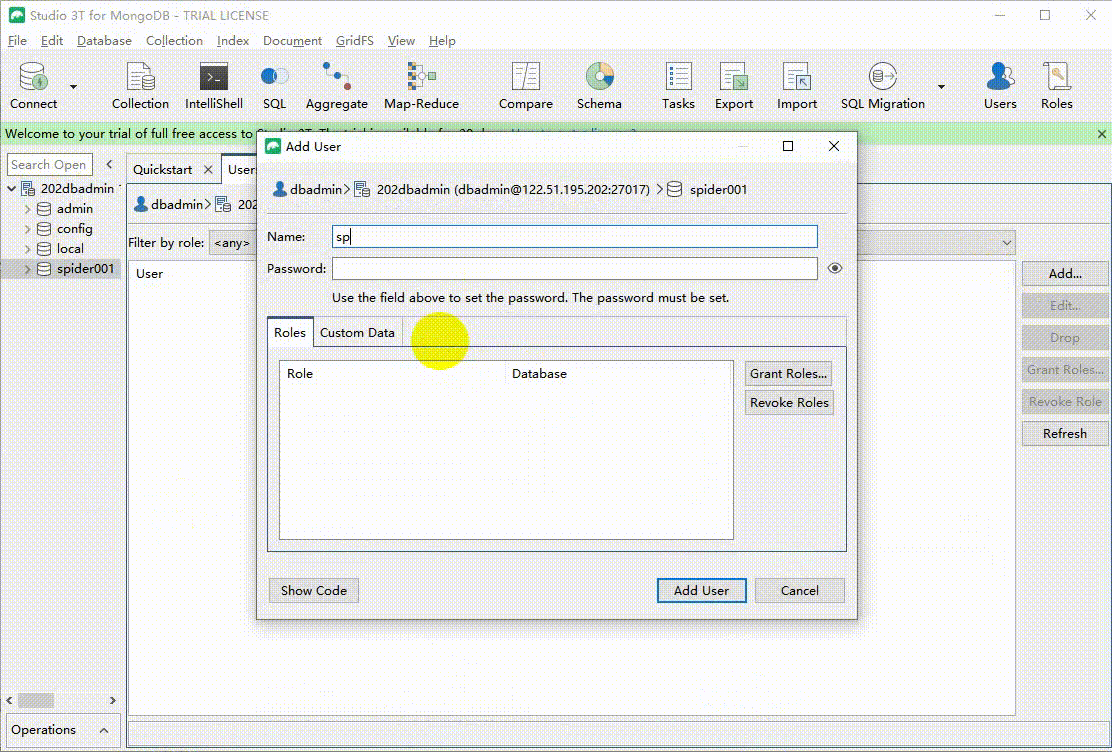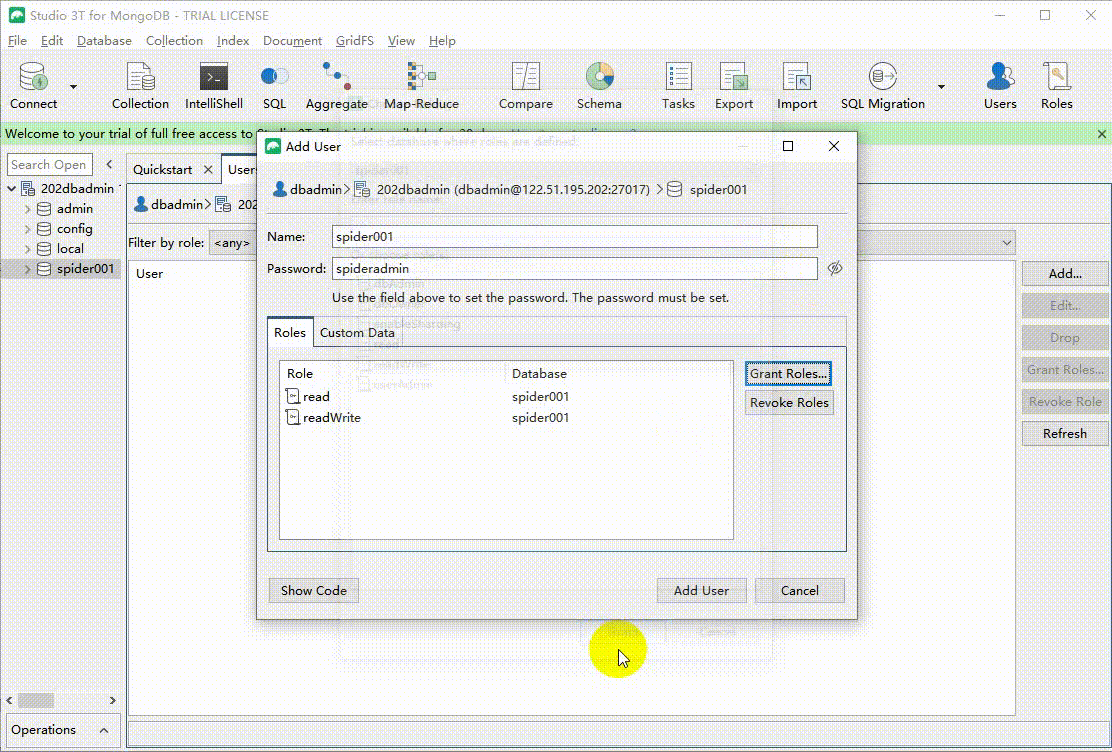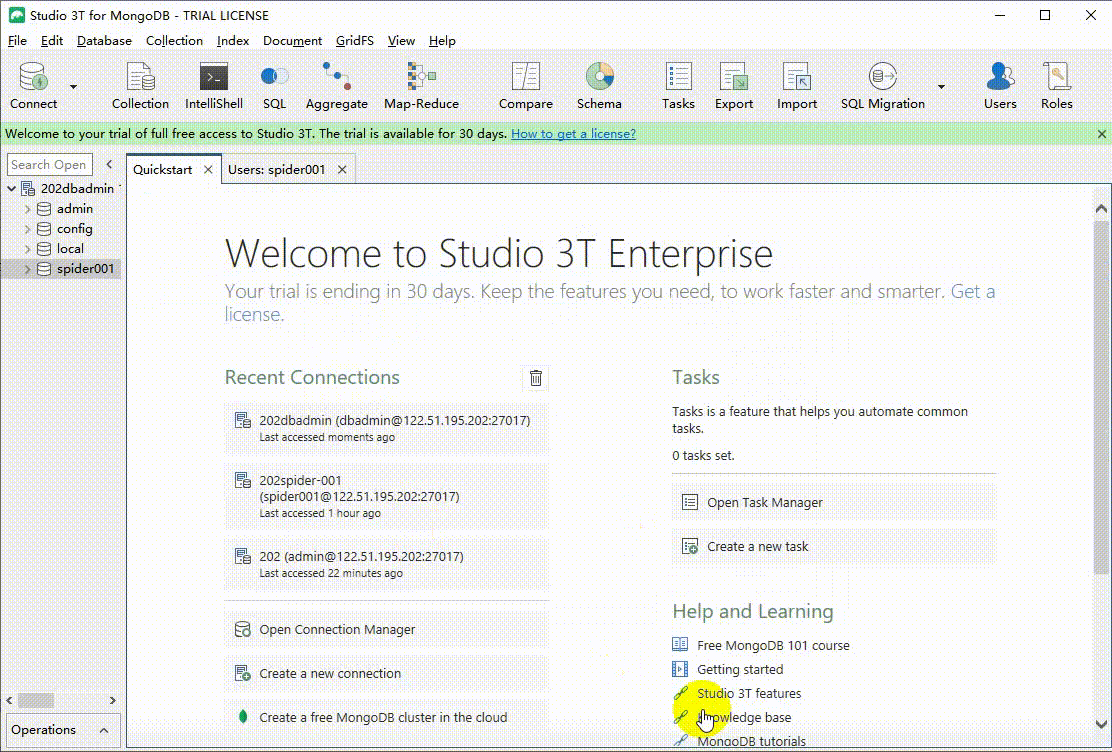
spider001在数据库上面右键Manage Users -> Add 然后输入用户密码,再授权。我们还能查看该操作对应的代码。特别注意新建数据库操作其实相当于use dbname 的操作,不会真正新建数据库,只有数据库有用户或者数据时,数据库才回真实存在
use spider001
db.runCommand({
"createUser" : "spider001",
"pwd" : "spideradmin",
"customData" : {
},
"roles" : [
{
"role" : "read",
"db" : "spider001"
},
{
"role" : "readWrite",
"db" : "spider001"
}
]
});
CRUD操作
Create or insert
选择spider001数据库,可以用studio 3t打开一个shell终端
#单条
db.user.insert({name:"refly",nikename:"haima",joy:["NBA","football","hiking"]})//不需要建表
#多条
db.user.insertMany([
{
"name":"hailong",age:20,work:{location:"成都",name:"spider"}
},
{
"name":"rob",
"birth":new Date("2020-10-23")
}
])
插入后回自动生成一个_id字段
Read operations
find方法基本应用
db.user.find({}) //查询所有
db.user.find({name:"haima"}) //字段匹配
db.user.find({"_id": ObjectId("5f9297276951ee42b7a44c24")}) //_id字段
db.user.find({age:{$gt:10}}) //筛选age字段大于10岁的
db.user.find({"work.name":"spider"}) //字段嵌套
db.user.find({"birth":{$gt:new Date("2010-10-23")}}) //日期处理
db.user.find({age:{$exists:false}} ) //查询age字符不存在的 数据
//正则
db.user.find(
{ "name": { $regex: /^.*g$/ } }
)
//多条件
db.user.find( {
name:"hailong",
age:20
} )
db.user.find({joy:{$size:3}}) //查询joy(数组)字段 长度为3的数据
db.user.find({ //数组字段完全匹配。数组中的元素顺序不对也不会被匹配
"joy": [
"NBA", "football", "hiking"
]
})
db.user.find({ //忽略元素顺序,但元素匹配完全匹配
"joy":{$all:[
"football",
"NBA",
"hiking"
],$size:3 }
})
关键词
$in数组字段中,有一个满足就满足查询。如果是单独字段,查询这个字段的值是否在给定的 数组中$nin不包含给定数组中的元素,和$in相反$all数组字段中,包含所有给出的值 才满足查询$gtgreater than 筛选条件 中的 大于$ltless than 筛选条件 中的 小于$lte小于等于$gte大于等于$ne不等于$or逻辑或$and逻辑与$exists筛选字段是否存在 同 :null效果相同
db.bios.find( { contribs: { $all: [ "ALGOL", "Lisp" ] } } ) //contribs含其 `ALGOL`且包含`Lisp`
db.bios.find( { contribs: { $in: [ "ALGOL", "Lisp" ]} } ) //contribs含其中一个就可以
db.user.find({name:{$in:["rob","refly"]}}) //name 为rob或者refly
db.user.find({name:{$nin:["rob","refly"]}}) //name 不为rob 也不为 refly的
db.user.find({$or:[{name:"refly"},{age:2}]}) //$or name为refly或者age为2
db.user.find({$or:[{name:"refly"},{age:2}]}) //$or name为refly或者age为2
db.user.find({$and:[{name:"rob"},{age:{$exists:false}}]}) 咱效果相同于db.user.find({name:"rob",age:null})
$in$nin的查询都比较低效
限制返回值字段
db.user.find( { }, { name: 1 } ) //只返回name字段和 _id字段,_id会默认返回
db.user.find( { }, { name: 1, _id: 0} ) //只返回name字段
db.user.find( { }, { name: true } ) //true,false也可以
//二级字段,只返回work.location字段,当然也会返回work
db.user.find({ },{ _id: 0,"work.location":1 } )
db.user.find({ },{ _id: 0,joy:{$slice:1} } ) //joy字段(数组)中只返回一个元素
常用方法 sort() limit() skip()
sort()排序
db.user.find({ }).sort( { age:-1, name: -1} ) //先按年龄排序,然后再按照名字排序
limit(n) 取前面n条
db.user.find( { } ).limit(10) //取10条
skip(n) 跳过前面几条
db.user.find( { } ).skip(10) //忽略前10条
min()、max()
暂无解读
count()
db.user.find( { } ).count() //统计查询条数
itcount()
也是统计查询条数,区别是itcount()是迭代器中剩余的条数,而.count() 是查询条数
db.user.find({ }).limit(10).count() //结果为11,表中为11条数据
db.user.find({ }).limit(10).itcount() //结果为10,迭代器中剩余10条数据
size()
可以统计出skip()和limit()查询过后的元素条数,这个更像itcount()
next()
迭代器返回下一个对象
db.user.find({ }).next()
explain()
查询详情
db.user.find({"work.name":"spider"}).explain() //感觉并没什么暖用
结果为
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "spider001.user",
"indexFilterSet" : false,
"parsedQuery" : {
"work.name" : {
"$eq" : "spider"
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"work.name" : {
"$eq" : "spider"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "VM_0_8_centos",
"port" : 27017,
"version" : "3.6.20",
"gitVersion" : "39c200878284912f19553901a6fea4b31531a899"
},
"ok" : 1
}
forEach()
遍历执行
db.user.find().forEach(function(el){print(el.name) })
map()
遍历执行,每个执行结果都会返回,组成一个数组对象
db.user.find().map( function(u) { if(u.name!=null)return u.name; } )
Update Operations
updateOne() updateMany()方法
- updateOne()
db.collection.updateOne(
<filter>, //修改条件
<update>, //修改内容
{
upsert: <boolean>, //没有的话就插入
writeConcern: <document>, //写入策略,暂时不做解读
collation: <document>, //Collation特性允许MongoDB的用户根据不同的语言定制排序规则
arrayFilters: [ <filterdocument1>, ... ]
}
)
db.user.update({_id:ObjectId("5f9297276951ee42b7a44c24")},{$set:{name:"xxx"}})
//执行结果 WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
db.user.update({_id:-1 },{$set:{name:"-1id"}},{ upsert: true })
//执行结果 WriteResult({ "nMatched" : 0, "nUpserted" : 1, "nModified" : 0, "_id" : -1 })
db.user.update({name:"rob"},{$set:{name:"hhhhh"}},{collation: {locale: "zh"}})
//collation 使用,还理解不太清楚
- arrayFilters用法
//数据为以下
db.students.insert([
{ "_id" : 1, "grades" : [ 95, 92, 90 ] },
{ "_id" : 2, "grades" : [ 98, 100, 102 ] },
{ "_id" : 3, "grades" : [ 95, 110, 100 ] }
])
db.students.updateOne(
{ _id:2 },
{ $set: { "grades.$[element]" : 100 } },
{ arrayFilters: [ { "element": { $gte: 100 } } ] } //只更新grades字段中大于100的数
)
执行后 _id为2数据的更新情况为只更新了grades 大于100的
{
"_id" : 2.0,
"grades" : [
98.0,
100.0,
100.0
]
}
- updateMany()
和updateOne()使用方式相同,只是updateMany可以更新多条数据
db.collection.updateMany(
<filter>,
<update>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ]
}
)
replaceOne()方法
使用方式和updateOne()一致,只是会替换整条数据
db.collection.replaceOne(
<filter>,
<replacement>,
{
upsert: <boolean>,
writeConcern: <document>,
collation: <document>
}
)
db.user.replaceOne({_id:-1},{_id:-1,nikename:"xxx",age:2}) //执行后,这条数据中再没有name字段了
Delete Operations
- deleteOne()、deleteMany()
db.collection.deleteOne(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
db.collection.deleteMany(
<filter>,
{
writeConcern: <document>,
collation: <document>
}
)
db.user.deleteOne({name:"hailong"}) //单条
db.user.deleteMany({name:"hailong"}) //满足条件的都删除