出处: java如何防止反编译
综述(写在前面的废话)
Java从诞生以来,其基因就是开放精神,也正因此,其可以得到广泛爱好者的支持和奉献,最终很快发展壮大,以至于有今天之风光!但随着java的应用领域越来越广,特别是一些功能要发布到终端用户手中(如Android开发的app),有时候,公司为了商业技术的保密考虑,不希望这里面的一些核心代码能够被人破解(破解之后,甚至可以被简单改改就发布出去,说严重点,就可能会扰乱公司的正常软件的市场行为),这时候就要求这些java代码不能够被反编译。
这里要先说一下反编译的现象。因为java一直秉持着开放共享的理念,所以大家也都知道,我们一般共享一个自己写的jar包时,同时会共享一个对应的source包。但这些依然与反编译没有什么关系,但java的共享理念,不只是建议我们这样做,而且它自己也在底层上“强迫”我们这么做!在java写的.java文件后,使用javac编译成class文件,在编译的过程,不像C/C++或C#那样编译时进行加密或混淆,它是直接对其进行符号化、标记化的编译处理,于是,也产生了一个逆向工程的问题:可以根据class文件反向解析成原来的java文件!这就是反编译的由来。
但很多时候,有些公司出于如上述的原因考虑时,真的不希望自己写的代码被别人反编译,尤其是那些收费的app或桌面软件(甚至还有一些j2ee的wen项目)!这时候,防止反编译就成了必然!但前面也说过了,因为开放理念的原因,class是可以被反编译的,那现在有这样的需求之后,有哪些方式可以做到防止反编译呢?经过研究java源代码并进行了一些技术实现(结果发现,以前都有人想到过,所以在对应章节的时候,我会贴出一些写得比较细的文章,而我就简单阐述一下,也算偷个懒吧),我总共整理出以下这几种方式:
代码混淆
这种方式的做法正如其名,是把代码打乱,并掺入一些随机或特殊的字符,让代码的可读性大大降低,“曲线救国”似的达到所谓的加密。其实,其本质就是打乱代码的顺序、将各类符号(如类名、方法名、属性名)进行随机或乱命名,使其无意义,让人读代码时很累,进而让人乍一看,以为这些代码是加过密的!
由其实现方式上可知,其实现原理只是扰乱正常的代码可读性,并不是真正的加密,如果一个人的耐心很好,依然可以理出整个程序在做什么,更何况,一个应用中,其核心代码才是人们想去了解的,所以大大缩小了代码阅读的范围!
当然,这种方式的存在,而且还比较流行,其原因在于,基本能防范一些技术人员进行反编译(比如说我,让我破解一个混淆的代码,我宁愿自己重写一个了)!而且其实现较为简单,对项目的代码又无开发上的侵入性。目前业界也有较多这类工具,有商用的,也有免费的,目前比较流行的免费的是:proguard(我现象临时用的就是这个)。
上面说了,这种方式其实并不是真正加密代码,其实代码还是能够被人反编译(有人可能说,使用proguard中的optimize选项,可以从字节流层面更改代码,甚至可以让JD这些反编译软件可以无法得到内容。说得有点道理,但有两个问题:1、使用optimize对JDK及环境要求较高,容易造成混淆后的代码无法正常运行;2、这种方式其实还是混淆,JD反编译有点问题,可以有更强悍的工具,矛盾哲学在哪儿都是存在的^_^)。那如何能做到我的class代码无法被人反编译呢?那就需要我们下面的“加密class”!
加密class
在说加密class之前,我们要先了解一些java的基本概念,如:ClassLoader。做java的人已经或者以后会知道,java程序的运行,是类中的逻辑在JVM中运行,而类又是怎么加载到JVM中的呢(JVM内幕之类的,不在本文中阐述,所以点到为止)?答案是:ClassLoader。JVM在启动时是如何初始化整个环境的,有哪些ClassLoader及作用是什么,大家可以自己问度娘,也不在本文中讨论。
让我们从最常见的代码开始,揭开一下ClassLoader的一点点面纱!看下面的代码:
public class Demo{ public static void main(String[] args){ System.out.println(“hello world!”); } }
上面这段代码,大家都认识。但我要问的是:如果我们使用javac对其进行编译,然后使用java使其运行(为什么不在Eclipse中使用Run as功能呢?因为Eclipse帮我们封闭,从而简化了太多东西,使我们忽略了太多的底层细节,只有从原始的操作上,我们才能看到本质),那么,它是怎么加载到JVM中的?答案是:通过AppClassLoader加载的(相关知识点可以参考:http://hxraid.iteye.com/blog/747625)!如果不相信的话,可以输出一下System.out.println(Thread.currentThrea().getContextLoader());看看。
那又有一个新的问题产生了:ClassLoader又是怎样加载class的呢?其实,AppClassLoader继承自java.lang.ClassLoader类,所以,基本操作都在这个类里面,让我们直接看下面这段核心代码吧:

看看这个方法中的逻辑,非常简单,先从内存中找,如果没有,则从父级或根先找,如果没找到,则再从自己的方法里面找!那findClass里面是什么样的呢?很不幸,这个方法是个抽象(abstract)的,也就是使用什么方式加载,由程序使用ClassLoader自己决定!这就给我们留下了巨大的“”!让我们看一下非常常见的一个ClassLoader的实现,那就是URLClassLoader(几乎所有的j2ee的web项目的容器使用的ClassLoader都是继承自它),让我们看一下它的findClass的实现:

这个方法里面的逻辑也很简单,从定义的ucp(就是各个jar包或class文件的具体路径)中读取指定的class文件的信息(如字节流之类),然后交给defineClass定义到JVM中,让我们继续看一下这个方法的核心部分:

看到这里,已经没有必要再往下面看了(再往下就是native方法了,这是一个重大伏笔哦),我们要做的手脚就在这里!
手脚怎么做呢?很简单,上面的代码逻辑告诉我们,ClassLoader只是拿到class文件中的内容byte[],然后交给JVM初始化!于是我们的逻辑就简单了:只要在交给JVM时是正确的class文件就行了,在这之前是什么样子无所谓!所以,我们的加密的整个逻辑就是:
- 在编译代码时(如使用ant或maven),使用插件将代码进行加密(加密方式自己选),将class文件里面的内容读取成byte[],然后进行加密后再写回到class文件(这时候class文件里面的内容不是标准的class,无法被反编译了)
- 在启动项目代码时,指定使用我们自定义的ClassLoader就行了,而自定义的部分,主要就是在这里做解密工作!
如此,搞定!以上的做法比较完整的阐述,可以仔细阅读一下这篇文章:http://www.ibm.com/developerworks/cn/java/l-secureclass/文章中的介绍。
通过这个方法貌似可以解决代码反编译的问题了!错!这里有一个巨大的坑!因为我们自定义的ClassLoader是不能加密的,要不然JVM不认识,就全歇菜了!如果我来反编译,呵呵,我只要反编译一下这个自定义的ClassLoader,然后把里面解密后的内容写到指定的文件中保存下来,再把这个加了逻辑的自定义ClassLoader放回去运行,你猜结果会怎样?没错,你会想死!因为你好不容易想出来的加密算法,结果人家根本不需要破解,直接就绕过去了!
现在,让我们总结一下这个方法的优缺点:实现方式简单有效,同时对代码几乎没有侵入性,不影响正常开发与发布。缺点也很明显,就是很容易被人破解!
当然啦,关于缺点问题,你也可以这么干:先对所有代码进行混淆、再进行加密,保证:1、不容易找到我们自定义的那个ClassLoader;2、就算找到了,破解了,代码可读性还是很差,让你看得吐血!(有一篇文章,我觉得写得不错,大家可以看一看:http://cjnetwork.iteye.com/blog/851544)
嗯,我觉得这个方法很好,我自己也差点被这个想法感动了,但是,作为一个严谨的程序员,我真的不愿意留下一个隐患在这里!所以,我继续思索!
高级加密class
前面我们说过有个伏笔来着,还记得吧?没错,就是那个native!native定义的方法是什么方法?就是我们传说中的JNI调用!前面介绍过的有一篇文章中提到过,其实jvm的真实身份并不是java,而是c++写的jvm.dll(windows版本下),java与dll文件的调用就是通过JNI实现的!于是,我们就可以这样想:JNI可以调用第三方语言的类库,那么,我们可不可以把解密与装载使用第三方语言写(如C++,因为它们生成的库是不好反编译的),这样它可以把解密出来的class内容直接调jvm.dll的加载接口进行初始化成class,再返回给我们的ClassLoader?这样,我们自定义的ClassLoader只要使用JNI调用这个第三方语言写的组件,整个解密过程,都在黑盒中进行,别人就无从破解了!
嗯,这个方法真的很不错的!但也有两个小问题:1.使用第三方语言写,得会第三方语言,我说的会,是指很溜!2.对于不同的操作系统,甚至同一操作系统不同的版本,都可能要有差异化的代码生成对应环境下的组件(如window下是exe,linux是so等)!如果你不在乎这两个问题,我觉得,这个方式真的挺不错的。但对于我来说,我的信条是,越复杂的方式越容易出错!我个人比较崇尚简洁的美,所以,这个方法我不会轻易使用!
对了,如果大家觉得这个方法还算可行的话,可以推荐一个我无意中看到的东西给大家看看(我都没有用过的):jinstall,还有一个叫:http://download.csdn.net/detail/yzjcnlpj/3296134
更改JVM
看到这个标题,我想你可能会震惊。是的,你没看错,做为一个程序员,是应该要具有怀疑一切、敢想敢做的信念。如果你有意留心的话,你会发现JVM版本在业界其实也有好几个版本的,如:Sun公司的、IBM的、Apache的、Google的……
所以,不要阻碍自己的想象力,现在没有这个能力,并不代表不可能。所以,我想到,如果我把jvm改了,在里面对加载的类进行解密,那不就可以了吗?我在设计构思过程中,突然发现:人老了就是容易糊涂!前面使用第三方语言实现解密的两个问题,正好也是更改JVM要面对的两个问题,而且还有一个更大的问题:这个JVM就得跟着这个项目到处走啊!
于是,我把构思与设计从头又想了想,终于……放弃了!
附录其他文章关于防止java代码被反编译的方法
常用的保护技术
由于Java字节码的抽象级别较高,因此它们较容易被反编译。本节介绍了几种常用的方法,用于保护Java字节码不被反编译。通常,这些方法不能够绝对防止程序被反编译,而是加大反编译的难度而已,因为这些方法都有自己的使用环境和弱点。
1. 隔离Java程序
最简单的方法就是让用户不能够访问到Java Class程序,这种方法是最根本的方法,具体实现有多种方式。例如,开发人员可以将关键的Java Class放在服务器端,客户端通过访问服务器的相关接口来获得服务,而不是直接访问Class文件。这样黑客就没有办法反编译Class文件。目前,通过接口提供服务的标准和协议也越来越多,例如 HTTP、Web Service、RPC等。但是有很多应用都不适合这种保护方式,例如对于单机运行的程序就无法隔离Java程序。这种保护方式见图1所示。
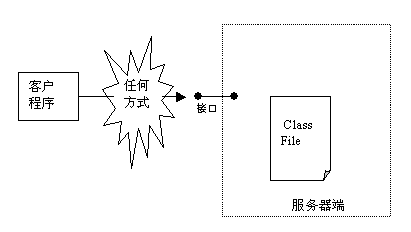
图1隔离Java程序示意图
2. 对Class文件进行加密
为了防止Class文件被直接反编译,许多开发人员将一些关键的Class文件进行加密,例如对注册码、序列号管理相关的类等。在使用这些被加密的类之前,程序首先需要对这些类进行解密,而后再将这些类装载到JVM当中。这些类的解密可以由硬件完成,也可以使用软件完成。
在实现时,开发人员往往通过自定义ClassLoader类来完成加密类的装载(注意由于安全性的原因,Applet不能够支持自定义的 ClassLoader)。自定义的ClassLoader首先找到加密的类,而后进行解密,最后将解密后的类装载到JVM当中。在这种保护方式中,自定义的ClassLoader是非常关键的类。由于它本身不是被加密的,因此它可能成为黑客最先攻击的目标。如果相关的解密密钥和算法被攻克,那么被加密的类也很容易被解密。这种保护方式示意图见图2。
图2 对Class文件进行加密示意图
3. 转换成本地代码
将程序转换成本地代码也是一种防止反编译的有效方法。因为本地代码往往难以被反编译。开发人员可以选择将整个应用程序转换成本地代码,也可以选择关键模块转换。如果仅仅转换关键部分模块,Java程序在使用这些模块时,需要使用JNI技术进行调用。
当然,在使用这种技术保护Java程序的同时,也牺牲了Java的跨平台特性。对于不同的平台,我们需要维护不同版本的本地代码,这将加重软件支持和维护的工作。不过对于一些关键的模块,有时这种方案往往是必要的。
为了保证这些本地代码不被修改和替代,通常需要对这些代码进行数字签名。在使用这些本地代码之前,往往需要对这些本地代码进行认证,确保这些代码没有被黑客更改。如果签名检查通过,则调用相关JNI方法。这种保护方式示意图见图3。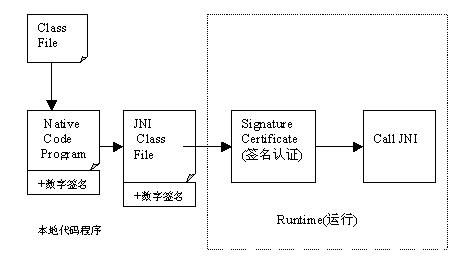
图3 转换成本地代码示意图
4. 代码混淆
代码混淆是对Class文件进行重新组织和处理,使得处理后的代码与处理前代码完成相同的功能(语义)。但是混淆后的代码很难被反编译,即反编译后得出的代码是非常难懂、晦涩的,因此反编译人员很难得出程序的真正语义。从理论上来说,黑客如果有足够的时间,被混淆的代码仍然可能被破解,甚至目前有些人正在研制反混淆的工具。但是从实际情况来看,由于混淆技术的多元化发展,混淆理论的成熟,经过混淆的Java代码还是能够很好地防止反编译。下面我们会详细介绍混淆技术,因为混淆是一种保护Java程序的重要技术。图4是代码混淆的示图。 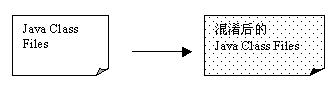
图4 代码混淆示意图
几种技术的总结
以上几种技术都有不同的应用环境,各自都有自己的弱点,表1是相关特点的比较。
混淆技术介绍
表1 不同保护技术比较表
到目前为止,对于Java程序的保护,混淆技术还是最基本的保护方法。Java混淆工具也非常多,包括商业的、免费的、开放源代码的。Sun公司也提供了自己的混淆工具。它们大多都是对Class文件进行混淆处理,也有少量工具首先对源代码进行处理,然后再对Class进行处理,这样加大了混淆处理的力度。目前,商业上比较成功的混淆工具包括JProof公司的1stBarrier系列、Eastridge公司的JShrink和 4thpass.com的SourceGuard等。主要的混淆技术按照混淆目标可以进行如下分类,它们分别为符号混淆(Lexical Obfuscation)、数据混淆(Data Obfuscation)、控制混淆(Control Obfuscation)、预防性混淆(Prevent Transformation)。
符号混淆
在Class中存在许多与程序执行本身无关的信息,例如方法名称、变量名称,这些符号的名称往往带有一定的含义。例如某个方法名为 getKeyLength(),那么这个方法很可能就是用来返回Key的长度。符号混淆就是将这些信息打乱,把这些信息变成无任何意义的表示,例如将所有的变量从vairant_001开始编号;对于所有的方法从method_001开始编号。这将对反编译带来一定的困难。对于私有函数、局部变量,通常可以改变它们的符号,而不影响程序的运行。但是对于一些接口名称、公有函数、成员变量,如果有其它外部模块需要引用这些符号,我们往往需要保留这些名称,否则外部模块找不到这些名称的方法和变量。因此,多数的混淆工具对于符号混淆,都提供了丰富的选项,让用户选择是否、如何进行符号混淆。
数据混淆

图5 改变数据访问
数据混淆是对程序使用的数据进行混淆。混淆的方法也有多种,主要可以分为改变数据存储及编码(Store and Encode Transform)、改变数据访问(Access Transform)。
改变数据存储和编码可以打乱程序使用的数据存储方式。例如将一个有10个成员的数组,拆开为10个变量,并且打乱这些变量的名字;将一个两维数组转化为一个一维数组等。对于一些复杂的数据结构,我们将打乱它的数据结构,例如用多个类代替一个复杂的类等。
另外一种方式是改变数据访问。例如访问数组的下标时,我们可以进行一定的计算,图5就是一个例子。
在实践混淆处理中,这两种方法通常是综合使用的,在打乱数据存储的同时,也打乱数据访问的方式。经过对数据混淆,程序的语义变得复杂了,这样增大了反编译的难度。
控制混淆
控制混淆就是对程序的控制流进行混淆,使得程序的控制流更加难以反编译,通常控制流的改变需要增加一些额外的计算和控制流,因此在性能上会给程序带来一定的负面影响。有时,需要在程序的性能和混淆程度之间进行权衡。控制混淆的技术最为复杂,技巧也最多。这些技术可以分为如下几类:
增加混淆控制通过增加额外的、复杂的控制流,可以将程序原来的语义隐藏起来。例如,对于按次序执行的两个语句A、B,我们可以增加一个控制条件,以决定B的执行。通过这种方式加大反汇编的难度。但是所有的干扰控制都不应该影响B的执行。图6就给出三种方式,为这个例子增加混淆控制。
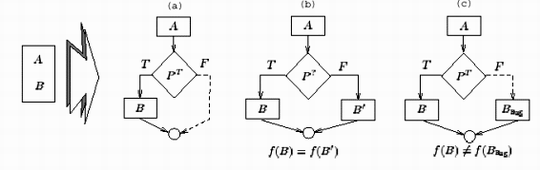
图6 增加混淆控制的三种方式
控制流重组重组控制流也是重要的混淆方法。例如,程序调用一个方法,在混淆后,可以将该方法代码嵌入到调用程序当中。反过来,程序中的一段代码也可以转变为一个函数调用。另外,对于一个循环的控制流,为可以拆分多个循环的控制流,或者将循环转化成一个递归过程。这种方法最为复杂,研究的人员也非常多。
预防性混淆
这种混淆通常是针对一些专用的反编译器而设计的,一般来说,这些技术利用反编译器的弱点或者Bug来设计混淆方案。例如,有些反编译器对于 Return后面的指令不进行反编译,而有些混淆方案恰恰将代码放在Return语句后面。这种混淆的有效性对于不同反编译器的作用也不太相同的。一个好的混淆工具,通常会综合使用这些混淆技术。
案例分析
在实践当中,保护一个大型Java程序经常需要综合使用这些方法,而不是单一使用某一种方法。这是因为每种方法都有其弱点和应用环境。综合使用这些方法使得Java程序的保护更加有效。另外,我们经常还需要使用其它的相关安全技术,例如安全认证、数字签名、PKI等。
本文给出的例子是一个Java应用程序,它是一个SCJP(Sun Certificate Java Programmer)的模拟考试软件。该应用程序带有大量的模拟题目,所有的题目都被加密后存储在文件中。由于它所带的题库是该软件的核心部分,所以关于题库的存取和访问就成为非常核心的类。一旦这些相关的类被反编译,则所有的题库将被破解。现在,我们来考虑如何保护这些题库及相关的类。
在这个例子中,我们考虑使用综合保护技术,其中包括本地代码和混淆技术。因为该软件主要发布在Windows上,因此转换成本地代码后,仅仅需要维护一个版本的本地代码。另外,混淆对Java程序也是非常有效的,适用于这种独立发布的应用系统。
在具体的方案中,我们将程序分为两个部分,一个是由本地代码编写的题库访问的模块,另外一个是由Java开发的其它模块。这样可以更高程度地保护题目管理模块不被反编译。对于Java开发的模块,我们仍然要使用混淆技术。该方案的示意图参见图7。

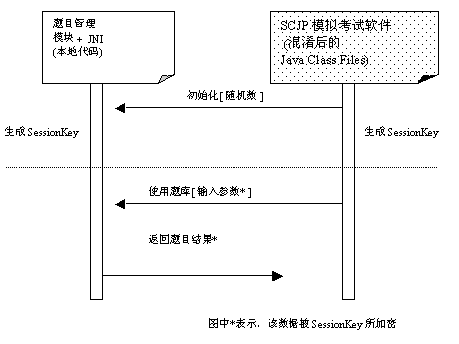
图7 SCJP保护技术方案图
对于题目管理模块,由于程序主要在Windows下使用,所以使用C++开发题库访问模块,并且提供了一定的访问接口。为了保护题库访问的接口,我们还增加了一个初始化接口,用于每次使用题库访问接口之前的初始化工作。它的接口主要分为两类:
1. 初始化接口
在使用题库模块之前,我们必须先调用初始化接口。在调用该接口时,客户端需要提供一个随机数作为参数。题库管理模块和客户端通过这个随机数,按一定的算法同时生成相同的SessionKey,用于加密以后输入和输出的所有数据。通过这种方式,只有授权(有效)的客户端才能够连接正确的连接,生成正确的 SessionKey,用于访问题库信息。非法的客户很难生成正确的SessionKey,因此无法获得题库的信息。如果需要建立更高的保密级别,也可以采用双向认证技术。
2. 数据访问接口
认证完成之后,客户端就可以正常的访问题库数据。但是,输入和输出的数据都是由SessionKey所加密的数据。因此,只有正确的题库管理模块才能够使用题库管理模块。图8时序图表示了题库管理模块和其它部分的交互过程。