1、了解搜索技术
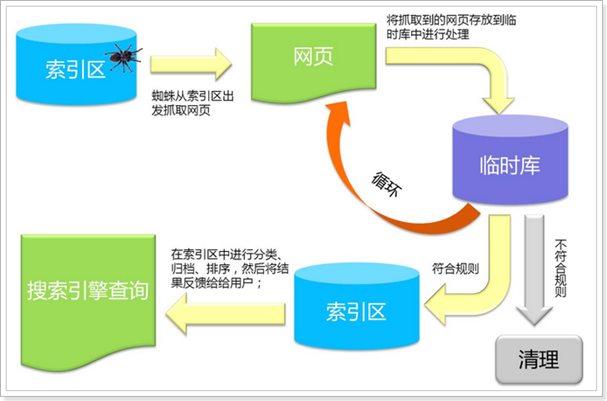
2、搜索引擎的原理
索引:类似于书的目录
3、实现搜索技术的方式
方式1:数据库搜索
利用SQL语句进行模糊搜索:
select * from items where title like “%上海%”;
select * from items where title like “上海%”;----走索引
问题:
在数据量很大的情况下,模糊搜索不一定走索引,因此效率就会很低。
方式2:Lucene技术
解决在海量数据的情况下,利用倒排索引技术,实现快速的搜索、打分、排序等功能
4、倒排索引技术

创建倒排索引,分为以下几步:
1)创建文档列表:
l lucene首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表

2)创建倒排索引列表
l 然后对文档中数据进行分词,得到词条(Term)。对词条进行编号,以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)。

拉斯跳槽 ---》拉斯、跳槽 –》0234
l 倒排索引创建索引的流程:
1) 首先把所有的原始数据进行编号,形成文档列表
2) 把文档数据进行分词,得到很多的词条,以词条为索引。保存包含这些词条的文档的编号信息。
l 搜索的过程:
1) 当用户输入任意的内容时,首先对用户输入的内容进行分词,得到用户要搜索的所有词条
2) 然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。
3) 然后根据这些编号去文档列表中找到文档
5、Lucene技术的增、删、改、查
1)导入依赖和插件
1 <dependencies> 2 <!-- Junit单元测试 --> 3 <dependency> 4 <groupId>junit</groupId> 5 <artifactId>junit</artifactId> 6 <version>4.12</version> 7 </dependency> 8 <!-- lucene核心库 --> 9 <dependency> 10 <groupId>org.apache.lucene</groupId> 11 <artifactId>lucene-core</artifactId> 12 <version>4.10.2</version> 13 </dependency> 14 <!-- Lucene的查询解析器 --> 15 <dependency> 16 <groupId>org.apache.lucene</groupId> 17 <artifactId>lucene-queryparser</artifactId> 18 <version>4.10.2</version> 19 </dependency> 20 <!-- lucene的默认分词器库 --> 21 <dependency> 22 <groupId>org.apache.lucene</groupId> 23 <artifactId>lucene-analyzers-common</artifactId> 24 <version>4.10.2</version> 25 </dependency> 26 <!-- lucene的高亮显示 --> 27 <dependency> 28 <groupId>org.apache.lucene</groupId> 29 <artifactId>lucene-highlighter</artifactId> 30 <version>4.10.2</version> 31 </dependency> 32 <!--IK分词器--> 33 <dependency> 34 <groupId>com.janeluo</groupId> 35 <artifactId>ikanalyzer</artifactId> 36 <version>2012_u6</version> 37 </dependency> 38 </dependencies> 39 40 41 <build> 42 <plugins> 43 <!-- java编译插件 --> 44 <plugin> 45 <groupId>org.apache.maven.plugins</groupId> 46 <artifactId>maven-compiler-plugin</artifactId> 47 <version>3.2</version> 48 <configuration> 49 <source>1.8</source> 50 <target>1.8</target> 51 </configuration> 52 </plugin> 53 </plugins> 54 </build>
2)创建索引
1 public class LuceneCreateTest { 2 @Test 3 public void testCreate() throws IOException { 4 //创建文档对象 5 Document document = new Document(); 6 7 //创建并添加字段信息,参数:字段的名称、字段的值、是否储存,这里选用Store.YES代表存储到文档列表 8 //Store.NO代表不存储 9 document.add(new StringField("id","1", Field.Store.YES)); 10 //这里的title字段需要用TextField,即创建索引又会被分词,StringField会创建索引,但是不会被分词 11 document.add(new TextField("title","谷歌之父跳槽facebook,屌爆了", Field.Store.YES)); 12 13 //索引目录类,指定索引在硬盘中的位置 14 Directory directory = FSDirectory.open(new File("indexDir")); 15 16 //创建分词器对象 17 // Analyzer analyzer = new StandardAnalyzer(); 18 //引用IK分词器 19 Analyzer analyzer = new IKAnalyzer(); 20 21 //索引写出工具的配置对象 22 IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST,analyzer); 23 //创建索引的写出工具类,参数:索引的目录和配置信息 24 IndexWriter indexWriter = new IndexWriter(directory,conf); 25 26 //把文档交给IndexWriter 27 indexWriter.addDocument(document); 28 29 //提交 30 indexWriter.commit(); 31 //关闭 32 indexWriter.close(); 33 }
3)批量创建索引
1 @Test 2 public void testCreate2() throws IOException { 3 //创建文档的集合 4 Collection<Document> docs = new ArrayList<>(); 5 6 //创建文档对象 7 Document document1 = new Document(); 8 document1.add(new StringField("id","1", Field.Store.YES)); 9 document1.add(new TextField("title","谷歌地图之父跳槽facebook", Field.Store.YES)); 10 docs.add(document1); 11 12 //创建文档对象 13 Document document2 = new Document(); 14 document2.add(new StringField("id","2", Field.Store.YES)); 15 document2.add(new TextField("title","谷歌地图创始人拉斯离开谷歌加盟Facebook", Field.Store.YES)); 16 docs.add(document2); 17 18 19 // 创建文档对象 20 Document document3 = new Document(); 21 document3.add(new StringField("id", "3", Field.Store.YES)); 22 document3.add(new TextField("title", "谷歌地图创始人拉斯离开谷歌加盟Facebook", Field.Store.YES)); 23 docs.add(document3); 24 25 // 创建文档对象 26 Document document4 = new Document(); 27 document4.add(new StringField("id", "4", Field.Store.YES)); 28 //document4.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Field.Store.YES)); 29 Field field = new TextField("title","谷歌地图之父跳槽Facebook与Wave项目取消有关", Field.Store.YES); 30 //设置激励因子,作弊 31 field.setBoost(10.0f); 32 document4.add(field); 33 docs.add(document4); 34 35 // 创建文档对象 36 Document document5 = new Document(); 37 document5.add(new StringField("id", "5", Field.Store.YES)); 38 document5.add(new TextField("title", "谷歌地图之父拉斯加盟社交网站Facebook", Field.Store.YES)); 39 docs.add(document5); 40 41 //索引目录类,指定索引在硬盘的位置 42 Directory directory = FSDirectory.open(new File("indexDir")); 43 44 //引入IK分词器 45 Analyzer analyzer = new IKAnalyzer(); 46 //索引写出工具的配置对象 47 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,analyzer); 48 49 //设置打开方式:openMode.APPEND会在索引的基础上追加新索引 50 config.setOpenMode(IndexWriterConfig.OpenMode.CREATE); 51 //创建索引的写出工具类,参数:索引的目录和配置信息 52 IndexWriter indexWriter = new IndexWriter(directory,config); 53 54 //把文档集合交给IndexWriter 55 indexWriter.addDocuments(docs); 56 //提交 57 indexWriter.commit(); 58 //关闭 59 indexWriter.close(); 60 }
4)删除索引
1 /* 2 * 删除索引 3 * 注意事项: 4 * 1、一般,为了进行精确删除,我们会根据唯一字段来删除,比如ID 5 * 2、如果是用Term删除,要求ID也必须是字符串类型 6 * */ 7 @Test 8 public void testDelete() throws IOException { 9 //创建目录对象 10 Directory directory = FSDirectory.open(new File("indexDir")); 11 //创建配置对象 12 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,new IKAnalyzer()); 13 //创建索引写出工具 14 IndexWriter writer = new IndexWriter(directory,config); 15 //根据词条进行删除 16 // writer.deleteDocuments(new Term("id","2")); 17 //根据query对象删除,如果ID是数值类型,那么我们可以用数值范围查询锁定一个具体的ID 18 // Query query = NumericRangeQuery.newLongRange("2d",2L,2L,true,true); 19 //// writer.deleteDocuments(query); 20 21 //删除所有 22 writer.deleteAll(); 23 //提交 24 writer.commit(); 25 //关闭 26 writer.close(); 27 }
5)查询索引
1 @Test 2 public void testSearch() throws IOException, ParseException { 3 //索引目录对象 4 Directory directory = FSDirectory.open(new File("indexDir")); 5 6 //索引读取工具 7 IndexReader reader = DirectoryReader.open(directory); 8 //索引搜索工具 9 IndexSearcher indexSearcher = new IndexSearcher(reader); 10 11 //索引查询解析器,两个参数:默认要查询字段的名称、分词器 12 // QueryParser parser = new QueryParser("title",new IKAnalyzer()); 13 14 //多字段查询解析器 15 QueryParser parser = new MultiFieldQueryParser(new String[]{"id","title"},new IKAnalyzer()); 16 //创建查询对象 17 Query query = parser.parse("硅谷地图之父拉斯"); 18 19 //搜索数据,两个参数:查询条件对象,要查询的最大结果条数(总共就5个文档,如果不知道文档数据数据,也可以 20 //使用Integer.MAX_VALUE) 21 //返回的结果是 按照匹配度排名得分前N名的文档信息(包括查询到的总条数信息、所有符合条件的文档的编号信息) 22 //topDocs:两个属性:总记录数、文档数组 23 TopDocs topDocs = indexSearcher.search(query,10); 24 25 //获取总条数 26 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); 27 //获取得分文档对象(ScoreDoc)数组 ScoreDao中包含:文档的编号、文档的得分 28 ScoreDoc[] scoreDocs = topDocs.scoreDocs; 29 for (ScoreDoc scoreDoc : scoreDocs) { 30 //取出文档编号 31 int docID = scoreDoc.doc; 32 //根据编号去找文档 33 Document document = reader.document(docID); 34 35 System.out.println("id" + document.get("id")); 36 System.out.println("title" + document.get("title")); 37 38 //取出文档得分 39 System.out.println("得分:" + scoreDoc.score); 40 }
6)为了查询的方便,可以把上边的公共的部分代码抽取出来
1 //抽取公共的方法,提取一个查询数据的通用方法 2 public void search(Query query) throws IOException { 3 //索引目录对象 4 Directory directory = FSDirectory.open(new File("indexDir")); 5 6 //索引读取对象 7 IndexReader reader = DirectoryReader.open(directory); 8 //索引搜索工具 9 IndexSearcher searcher = new IndexSearcher(reader); 10 11 //搜索数据,两个参数:查询条件对象,要查询的最大结果条数 12 //返回的结果是 按照匹配度排名得分前N名的文档信息(包括查询到的总条数信息、所有符合条件的文档的编号信息) 13 //topDocs:两个属性:总记录数、文档数组 14 15 TopDocs topDocs = searcher.search(query,10); 16 //获取总条数 17 System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据"); 18 //获取得分文档对象 19 ScoreDoc[] scoreDocs = topDocs.scoreDocs; 20 for (ScoreDoc scoreDoc : scoreDocs) { 21 //取出文档编号 22 int docID = scoreDoc.doc; 23 //根据编号去找文档 24 Document doc = reader.document(docID); 25 System.out.println("id: " + doc.get("id")); 26 System.out.println("title: " + doc.get("title")); 27 //取出文档得分 28 System.out.println("得分:" + scoreDoc.score); 29 } 30 } 31 /** 32 * 测试普通词条查询 33 * 注意:Term(词条)是搜索的最小单位,不可在分词,值必须是字符串 34 * 一般用来搜索唯一字段,比如ID(对不需要分词的关键字进行查询) 35 * @throws IOException 36 */ 37 @Test 38 public void testTermQuery() throws IOException { 39 //创建词条查询对象 40 Query query = new TermQuery(new Term("title","谷歌地图")); 41 search(query); 42 } 43 44 /* 45 * 通配符查询 46 * ? 可以代表任意一个字符 47 * * 可以任意多个任意字符 48 * */ 49 @Test 50 public void testWildCardQuery() throws IOException { 51 //创建查询对象 52 Query query = new WildcardQuery(new Term("title","*歌*")); 53 search(query); 54 } 55 56 /* 57 * 模糊查询 58 * 59 * */ 60 @Test 61 public void testFuzzyQuery() throws IOException { 62 //创建模糊查询对象:允许用户输错,但是要求错误的最大编辑距离不能超过2 63 //编辑距离:一个单词到另一个单词最少修改的次数 64 //可以手动指定编辑距离,但是参数必须在0~2之间 65 Query query = new FuzzyQuery(new Term("title","facevool"),2); 66 search(query); 67 } 68 69 70 /* 71 * 数值范围查询 72 * 注意:数值范围查询,可以用来对非String类型的ID进行精确的查找 73 * */ 74 @Test 75 public void testNumericRangeQuery() throws IOException { 76 //数值范围查询对象,参数:字段名称,最小值、最大值、是否包含最小值、是否包含最大值 77 Query query = NumericRangeQuery.newLongRange("id",2L,2L,true,true); 78 search(query); 79 } 80 81 /* 82 * 布尔查询 83 * 布尔查询本身没有查询条件,可以把查询通过逻辑运算进行组合! 84 * 交集:Occur.MUST + Occur.MUST 85 * 并集:Occur.SHOULD + Occur.SHOULD 86 * 非:Occur.MUST 87 * */ 88 @Test 89 public void testBooleanQuery() throws IOException { 90 Query query1 = NumericRangeQuery.newLongRange("id",1L,3L,true,true); 91 Query query2 = NumericRangeQuery.newLongRange("id",2L,4L,true,true); 92 93 // 创建布尔查询的对象 94 BooleanQuery query = new BooleanQuery(); 95 // 组合其它查询 96 query.add(query1, BooleanClause.Occur.MUST_NOT); 97 query.add(query2, BooleanClause.Occur.SHOULD); 98 99 search(query); 100 101 }
7)修改索引
1 public class LuceneUpdate { 2 /* 3 * 修改索引 4 * 注意事项: 5 * 1、Lucene修改功能底层会先删除,再把新的文档添加 6 * 2、修改功能会根据Term进行匹配,所有匹配到的都会被删除,这样不好 7 * 3、因此,一般我们修改时,都会根据一个唯一不重复字段进行匹配修改,例如ID 8 * 4、但是词条搜索,要求ID必须是字符串,如果不是,这个方法就不能用 9 * 10 * 如果ID是数值类型,我们不能直接去修改,可以先手动删除deleteDocument(数值范围查询锁定ID)。再添加 11 * */ 12 13 @Test 14 public void testUpdate() throws IOException { 15 //创建目录对象 16 Directory directory = FSDirectory.open(new File("indexDir")); 17 18 //创建配置对象 19 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,new IKAnalyzer()); 20 21 //创建索引写出工具 22 IndexWriter writer = new IndexWriter(directory,config); 23 //创建新的文档数据 24 Document doc = new Document(); 25 doc.add(new StringField("id","1", Field.Store.YES)); 26 doc.add(new TextField("title","谷歌地图之父跳槽facebook为了加入传智播客 屌爆了呀", Field.Store.YES)); 27 28 29 /* 30 * 修改索引,参数 31 * 词条:根据这个词条匹配到的所有的文档都会被修改 32 * 文档信息:要修改的新的文档数据 33 * */ 34 35 writer.updateDocument(new Term("id","1"),doc); 36 //提交 37 writer.commit(); 38 //关闭 39 writer.close(); 40 }