- 安装 DRF
- pip install djangorestframework
-
setting 配置文件中注册 rest_frameworkINSTALLED_APPS = ['rest_framework',]
- 官方参考文档(FQ才能看)
- 级联数据 ondelete 属性
- a_user = models.ForeignKey(UserModel,on_delete=models.SET_NULL)
-
级联删除:models.CASCADE当关联表中的数据删除时,该外键也删除
-
置空:models.SET_NULL当关联表中的数据删除时,该外键置空,当然,你的这个外键字段得允许为空,null=True
-
设置默认值:models.SET_DEFAULT删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
-
设置默认值:models.PROTECT 删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
-
- 项目目录与app目录
-
-
项目目录与app目录
-
相同点:都有一个包 __init__.py
-
不同点
-
项目:
-
在项目一级目录存在一个用于控制的manage.py 文件
-
setting 文件,存放各种配置
-
urls.py 主路由
-
asgi.py 使用ASGI部署
-
wsgi.py 使用wsgi 进行部署
-
APP
-
存在用户后台管理注册的admin.py 文件,将需要管理的模型在 admin 中注册就可使用界面管理
-
apps.py,--需要将此文件中的类在setting 中install app 中进行注册
-
migrations / __init__.py 迁移文件每次执行 makemigrations,base 前一个迁移文件,进行差量更新,在数据库中也有表记录迁移,若模型需要重新迁移,报错时,要删除所有迁移文件和数据库中的迁移记录
-
models.py 创建数据库模型
-
tests.py 用于测试
-
views.py 用于逻辑控制
-
-
- 响应
- from django.http import HttpResponse return HttpResponse(message)
- 路由
-
-
子路由 from django.urls import path urlpatterns = [ path('',views.index,name='index'),] 多个path list
-
主路由:from django.urls import path,include urlpatterns = ['polls',include('polls.urls'),path('admin/', admin.site.urls),] 多个pathist ,include 里面的用单引号,不用导入模块
-
-
- path 参数
-
-
函数 path() 具有四个参数,两个必须参数:route 和 view,两个可选参数:kwargs 和 name。现在,是时候来研究这些参数的含义了
-
path()参数:route 匹配URL,类正则表达式,依次匹配列表中的项,直到找到匹配项,不包括参数
-
path()参数:View,找到匹配的正则后,调用view视图函数,并传入一个HttpResponse对象作为第一个参数,被捕获 的参数以关键字的形式传入
-
path()参数:kwargs 任意个关键字参数可以作为一个字典传递给目标视图函数
-
path()参数:name ,为当前url 取名,使能在Django 的任意地方唯一地引用它,尤其在模板中,仅需改一个地方,就能全局修改某个URL模式
-
-
- Django 的自带应用
-
-
django.contrib.admin -- 管理员站点
- django.contrib.auth -- 认证授权系统。
- django.contrib.contenttypes -- 内容类型框架。
- django.contrib.sessions -- 会话框架。
- django.contrib.messages -- 消息框架。
- django.contrib.staticfiles -- 管理静态文件的框架。
-
-
- API shell ---python manage.py shell
- 我们使用这个命令而不是简单的使用 "Python" 是因为 manage.py 会设置 DJANGO_SETTINGS_MODULE环境变量,这个变量会让 Django 根据 mysite/settings.py 文件来设置 Python 包的导入路径
- 创建模型
- 继承models.Model
- u_name = models.CharFiled(max_lenth=70)
- User.objects.all() --queryset 对象
- User.objects.values() 表里所有的值
- user=User(name ="qqq") u.save() 增加一条记录
- user.id 返回 对象主键
- user.name
- user.name="88" user.sqve()
- User.objects.filter(id=1)
- User.objects.get(id=1) 如果结果不存在会报错
- user=User.objects.get(pk=1)
-
user.choice_set.create(choice_text="111",votes=0) choice_set为隐性属性 user.choice_set.count()
- 模型字段类型
-
- https://docs.djangoproject.com/zh-hans/3.0/ref/models/fields/#model-field-types
- Field 是数据库表列的抽象类
- Field.null允许为空,代替为nulln
- Field.blank,允许为空,代替为False ,black=True
- Field.choices choices=[''''''']
- def contact_default():
-
return {"email": "to1@example.com"}contact_info = JSONField("ContactInfo", default=contact_default)
-
primary_key=True暗示null=False和 unique=True。一个对象只允许使用一个主键。
-
- 模型字段细分类型
-
-
AutoField IntegerField ID自动递增,默认会包含id这个字段
-
BigAutoField 64位整数 1 到9223372036854775807 默认表单小部件是 NumberInput
-
BigIntegerField 个64位整数,IntegerField不同之处在于它保证可以匹配从-9223372036854775808到的 数字9223372036854775807
-
BooleanField True False
-
CharField(max_length = None,**options) 字符串类型, 对于大量文本,请使用TextField。
-
DateField(auto_now = False,auto_now_add = False,** options), auto_now :每次保存对象时自动将字段设置为现在。对于“最后修改的”时间戳有用
-
auto_now_add 首次创建对象时,将字段自动设置为现在
-
DateTimeField(auto_now = False,auto_now_add = False,** options)
-
DateTimeField(auto_now=False, auto_now_add=False, **options)
-
DecimalField(max_digits=None, decimal_places=None, **options)
-
models.DecimalField(..., max_digits=19, decimal_places=10)
-
DurationField(**options) 计算时间差
-
EmailField(max_length=254, **options) 使用CharField来检查该值是否是有效的电子邮件地址的 EmailValidator
-
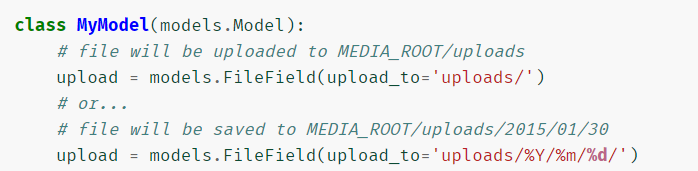
FileField(upload_to=None, max_length=100, **options)¶此属性提供了一种设置上传目录和文件名的方法,
-
-
-
过滤路径文件名 FilePathField(path ='',match = None,递归= False,allow_files = True,allow_folders = False,max_length = 100,** options)
-
FilePathField(path="/home/images", match="foo.*", recursive=True)
-
FloatField(** options)
-
ImageField(upload_to = None,height_field = None,width_field = None,max_length = 100,** options)
-
IntegerField(** options)
-
一个整数。从-2147483648到的值2147483647在Django支持的所有数据库中都是安全的
-
IP GenericIPAddressField(protocol ='both',unpack_ipv4 = False,** options)
-
正数
-
PositiveIntegerField(** options) 从0到的值2147483647在Django支持的所有数据库中都是安全的
-
特定点以下的数字
-
PositiveSmallIntegerField(** options)
-
仅包含字母,数字,下划线或连字符,它们通常在URL中使用。 SlugField(max_length = 50,** options
-
文本
-
TextField(** options
-
一个CharField一个URL,通过验证 URLValidator URLField(max_length = 200,** options)
-
用于存储通用唯一标识符的字段。使用Python的 UUID类 UUIDField(** options)
-
-
-
关联关系变量
-
-
多对一的关系
-
ForeignKey(to,on_delete,** options)
-
自身本身有多对一关系的对象-则使用。models.ForeignKey('self',on_delete=models.CASCADE)
-
on_delete
-
CASCAND 级联删除
-
PROTECT 不允许删除
-
SET_NULL
-
SET_DEFAULT ForeignKey必须设置默认值
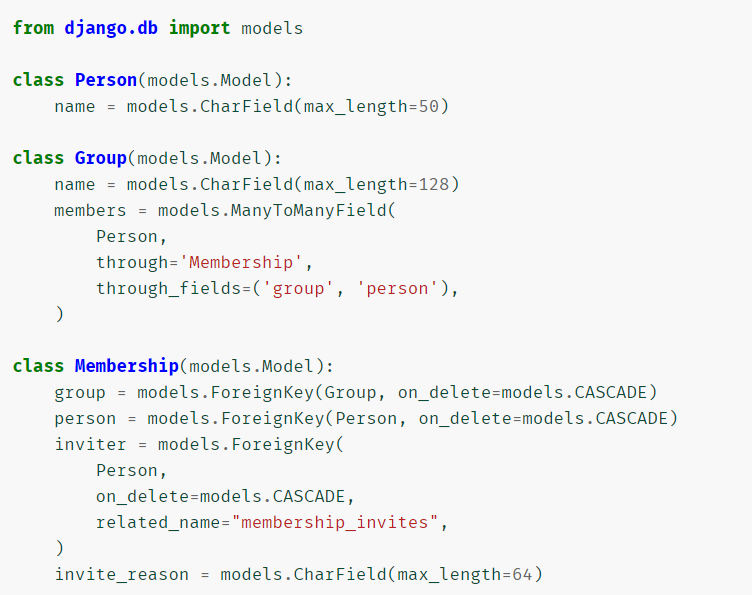
- ManyToManyField
- 在幕后,Django创建了一个中间联接表来表示多对多关系
- 自身多对多

