多协程的用法
1.gevent库
对比同步执行:
1 import requests,time 2 #导入requests和time 3 start = time.time() 4 #记录程序开始时间 5 6 url_list = ['https://www.baidu.com/', 7 'https://www.sina.com.cn/', 8 'http://www.sohu.com/', 9 'https://www.qq.com/', 10 'https://www.163.com/', 11 'http://www.iqiyi.com/', 12 'https://www.tmall.com/', 13 'http://www.ifeng.com/'] 14 #把8个网站封装成列表 15 16 for url in url_list: 17 #遍历url_list 18 r = requests.get(url) 19 #用requests.get()函数爬取网站 20 print(url,r.status_code) 21 #打印网址和抓取请求的状态码 22 23 end = time.time() 24 #记录程序结束时间 25 print(end-start) 26 #end-start是结束时间减去开始时间,就是最终所花时间。 27 #最后,把时间打印出来。
多协程执行:
1 from gevent import monkey 2 #从gevent库里导入monkey模块。 3 monkey.patch_all() 4 #monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。 5 import gevent,time,requests 6 #导入gevent、time、requests。 7 8 start = time.time() 9 #记录程序开始时间。 10 11 url_list = ['https://www.baidu.com/', 12 'https://www.sina.com.cn/', 13 'http://www.sohu.com/', 14 'https://www.qq.com/', 15 'https://www.163.com/', 16 'http://www.iqiyi.com/', 17 'https://www.tmall.com/', 18 'http://www.ifeng.com/'] 19 #把8个网站封装成列表。 20 21 def crawler(url): 22 #定义一个crawler()函数。 23 r = requests.get(url) 24 #用requests.get()函数爬取网站。 25 print(url,time.time()-start,r.status_code) 26 #打印网址、请求运行时间、状态码。 27 28 tasks_list = [ ] 29 #创建空的任务列表。 30 31 for url in url_list: 32 #遍历url_list。 33 task = gevent.spawn(crawler,url) 34 #用gevent.spawn()函数创建任务。 35 tasks_list.append(task) 36 #往任务列表添加任务。 37 gevent.joinall(tasks_list) 38 #执行任务列表里的所有任务,就是让爬虫开始爬取网站。 39 end = time.time() 40 #记录程序结束时间。 41 print(end-start) 42 #打印程序最终所需时间。
第1、3行代码:从gevent库里导入了monkey模块,这个模块能将程序转换成可异步的程序。monkey.patch_all(),它的作用其实就像你的电脑有时会弹出“是否要用补丁修补漏洞或更新”一样。它能给程序打上补丁,让程序变成是异步模式,而不是同步模式。它也叫“猴子补丁”。
第5行代码:我们导入了gevent库来帮我们实现多协程,导入了time模块来帮我们记录爬取所需时间,导入了requests模块帮我们实现爬取8个网站。
第21、23、25行代码:我们定义了一个crawler函数,只要调用这个函数,它就会执行【用requests.get()爬取网站】和【打印网址、请求运行时间、状态码】这两个任务。
第33行代码:因为gevent只能处理gevent的任务对象,不能直接调用普通函数,所以需要借助gevent.spawn()来创建任务对象。
这里需要注意一点:gevent.spawn()的参数需为要调用的函数名及该函数的参数。比如,gevent.spawn(crawler,url)就是创建一个执行crawler函数的任务,参数为crawler函数名和它自身的参数url。
第35行代码:用append函数把任务添加到tasks_list的任务列表里。
第37行代码:调用gevent库里的joinall方法,能启动执行所有的任务。gevent.joinall(tasks_list)就是执行tasks_list这个任务列表里的所有任务,开始爬取
总结一下用gevent实现多协程爬取的重点:

queue模块
当我们用多协程来爬虫,需要创建大量任务时,我们可以借助queue模块。
queue翻译成中文是队列的意思。我们可以用queue模块来存储任务,让任务都变成一条整齐的队列,就像银行窗口的排号做法。因为queue其实是一种有序的数据结构,可以用来存取数据。
这样,协程就可以从队列里把任务提取出来执行,直到队列空了,任务也就处理完了。就像银行窗口的工作人员会根据排号系统里的排号,处理客人的业务,如果已经没有新的排号,就意味着客户的业务都已办理完毕。
接下来,我们来实操看看,可以怎么用queue模块和协程配合,依旧以抓取8个网站为例。
1 from gevent import monkey 2 monkey.patch_all() 3 import gevent,time,requests 4 from gevent.queue import Queue 5 6 start = time.time() 7 8 url_list = ['https://www.baidu.com/', 9 'https://www.sina.com.cn/', 10 'http://www.sohu.com/', 11 'https://www.qq.com/', 12 'https://www.163.com/', 13 'http://www.iqiyi.com/', 14 'https://www.tmall.com/', 15 'http://www.ifeng.com/'] 16 17 work = Queue() 18 for url in url_list: 19 work.put_nowait(url) 20 21 def crawler(): 22 while not work.empty(): 23 url = work.get_nowait() 24 r = requests.get(url) 25 print(url,work.qsize(),r.status_code) 26 27 tasks_list = [ ] 28 29 for x in range(2): 30 task = gevent.spawn(crawler) 31 tasks_list.append(task) 32 gevent.joinall(tasks_list) 33 34 end = time.time() 35 print(end-start)
因为gevent库里就带有queue,所以我们用【from gevent.queue import Queue】就能把queue模块导入。其他模块和代码我们在讲解gevent时已经讲解过了,相信你能懂。
用Queue()能创建queue对象,相当于创建了一个不限任何存储数量的空队列。如果我们往Queue()中传入参数,比如Queue(10),则表示这个队列只能存储10个任务。
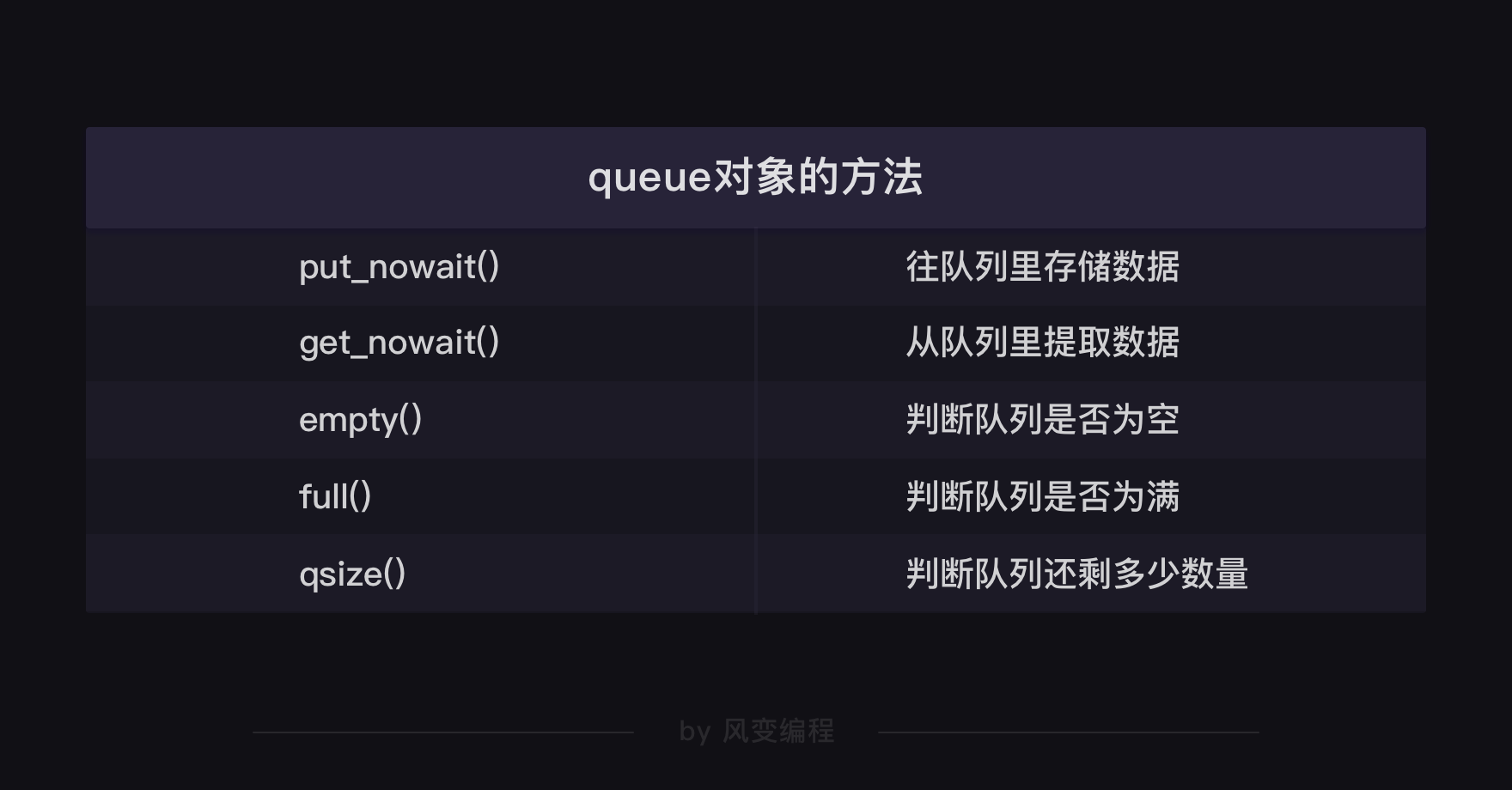
创建了queue对象后,我们就能调用这个对象的put_nowait方法,把我们的每个网址都存储进我们刚刚建立好的空队列里。
work.put_nowait(url)这行代码就是把遍历的8个网站,都存储进队列里。
这里定义的crawler函数,多了三个你可能看不懂的代码:1.while not work.empty():;2.url = work.get_nowait();3.work.qsize()。
这三个代码涉及到queue对象的三个方法:empty方法,是用来判断队列是不是空了的;get_nowait方法,是用来从队列里提取数据的;qsize方法,是用来判断队列里还剩多少数量的。
当然,queue对象的方法还不止这几种,比如有判断队列是否为空的empty方法,对应也有判断队列是否为满的full方法。