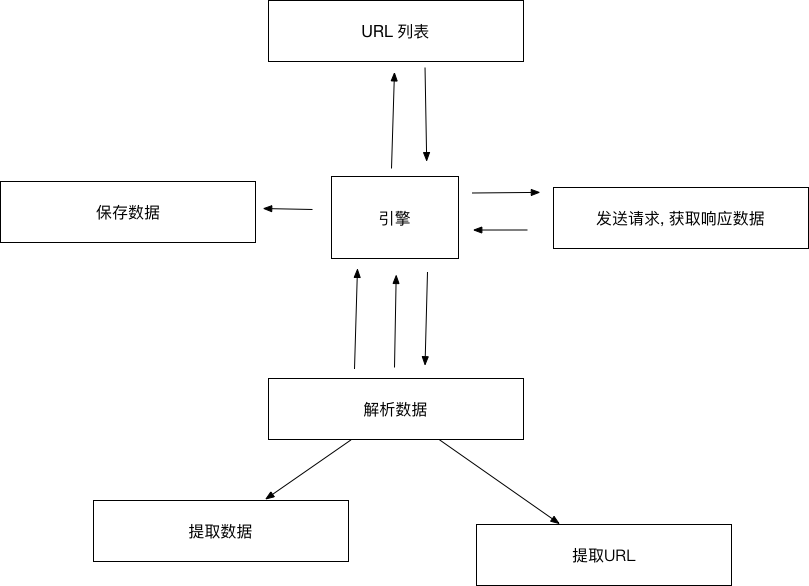
scrapy的运行流程
- 爬虫 -> 起始URL封装Request -> 爬虫中间件 -> 引擎 -> 调度器(Scheduler): 缓存请求, 请求去重
- 调度器 -> 请求 -> 引擎 -> 经过下载器中间件 -> 下载器(发送请求, 获取响应数据, 封装Response)
- 下载器 - Response(响应) -> 经过下载器中间件 -> 引擎
- 引擎 - response -> 经过爬虫中间件 -> 爬虫 (解析数据, 提取URL封装请求, 提取数据)
- 爬虫:
- 提取URL封装请求 -> 爬虫中间件 -> 引擎 -> 调度器
- 提取数据 -> 引擎 -> 管道(Pipeline: 处理数据, 比如保存)
各个模块及作用:
爬虫模块:
- 构建起始请求 2. 响应数据解析(1. 提取URL封装请求, 2. 提取数据) (需要自己写)
调度器模块:
- 缓存请求 2. 请求去重 (已经实现了)
下载器模块:
发送请求, 获取响应数据,封装为Response(已经实现了)
管道模块:
处理数据, 比如保存(需要自己写)
引擎模块:
总指挥: 负责模块之间调度, 以及数据传递(已经实现了)
下载器中间件:
在引擎和下载器之间, 可以对请求和响应数据进行处理, 比如: 实现随机代理IP, 随机User-Agent
爬虫中间件:
爬虫和引擎之间, 可以对请求和响应数据进行处理, 比如过滤. (很少)