- 此类可用于查询给定模型实例(如普通模型)的关联记录:Model.m2mfield.through.objects.all()
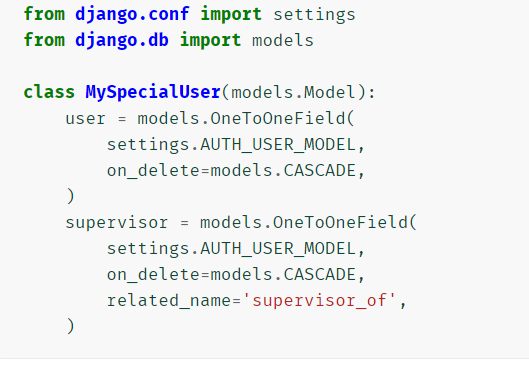
- 一对一 OneToOneField(to,on_delete,parent_link = False,** options) ,这与ForeignKeywith 相似 unique=True,但是关系的“反向”侧将直接返回单个对象
-
-
-
Meta属性
- 使用内部Meta 类,赋予元数据

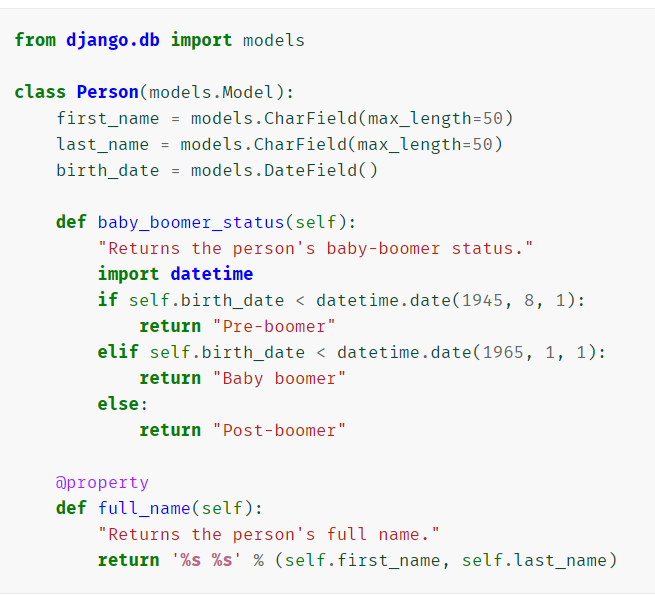
- 模型方法
- 自定义方法 - -不会在批量操作中调用
-
重构已存在的方法--- 重写的模型方法不会在批量操作中调用
- 执行原生SQL Manager.raw(raw_query, params=None, translations=None)
-
模型继承
-
抽象基类--抽象基类在你要将公共信息放入很多模型时会很有用
-
编写你的基类,并在 Meta 类中填入 abstract=True。该模型将不会创建任何数据表。当其用作其它模型类的基类时,它的字段会自动添加至子类
-

-
Meta 继承
-

-
若父类中有ralated name 当你在抽象基类中(也只能是在抽象基类中)使用 related_name 和 related_query_name,部分值需要包含 '%(app_label)s' 和 '%(class)s'
-
- 多表继承
-
继承与反向关系
-
多表继承使用隐式的 OneToOneField 连接子类和父类,所以直接从父类访问子类是可能的
-
如上所述,Django 会自动创建一个 OneToOneField ,将子类连接回非抽象的父类。如果你想修改连接回父类的属性名,你可以自己创建 OneToOneField,并设置 parent_link=True,表明该属性用于连接回父类。
-
-
-
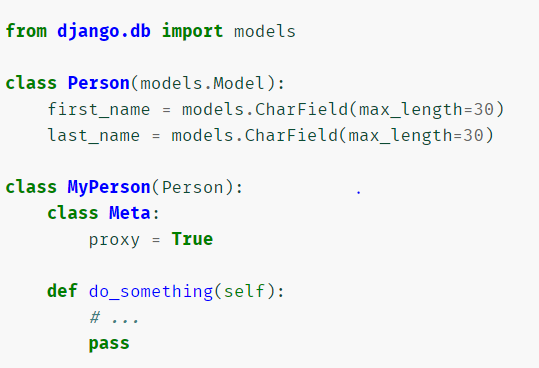
代理模型
-
使用 多表继承 时,每个子类模型都会创建一张新表,修改改代理表不会影响原表
-
可增加父类没有的字段
-
proxy = True
-
存在的全部意义是帮你复用原 Person 提供的代码和自定义的功能代码(并未依赖其它代码)
-
-
-
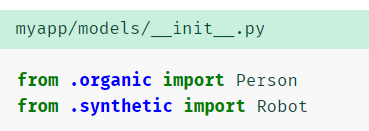
在一个包中管理模型
-
若有多个models.py 文件,建一个models 包,在__init__.py 中显示地导入这些模块
-
-
-
后台管理员
-
python manage.py createsuperuser
-
在app 的admin 中注册需要被管理的模型
-
from django.contrib import admin
-
from .models import Question
-
admin.site.register(Question)
-
可通过界面对数据库进行修改
-
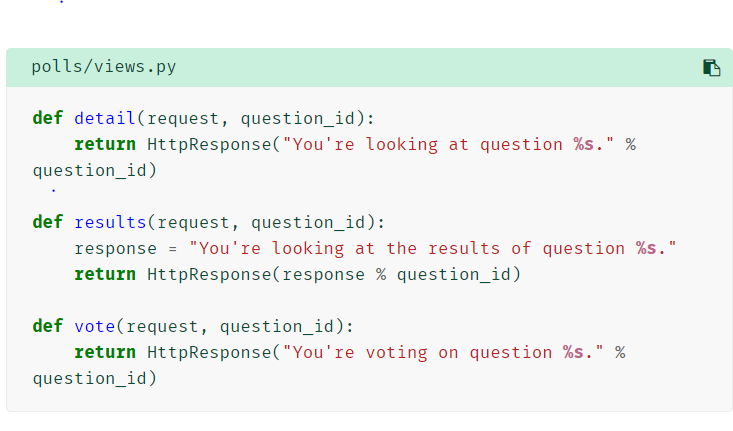
可接收参数的视图函数
-
-
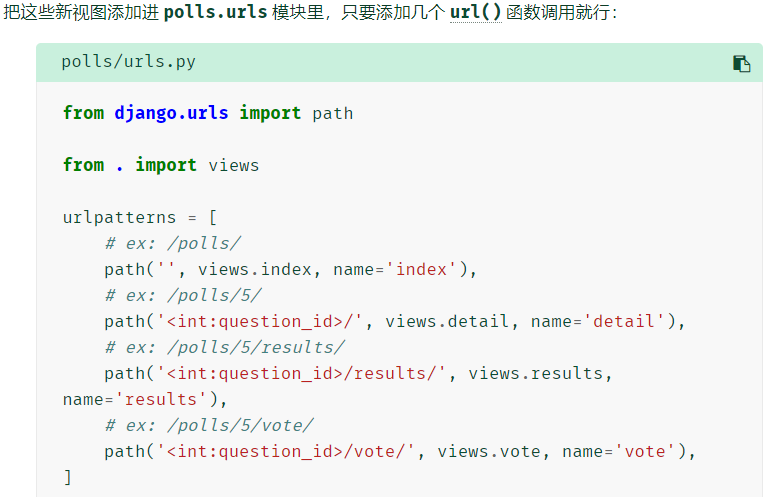
-
Django 将会运行 detail() 方法并且展示你在 URL 里提供的问题 ID。再试试 "/polls/34/vote/" 和 "/polls/34/vote/" ——你将会看到暂时用于占位的结果和投票页。 在这里剩余文本匹配了 '<int:question_id>/',使得我们 Django 以如下形式调用 detail():
-
detail(request=<HttpRequest object>, question_id=34) question_id=34 由 <int:question_id> 匹配生成。使用尖括号“捕获”这部分 URL,且以关键字参数的形式发送给视图函数
-
发布日期排序的最近 5 个投票问题,以空格分割:
-
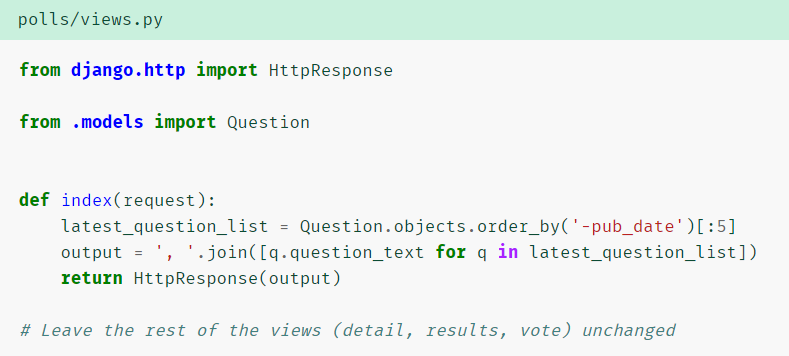
-
-
template 模板文件
-
在你的 polls 目录里创建一个 templates 目录。Django 将会在这个目录里查找模板文件
-
刚刚创建的 templates 目录里,再创建一个目录 polls, 新建一个文件 index.html
-
使用render渲染
-
-
- request.POST
-
- 字典对象 request.POST['choice'] ,返回的是字符串
- 数据中没有提供 choice , POST 将引发一个 KeyError
- selected_choice = question.choice_set.get(pk=request.POST['choice'])
-
- Reverse
- HttpResponseRedirect 的构造函数中使用 reverse() 函数。这个函数避免了我们在视图函数中硬编码 URL--- return
- HttpResponseRedirect(reverse('polls:results', args=(question.id,))) 返回'/polls/3/results/'
- HttpResponseRedirect 的构造函数中使用 reverse() 函数。这个函数避免了我们在视图函数中硬编码 URL--- return
-
代码重构,改良
- url,精准匹配模式变为<id>

