一、Map端Join
可连接两个都非常大的数据集之间可使用map端连接,数据在到达map端之前就执行连接操作。
需满足:
两个要连接的数据集都先划分成相同数量的分区,相同的key要保证在同一分区中(每个分区中两个数据集数据量不一定要要相同), 并且要 按连接key排序;
利用CompositeInputFormat类,可实现map端连接:
代码参考:GitHub上Join示例
其它参考:hadoop实现join (CompositeInputFormat)
二、Reduce端连接
Reduce端连接更简单易用,以天气连接为例:
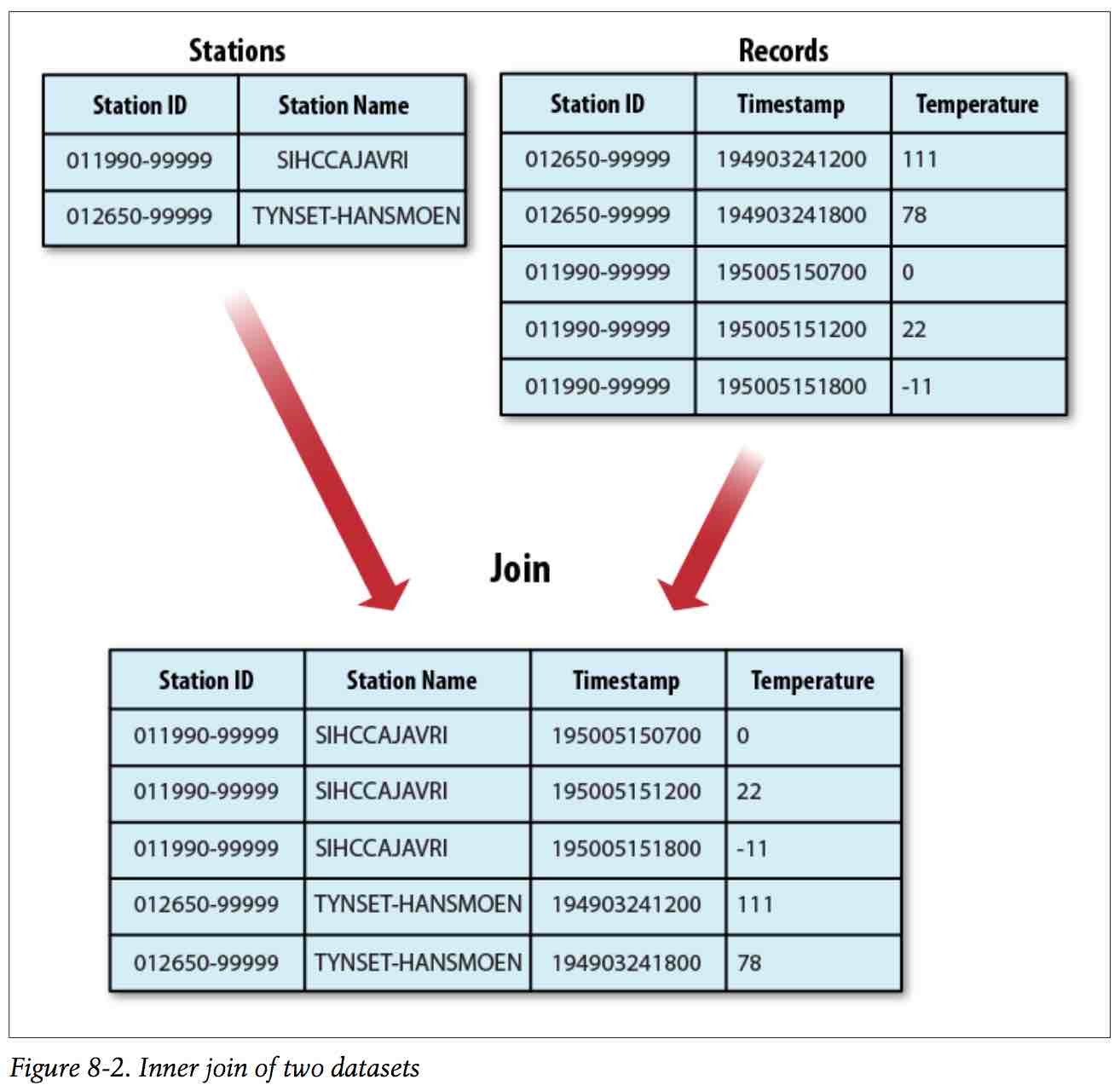
使用步骤:
1、使用MutipleInputs类设定不同输入数据集的InputFormat,以及Mapper;
2、辅助排序:通过自定义一个WritableComparable类型的 T,添加一个辅助排序字段,重写compareTo()方法,
作为传入Reducer的key,可完成可控的二次排序;
3、自定义Partitioner类,保证以自定义WritableComparable类型的T以首字段进行分区;自定一个分组Comparator类;
job.setPartitionerClass(KeyPartitioner.class); job.setGroupingComparatorClass(TextPair.FirstComparator.class);
自定义Partitioner类、Comparator:


public static class KeyPartitioner extends Partitioner<TextPair, Text> { @Override public int getPartition(TextPair key, Text value, int numPartitions) { return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions; } } public static class FirstComparator extends WritableComparator { private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator(); public FirstComparator() { super(TextPair.class); } @Override public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { try { int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1); int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2); return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2); } catch (IOException e) { throw new IllegalArgumentException(e); } } @Override public int compare(WritableComparable a, WritableComparable b) { if (a instanceof TextPair && b instanceof TextPair) { return ((TextPair) a).first.compareTo(((TextPair) b).first); } return super.compare(a, b); } }
3、在Reducer中把选到达的key提取出来,即可自定义完成Join操作;
三、使用分布式缓存来实现: