一、DML(数据操作语言)
插入:
insert into student values(01,'tonbby',99); (插入所有的字段)
insert into student(id,name) values(01,'tonbby'); (插入指定的字段)
从一个或多个表查数据,插入到另外一个表:
#目标表的字段数 = 来源表1的字段数
INSERT INTO 目标表 SELECT * FROM 来源表1 ;
#目标表的字段数 = 3 ,来源表2的字段数 >= 3
INSERT INTO 目标表 SELECT 字段1, 字段2, 字段3 FROM 来源表2 ;
#(字段1,字段2, ...) 的数量 = 字段a,字段b, ... 的数量
INSERT INTO 目标表 (字段1, 字段2, ...) SELECT 字段a, 字段b, ... FROM 来源表 ;
#从多个表查数据
INSERT INTO T01_school
SELECT t1.*, t2.*
FROM T02_class t1
LEFT JOIN T03_student t2 ON t1.stdId = t2.id
更新:
update student set name = 'tonbby',score = '99' where id = 01;
update A表, B表 set A表.列名 = B表.列名 where A表.ID = B表.ID;(根据关联的表更新数据)
删除:
delete from tonbby where id = 01;
注意:
开发中很少使用delete,删除有物理删除和逻辑删除,其中逻辑删除可以通过给表添加一个字段(isDel),若值为1,代表删除;若值为0,代表没有删除。
此时,对数据的删除操作就变成了update操作了。truncate和delete的区别:
truncate是删除表,再重新创建这个表。属于DDL,delete是一条一条删除表中的数据,属于DML。
二、DQL(数据查询语言)
SQL语句的执行顺序

结合上图,整理出如下伪SQL查询语句
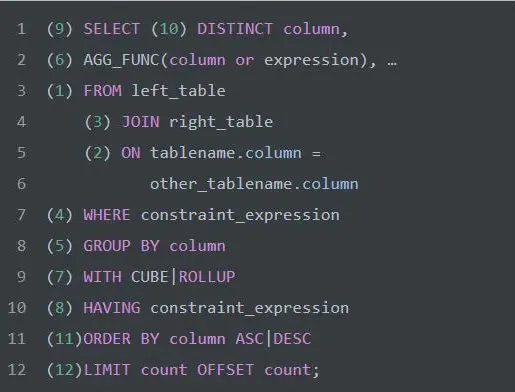
从这个顺序中我们可以发现,所有的查询语句都是从 FROM 开始执行的。在实际执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。 接下来,我们详细的介绍下每个步骤的具体执行过程。
1 FROM 执行笛卡尔积
FROM 才是 SQL 语句执行的第一步,并非 SELECT 。对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1,获取不同数据源的数据集。
2 ON 应用ON过滤器
对虚拟表VT1 应用ON筛选器,ON 中的逻辑表达式将应用到虚拟表 VT1中的各个行,筛选出满足ON 逻辑表达式的行,生成虚拟表 VT2 。
3 JOIN 添加外部行
如果指定了OUTER JOIN保留表中未找到匹配的行将作为外部行添加到虚拟表 VT2,生成虚拟表 VT3。保留表如下:
LEFT OUTER JOIN把左表记为保留表
RIGHT OUTER JOIN把右表记为保留表
FULL OUTER JOIN把左右表都作为保留表
在虚拟表VT2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予NULL值,最后生成虚拟表 VT3。
如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1~3,直到处理完所有的表为止。
4 WHERE 应用WEHRE过滤器
对虚拟表 VT3应用WHERE筛选器。根据指定的条件对数据进行筛选,并把满足的数据插入虚拟表VT4。
由于数据还没有分组,因此现在还不能在WHERE过滤器中使用聚合函数对分组统计的过滤。
同时,由于还没有进行列的选取操作,因此在SELECT中使用列的别名也是不被允许的。
备注:
5 GROUP BY 分组
按GROUP BY子句中的列/列表将虚拟表VT4中的行唯一的值组合成为一组,生成虚拟表VT5。如果应用了GROUP BY,那么后面的所有步骤都只能得到的虚拟表VT5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。
同时,从这一步开始,后面的语句中都可以使用SELECT中的别名。
6 AGG_FUNC 计算聚合函数
计算 max 等聚合函数。SQL Aggregate 函数计算从列中取得的值,返回一个单一的值。常用的 Aggregate 函数包涵以下几种:
AVG:返回平均值
COUNT:返回行数
FIRST:返回第一个记录的值
LAST:返回最后一个记录的值
MAX: 返回最大值
MIN:返回最小值
SUM: 返回总和
7 WITH 应用ROLLUP或CUBE
对虚拟表VT5应用ROLLUP或CUBE选项,生成虚拟表VT6。
CUBE 和 ROLLUP 区别如下:
CUBE 生成的结果数据集显示了所选列中值的所有组合的聚合。
ROLLUP 生成的结果数据集显示了所选列中值的某一层次结构的聚合。
8 HAVING 应用HAVING过滤器
对虚拟表VT6应用HAVING筛选器。根据指定的条件对数据进行筛选,并把满足的数据插入虚拟表VT7。
HAVING 语句在SQL中的主要作用与WHERE语句作用是相同的,但是HAVING是过滤聚合值,在 SQL 中增加 HAVING 子句原因就是,WHERE 关键字无法与聚合函数一起使用,HAVING子句主要和GROUP BY子句配合使用。
9 SELECT 选出指定列
将虚拟表 VT7中的在SELECT中出现的列筛选出来,并对字段进行处理,计算SELECT子句中的表达式,产生虚拟表 VT8。
10 DISTINCT 行去重
将重复的行从虚拟表VT8中移除,产生虚拟表 VT9。DISTINCT用来删除重复行,只保留唯一的。
事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所有的记录都将是不相同的。
11 ORDER BY 排列
12 LIMIT/OFFSET 指定返回行
从VC10的开始处选择指定数量行,生成虚拟表 VT11,并返回调用者。
实例:
首先,我们先看下如上SQL的执行顺序,如下:
首先执行 FROM 子句, 从学生成绩表中组装数据源的数据。
执行 WHERE 子句, 筛选学生成绩表中所有学生的数学成绩不为 NULL 的数据 。
执行 GROUP BY 子句, 把学生成绩表按 "班级" 字段进行分组。
计算 avg 聚合函数, 按找每个班级分组求出 数学平均成绩。
执行 HAVING 子句, 筛选出班级 数学平均成绩大于 75 分的。
执行SELECT语句,返回数据,但别着急,还需要执行后面几个步骤。
执行 ORDER BY 子句, 把最后的结果按 "数学平均成绩" 进行排序。
执行LIMIT ,限制仅返回3条数据。结合ORDER BY 子句,即返回所有班级中数学平均成绩的前三的班级及其数学平均成绩。
思考一下,如果我们将上面语句改成,如下会怎样?

我们发现,若将 avg(数学成绩) > 75 放到WHERE子句中,此时GROUP BY语句还未执行,因此此时聚合值 avg(数学成绩) 还是未知的,因此会报错。
参考: