In [49]: frame2
Out[49]:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
six 2003 Nevada 3.2 NaN
取一列的值可以frame2.state或者frame2['state']
frame2['debt'] = 16.5
可以填充一列
删除列用del
del frame2['debt']
In [73]: frame3
Out[73]:
state Nevada Ohio
year
2000 NaN 1.5
2001 2.4 1.7
2002 2.9 3.6使用frame3.values可以得到一个二维ndarray
Out[74]:
array([[ nan, 1.5],
[ 2.4, 1.7],
[ 2.9, 3.6]])
索引对象是不可变的,不可以通过赋值修改
可以判断某值是否在索引里
'Ohio' in frame3.columns
Out[87]: True2003 in frame3.indexOut[88]: False重新索引

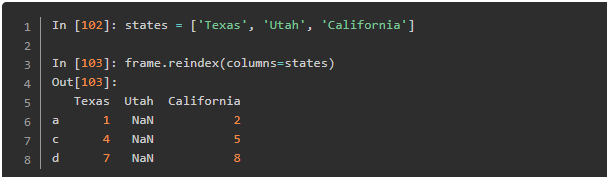
这玩意说白了可以取已有的索引名和增加索引名,而且这玩意在
取值多层索引的表有奇效

这种表想取到两种性别下得1910,1960,2010的数据,可以这样

删除列用del 那么删除行和列都可以用drop()

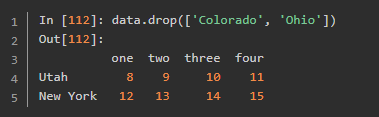
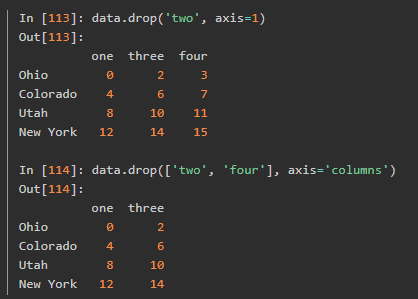
索引、选取和过滤

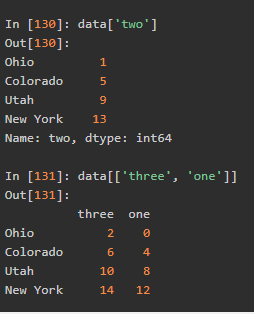
选取行以及通过布尔选数据

用loc和iloc进行选取
loc是根据索引取值

iloc是根据索引编号取值
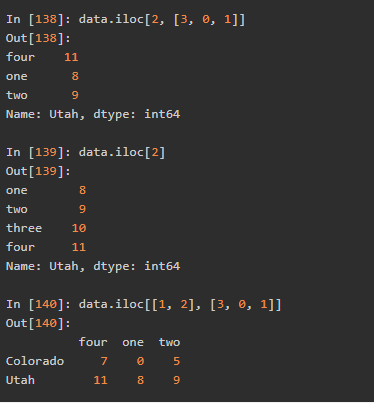
这两个标签可以用于切片

生成矩阵的常用方法
np.arange(20.).reshape((4, 5)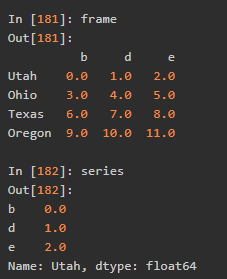
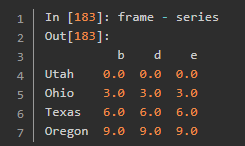

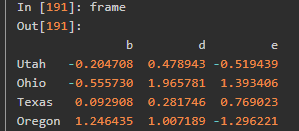

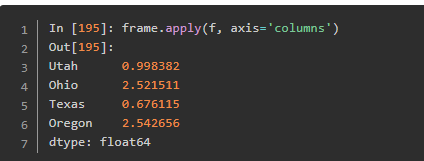
使用元素级的函数处理数据

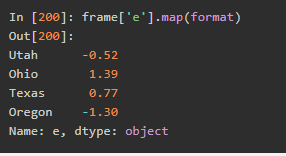
如果是Series的则使用map就行了
排序和排名


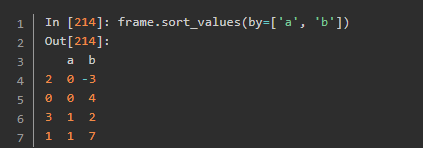
下面的这个机器学习用到过

汇总和计算描述统计
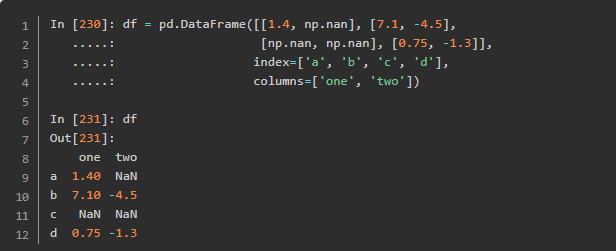
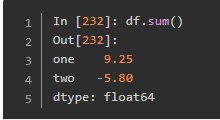

这个函数之后用于统计某一种营养含量最高的食物。

唯一值、值计数以及成员资格

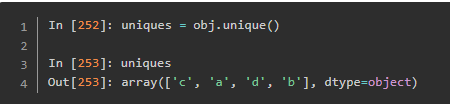
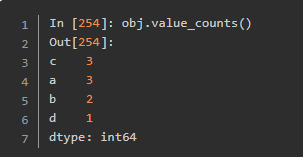

这个用于查找是否包含某些名字
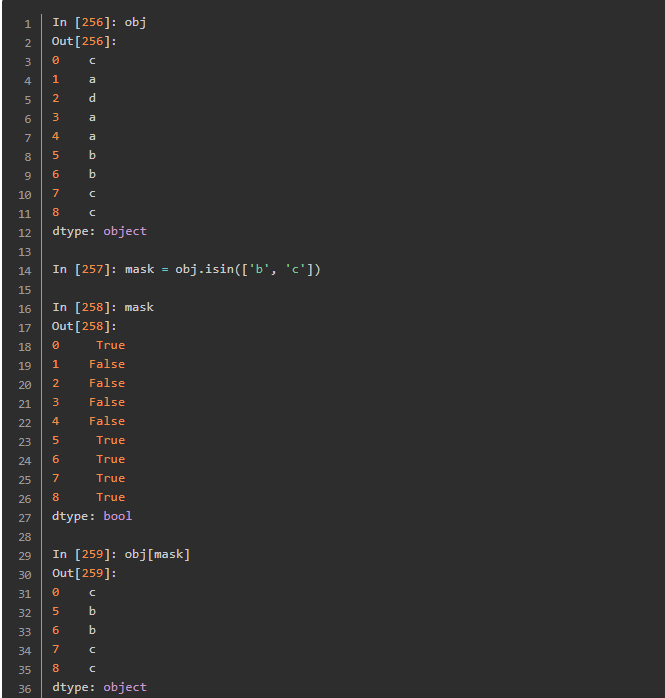
暂时没有用到

暂时没有用到