- 视图
- 测试代码
- 运行测试
-
- python manage.py test polls
- python manage.py test polls 将会寻找 polls 应用里的测试代码
- 它找到了 django.test.TestCase 的一个子类
- 它创建一个特殊的数据库供测试使用
- 它在类中寻找测试方法——以 test 开头的方法。
- 在 test_was_published_recently_with_future_question 方法中,它创建了一个 pub_date 值为 30 天后的 Question 实例。
- 接着使用 assertls() 方法,发现 was_published_recently() 返回了 True,而我们期望它返回 False。
-
- 部署清单
-
执行查询
- 创建对象
- b = Blog(name='Beatles Blog', tagline='All the latest Beatles news.') b.save(),执行insert
- 修改对象
- 、b5.name = 'New name' b5.save() 执行update
- 更新Foreignkey 字段
- 例子

- 更新 ManyToManyField 使用add()方法为其添加一条记录

-
检索对象 --Queryset 方法
- 通过模型类的 Manager 构建一个 QuerySet
- QuerySet 对应 SELECT 语句,而*filters*对应类似 WHERE 或 LIMIT 的限制子句。
- Blog.objects.all() 返回了一个 QuerySet,后者包含了数据库中所有的 Blog 对象。
- queryset 是惰性的
- 创建QuerySet 并不会发起任何数据活动,直到需要结果的时候才会被一起执行
- all()检索全部对象 副本
- filter过滤查询
filter(**kwargs)返回一个新的QuerySet,包含的对象满足给定查询参数。q1 = Entry.objects.filter(headline__startswith="What")- exclude
exclude(**kwargs)返回一个新的QuerySet,包含的对象 不 满足给定查询参数>>> q2 = q1.exclude(pub_date__gte=datetime.date.today())- get()检索单个对象
- one_entry = Entry.objects.get(pk=1)
- Entry.objects.get(blog=blog, entry_number=1)
- Entry.objects.filter(pk=1).get()
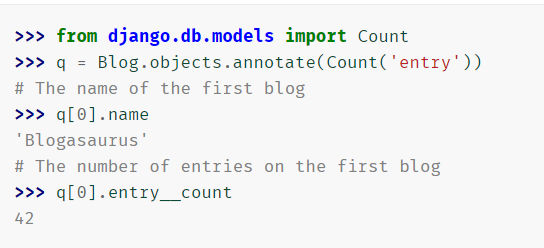
- annotate(*args,**kwargs) 聚合表达式(平均值,总和等
- order_by(* fields)
- Entry.objects.filter(pub_date__year=2005).order_by('-pub_date', 'headline') pub_date降序排列,然后按 headline升序排列
- 通过调用或在表达式上按查询表达式进行排序:asc()desc()
- Entry.objects.order_by(Coalesce('summary', 'headline').desc())
- reverse()
- 可以反转查询集元素的返回顺序
- 要检索查询集中的“最后”五个项目my_queryset.reverse()[:5]
- distinct(*fields)
- Entry.objects.order_by('pub_date').distinct('pub_date')
- values(*fields,**expressions)
- 返回QuerySet用作迭代器时返回的字典,而不是模型实例
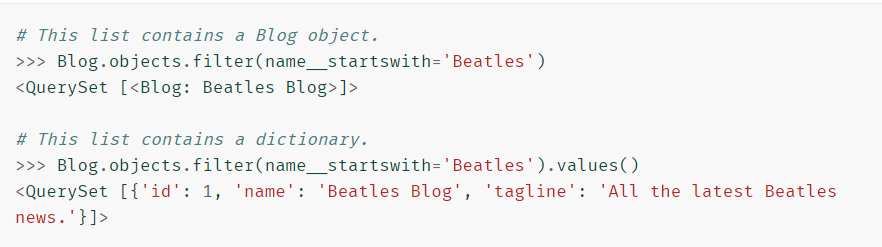
- 该values()方法采用可选的位置参数

