今天老师开了个会,对毕设做了安排,老师推荐我们做知识图谱方面的内容,所以我去网上查阅了相关的资料,先进行了简单的了解。
人们想要机器可以像人一样进行逻辑分析,那么知识图谱就是旨在解决这一类问题。
通过对历史数据的处理,赋予机器处理信息的能力。
下面摘自知乎:https://zhuanlan.zhihu.com/p/71128505
知识图谱的体系架构
知识图谱的架构主要包括自身的逻辑结构以及体系架构,
知识图谱在逻辑结构上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的 Neo4j、Twitter 的 FlockDB、JanusGraph 等。模式层构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
知识图谱的体系架构是指其构建模式的结构,如下图所示:
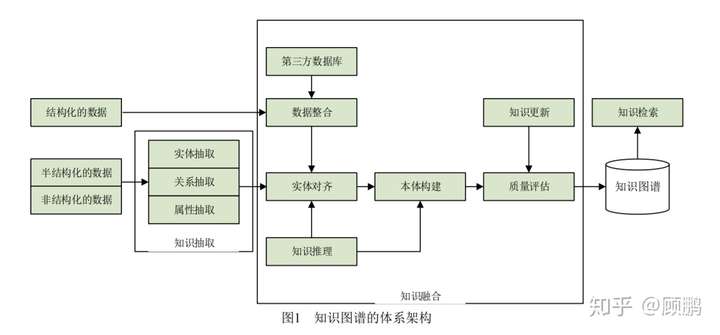
大规模知识库的构建与应用需要多种智能信息处理技术的支持。通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。
知识抽取
知识抽取主要是面向开放的链接数据,通过自动化的技术抽取出可用的知识单元,知识单元主要包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。知识抽取有三个主要工作:
- 实体抽取:在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步;
- 关系抽取:目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则。
- 属性抽取:属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。
知识表示
近年来,以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。一直在关注我们公众号的朋友肯定阅读过上一篇博文,graph embedding 就是一种表示学习。
知识融合
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
其中,知识更新是一个重要的部分。人类的认知能力、知识储备以及业务需求都会随时间而不断递增。因此,知识图谱的内容也需要与时俱进,不论是通用知识图谱,还是行业知识图谱,它们都需要不断地迭代更新,扩展现有的知识,增加新的知识。
知识图谱应用
知识图谱为互联网上海量、异构、动态的大数据表达、组织、管理以及利用提供了一种更为有效的方式,使得网络的智能化水平更高,更加接近于人类的认知思维。
智能搜索
如同我们在开篇介绍的例子,用户的查询输入后,搜索引擎不仅仅去寻找关键词,而是首先进行语义的理解。比如,对查询分词之后,对查询的描述进行归一化,从而能够与知识库进行匹配。查询的返回结果,是搜索引擎在知识库中检索相应的实体之后,给出的完整知识体系。
深度问答
问答系统是信息检索系统的一种高级形式,能够以准确简洁的自然语言为用户提供问题的解答。多数问答系统更倾向于将给定的问题分解为多个小的问题,然后逐一去知识库中抽取匹配的答案,并自动检测其在时间与空间上的吻合度等,最后将答案进行合并,以直观的方式展现给用户。
苹果的智能语音助手 Siri 能够为用户提供回答、介绍等服务,就是引入了知识图谱的结果。知识图谱使得机器与人的交互,看起来更智能。
社交网络
Facebook 于 2013 年推出了 Graph Search 产品,其核心技术就是通过知识图谱将人、
地点、事情等联系在一起,并以直观的方式支持精确的自然语言查询,例如输入查询式:“我朋友喜欢的餐厅”“住在纽约并且喜欢篮球和中国电影的朋友”等,知识图谱会帮助用户在庞大的社交网络中
找到与自己最具相关性的人、照片、地点和兴趣等。Graph Search 提供的上述服务贴近个人的生活,满足了用户发现知识以及寻找最具相关性的人的需求。
垂直行业应用
从领域上来说,知识图谱通常分为通用知识图谱和特定领域知识图谱。
在金融、医疗、电商等很多垂直领域,知识图谱正在带来更好的领域知识、更低金融风险、更完美的购物体验。更多的,如教育科研行业、图书馆、证券业、生物医疗以及需要进行大数据分析的一些行业。这些行业对整合性和关联性的资源需求迫切,知识图谱可以为其提供更加精确规范的行业数据以及丰富的表达,帮助用户更加便捷地获取行业知识。
总结
从技术来说,知识图谱的难点在于 NLP,因为我们需要机器能够理解海量的文字信息。但在工程上,我们面临更多的问题,来源于知识的获取,知识的融合。搜索领域能做的越来越好,是因为有成千上万(成百万上亿)的用户,用户在查询的过程中,实际也在优化搜索结果,这也是为什么百度的英文搜索不可能超过 Google,因为没有那么多英文用户。知识图谱也是同样的道理,如果将用户的行为应用在知识图谱的更新上,才能走的更远。
知识图谱肯定不是人工智能的最终答案,但知识图谱这种综合各项计算机技术的应用方向,一定是人工智能未来的形式之一。
那么如果我想要做这方面的毕设,那么我首先要解决数据的获取,老师也说确定选题,你先解决数据的问题,有那方面的数据再选,至于知识的抽取,融合,推理,表示,相信通过网络上资料的学习,可以了解到。
最后毕竟题目都没有确定,明天的任务,就先确定一下选题吧。