- valude_list(*fields,flat=False,named=False)
- 返回的结果是由元组组成的list
- >>> Entry.objects.values_list('id', 'headline')<QuerySet [(1, 'First entry'), ...]>
- dates(field,kind,order ='ASC')
- 返回QuerySet,其结果是datetime.date 代表对象列表的对象
- datetimes(field_name,kind,order ='ASC',tzinfo = None)
- none()
- 调用none()将创建一个查询集,该查询集从不返回任何对象,并且在访问结果时将不执行任何查询
- union(* other_qs,all = False)
- 用SQL的UNION运算符组合两个或多个QuerySets 的结果
- qs1.union(qs2, qs3)
- intersection(* other_qs
- 使用SQL的INTERSECT运算符返回两个或多个QuerySets 的共享元素
- qs1.intersection(qs2, qs3)
- difference(* other_qs)
- 保留不同的
- select_related(* fields)
- 返回一个QuerySet将“遵循”外键关系的,在执行查询时选择其他相关对象数据
- 仅限于单值关系-外键和一对一关系。
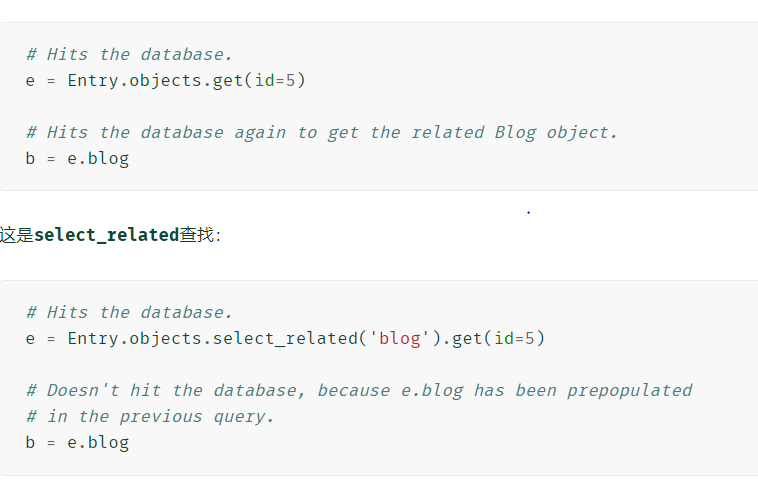
- 可以在传递给的字段列表中引用任何ForeignKey或 OneToOneField关系select_related()。
- prefetch_related(* lookups)
- 返回一个QuerySet,它将自动为每个指定的查询单批检索相关对象。
- 预取多对多和多对一对象

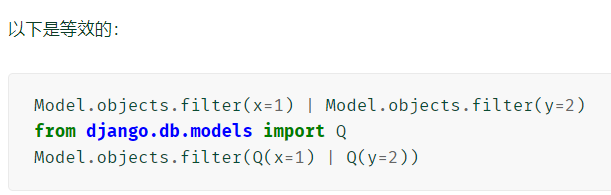
- 使用and(&)运算符合并两个QuerySet

- 使用or(|)合并两个QuerySet
- create(** kwargs)
- 一种方便的方法,可一步创建对象并将其全部保存

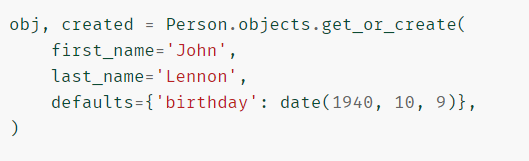
- get_or_create(default= None,** kwargs)
- update_or_create(默认值= None,** kwargs)
- 尝试根据给定的值从数据库中获取对象kwargs。如果找到匹配项,它将更新defaults字典中传递的字段 。

- bulk_create(OBJ文件,的batch_size =无,ignore_conflicts =假)
- 以一种有效的方式将所提供的对象列表插入数据库(通常只有1个查询,无论有多少个对象)

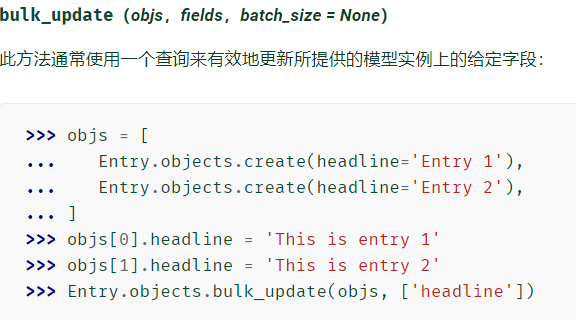
- bulk_update(objs,fields,batch_size = None
- count()
- 返回一个整数,该整数表示数据库中与匹配的对象数QuerySet。

- in_bulk(id_list = None,field_name ='pk')
- 获取字段值(id_list)和field_name这些值的列表,然后返回将每个值映射到具有给定字段值的对象实例的字典。如果id_list未提供,则返回queryset中的所有对象。field_name必须是唯一字段,并且默认为主键。

- iterator(chunk_size = 2000)
- 评估QuerySet(通过执行查询)并返回迭代器
- QuerySet通常,A在内部缓存其结果,以使重复的求值不会导致其他查询。相反,iterator()将直接读取结果,而不进行任何QuerySet级别的缓存
- latest(* fields) earliest(* fields)
- 根据给定的字段返回表中的最新对象
- Entry.objects.latest('pub_date')
- latest()除方向改变外,其他操作方式相同。
- first(),last()
- 返回与查询集匹配的第一个对象,或者None没有匹配的对象。

- aggregate(* args,** kwargs)
- 返回在上计算的汇总值(平均值,总和等)的字典QuerySet
- >>> from django.db.models import Count>>> q = Blog.objects.aggregate(Count('entry')){'entry__count': 16}
- exists()
- 返回true or false

- u pdate(** kwargs) 返回匹配的行数
- 要关闭对2010年发布的所有博客条目的评论
- Entry.objects.filter(pub_date__year=2010).update(comments_on=False)
- delete()

- 其他的queryset 方法
- defer(* fields)
- 将不加载的字段名称传递给来完成defer()
- Entry.objects.defer("headline", "body")
- only(* fields)
- 如果您有一个模型,其中几乎所有字段都需要延迟,那么使用 only()指定字段的补充集可以简化代码。
- Person.objects.only("name")
- using(别名)
- uerySet如果您使用多个数据库,则此方法用于控制将针对哪个数据库进行评估。该方法采用的唯一参数是数据库的别名
- Entry.objects.using('backup')
- raw(raw_query,params = None,translations = None)
- 执行原生SQL
- as_manager()
- 传回的实例的Class方法,Manager 其中包含QuerySet方法的副本
- explain(format = None,** options)
- 返回QuerySet的执行计划的字符串,该字符串详细说明数据库如何执行查询,包括将使用的所有索引或联接。了解这些详细信息可能有助于您提高慢查询的性能。

-
Field查找
- filter(), exclude()和get()。的参数
- exact --完全符合
- Entry.objects.get(id__exact=14)
- iexact -- 不区分大小写完全匹配
- contains --区分大小写的包含 like
- Entry.objects.get(headline__contains='Lennon')
- SELECT ... WHERE headline LIKE '%Lennon%';
- icontains --不区分大小写 包含 ilike
- Entry.objects.get(headline__icontains='Lennon')
- SELECT ... WHERE headline ILIKE '%Lennon%';
- in 在给定迭代中
- Entry.objects.filter(id__in=[1, 3, 4])Entry.objects.filter(headline__in='abc')
- gt --greate than
- Entry.objects.filter(id__gt=4)
- SELECT ... WHERE id > 4;
- gte >=
- lt <
- lte <=
- startwith 区分大小写的开头为
- istartwith 不区分大小写的开头为
- endwith
- idendwith
- range 等效于between and

- data 对于日期时间字段,将值强制转换为日期
- 类似 year month....
- isnull
- Entry.objects.filter(pub_date__isnull=True)
- regex 区分大小写的正则表达式匹配。
- Entry.objects.get(title__regex=r'^(An?|The) +')
- SELECT ... WHERE title REGEXP BINARY '^(An?|The) +'; -- MySQL
- iregex 不区分大小写的正则表达式匹配。
- expressions 引用模型上的字段或查询表达式的字符串
- output_field
- Avg(expression,output_field = None,distinct = False,filter = None,** extra
- 返回给定表达式的平均值
- Max,min,SteDev(标准变差),Sum,Variance(方差)
相关查询参数- Q()对象
- Q()对象,像一个F对象,封装在可以在与数据库相关的操作中使用Python对象SQL表达式。
- 可以定义和重用条件。这允许使用()和()运算符构造复杂的数据库查询
- Prefetch(lookup,queryset = None,to_attr = None)
- Prefetch()对象可用于控制的操作 prefetch_related()。
- prefetch_related_objects(model_instances,* related_lookups)
-
跨关系查询
- 跨模型使用关联字段名,字段名由双下划线分割,直到拿到想要的字段。
- Entry.objects.filter(blog__name='Beatles Blog')
- Blog.objects.filter(entry__authors__name='Lennon')
跨多值关联- Blog.objects.filter(entry__headline__contains='Lennon', entry__pub_date__year=2008)
- Blog.objects.filter(entry__headline__contains='Lennon').filter(entry__pub_date__year=2008)
F表达式- 模型字段值与同一模型中的另一字段做比较
- >>> from django.db.models import F>>> Entry.objects.filter(number_of_comments__gt=F('number_of_pingbacks'))
- >>> Entry.objects.filter(number_of_comments__gt=F('number_of_pingbacks') * 2)
- Entry.objects.filter(rating__lt=F('number_of_comments') + F('number_of_pingbacks'))
- Entry.objects.filter(authors__name=F('blog__name'))
- >>> from datetime import timedelta>>> Entry.objects.filter(mod_date__gt=F('pub_date') + timedelta(days=
-
主键(PK)查询快捷方式
- get

- filter

- 跨关系查询

-
比较对象
-
要比较两个模型实例,使用标准的 Python 比较操作符,两个等号: ==。实际上,这比较了两个模型实例的主键值
-
>>> some_entry == other_entry>>> some_entry.id == other_entry.id
-
>>> some_obj.name == other_obj.name (也可比较其他字段)
删除对象-
Entry.objects.filter(pub_date__year=2005).delete()
-
b = Blog.objects.get(pk=1)# This will delete the Blog and all of its Entry objects.b.delete()
复制模型实例-
麻烦,用到再看
一次修改多个对象-
方法 update() 立刻被运行,并返回匹配查询调节的行数,无需调用save()
-
修改非关联字段,给它一个新值
-
Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
-
修改 ForeignKey 字段,将新值置为目标模型的新实例。
-
>>> b = Blog.objects.get(pk=1)
-
-
# Change every Entry so that it belongs to this Blog.>>> Entry.objects.all().update(blog=b)
-
-
关联对象
-
一对多关联
-
正向访问
-
若模型有个 ForeignKey,该模型的实例能通过其属性访问关联(外部的)对象, foreign-key 属性获取和设置值。如你所想,对外键的修改直到你调用 save()
-
>>> e = Entry.objects.get(id=2)>>> e.blog = some_blog>>> e.save()
-
e = Entry.objects.select_related().get(id=2)
-
“反向”关联
-
若模型有 ForeignKey,外键关联的模型实例将能访问 Manager,后者会返回第一个模型的所有实例
-
Manager 名为 FOO_set, FOO 即源模型名的小写形式
-
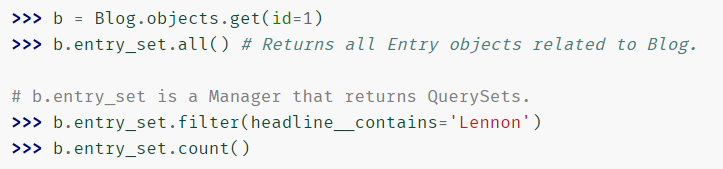
-
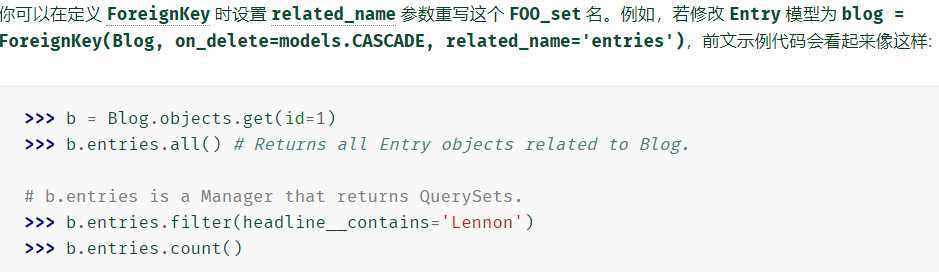
-
使用自定义反向管理器
-
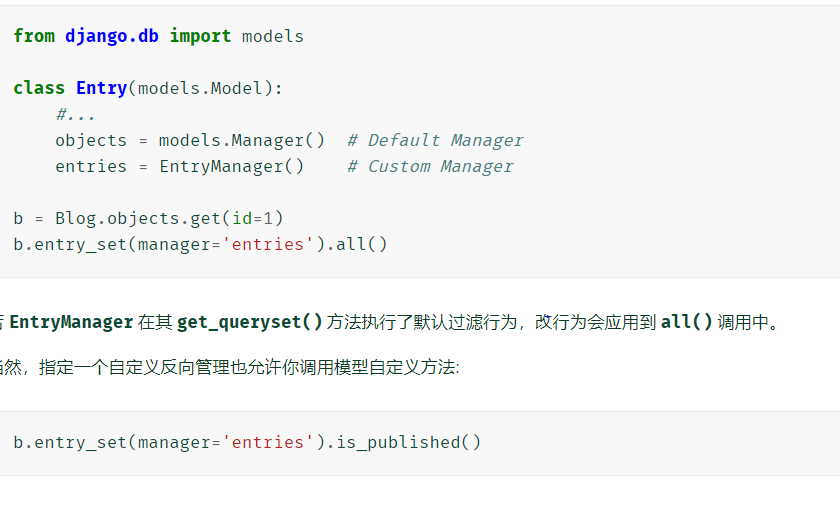
-
管理关联对象的额外方法
-
多对多关联-
多对多关联的两端均自动获取访问另一端的 API。该 API 的工作方式类似上面的 “反向” 一对多关联。
-
不同点在为属性命名上:定义了 ManyToManyField 的模型使用字段名作为属性名,而 “反向” 模型使用源模型名的小写形式,加上 '_set' (就像反向一对多关联一样)。
-

一对一关联-
正向访问
-

-
反向访问
-

-
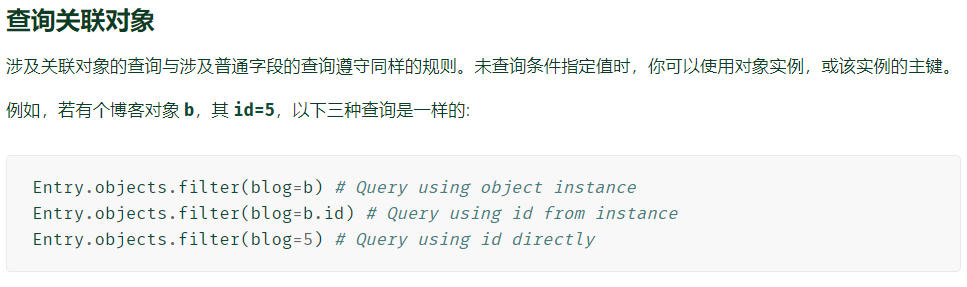
-
-
回归原生SQL
-
若你发现需要编写的 SQL 查询语句太过复杂,以至于 Django 的数据库映射无法处理,你可以回归手动编写 SQL
-
执行原生查询
-
Manager.raw(raw_query, params=None, translations=None)
-
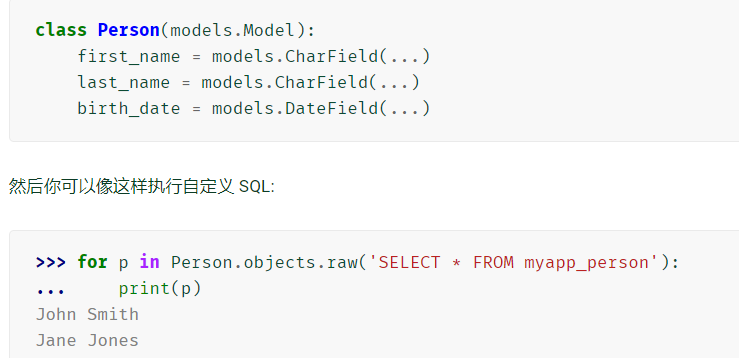
-
索引查询
-
first_person = Person.objects.raw('SELECT * FROM myapp_person LIMIT 1')[0]
-
延迟模型字段--省略部分字段
-
添加注释
-
people = Person.objects.raw('SELECT *, age(birth_date) AS age FROM myapp_person')
-
将参数传给raw()
-
people = Person.objects.raw('SELECT *, age(birth_date) AS age FROM myapp_person')
-
执行自定义SQL
-
有时候,甚至 Manager.raw() 都无法满足需求:你可能要执行不明确映射至模型的查询语句,或者就是直接执行 UPDATE, INSERT 或 DELETE 语句。
-
对象 django.db.connection 代表默认数据库连接。要使用这个数据库连接,调用 connection.cursor() 来获取一个指针对象。然后,调用 cursor.execute(sql, [params]) 来执行该 SQL 和 cursor.fetchone(),或 cursor.fetchall() 获取结果数据。
-

-
-
聚合
- Book.objects.aggregate(average_price=Avg('price')){'average_price': 34.35}
- >>> q = Book.objects.annotate(num_authors=Count('authors'))>>> q[0].num_authors
- 与 aggregate() 不同的是,annotate() 不是终端子句。annotate() 子句的输出就是 QuerySet;这个 QuerySet 被其他 QuerySet 操作进行修改,包括 filter()`, order_by() ,甚至可以对 annotate() 进行额外调用
-
自定义管理器
- 继承基类 Manager,在模型中实例化自定义 Manager,你就可以在该模型中使用自定义的 Manager。
-
有两种原因可能使你想要自定义 Manager:添加额外的 Manager 方法,修改 Manager 返回的原始 QuerySet。
-

- Book.dahl_objects.all()
- Book.dahl_objects.filter(title='Matilda')
- Book.dahl_objects.count()
-
数据库事务
- 事务
- 事务是指具有原子性的一系列数据库操作。即使你的程序崩溃,数据库也会确保这些操作要么全部完成要么全部都未执行。
- 保存点
- 保存点在事务中是标记物,它可以使得回滚部分,而不是所有事务 ,当嵌套了 atomic() 装饰器,它会创建一个保存点来允许部分提交或回滚
- 使用 atomic() 上下文管理器。在视图结束时,要么所有的更改都被提交,要么所有的更改都不被提交。
- 每个视图打开一个事务都会带来一些开销,影响性能
- 显示控制事务
- 作为装饰器

- 作为context manager

- 在 try/except 块中使用装饰器 atomic 来允许自然处理完整性错误
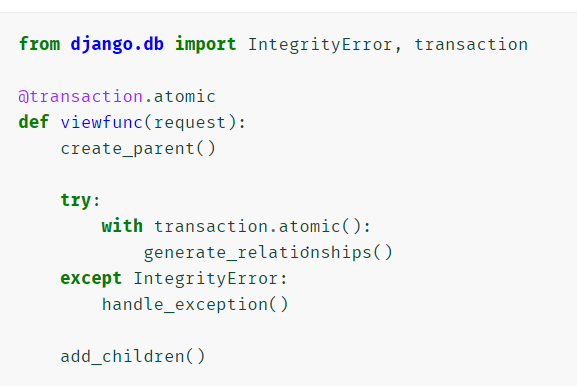
- transaction.on_commit(do_something)
- 将任意函数传递给on_commit ,celery 发送邮件,定时任务等

-
数据库优化技巧
-
indexes 第一优先级
-
确定添加哪些索引attr:Meta.indexes <django.db.models.Options.indexes>`或:attr:`Field.db_index <django.db.models.Field.db_index>
-
使用filter exclude order_by 确定最佳索引
-
为索引可能有助于加快查找速度。
-
缓存
-
要使用``QuerySet``的缓存行为,您可能需要使用:ttag:`with`模板标记
-
使用iterator()
-
使用explain()
-
uerySet.explain() 会有关于数据库如何执行查询的详细介绍,包括索引和联合(joins)的使用。这些细节可以帮助你如何更高效的重写查询,或者识别可以添加的所以来改进性能
-
在数据库中执行数据库操作,而不是在python 代码中
-
在最基础的层上,使用 filter 和 exclude 在数据库中过滤。
-
利用 注解在数据库中执行聚合。
-
使用rawSQL
-
使用原生SQL
-
使用 django.db.connection.queries 来找出 Django 为你编写的内容并从那里开始。
-
使用唯一索引来检索单个对象
-
entry = Entry.objects.get(id=10)
-
明确需要的数据,多次访问数据库会比单次查询所有内容效率低
-
多使用 select_related() 和 prefetch_related() 遵循外键关系取数据
-
不检索不需要的东西
-
当你只想得到字典或列表的值,并且不需要 ORM 模型对象时,可以适当使用 values()
-
使用QuerySet.values()和values_list()
-
使用QuerySet.defer()和only()
-
只想要计数
-
使用QuerySet.count(),不要使用len(QuerySet)
-
只想要确认是否至少存在一项满足结果
-
使用QuerySet.exists() 而不是 if querySet
-
不要过度使用count()和exists()
-
在任何时候使用 QuerySet.exists() 或 QuerySet.count() 会导致额外的查询。
-
使用QuerySet.update()和delete (批量更新或删除)
-
直接使用外键值
-
如果只需要外键值,那么使用已有对象上的外键值,而不是获取所有相关对象并获取它的主键
-
entry.blog_id 替换为entry.blog.id
-
如果不需要,不要排序结果
-
使用批量方法
-
当创建对象时,尽可能使用 bulk_create() 方法来减少 SQL 查询数量
-
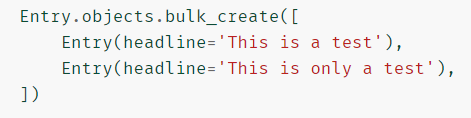
-
批量更新
-
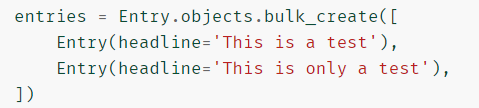
-
批量插入
-
当插入对象到 ManyToManyFields 时,使用带有多个对象的 add() 来减少 SQL 查询的数量
-

-
批量删除
-

-
-
数据库工具
-
钩子函数
-
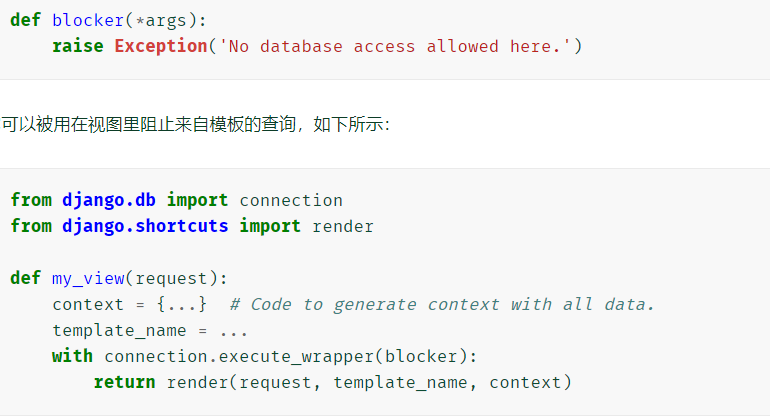
在这个钩子函数中你可以在数据库查询方法外层添加一层wrappers方法
-
wrapper方法的安装是在上下文管理器中完成的 -- 因此wrapper方法是暂时的, 也是针对于你代码里的某些特定逻辑的.
-
发给wrapper方法的参数是:
-
"execute" -- 一个可以被执行的对象, 使用剩下的参数触发来执行查询.
-
sql -- 一个 str,要发送到数据库的SQL 查询。
-
params -- SQL命令行参数值的列表/二元组,或者列表集/二元组集的一个列表/二元组(如果包装过的调用是executemany() 的话)。
-
many -- 一个布尔值,标识最终的调用是否是``execute()`` 还是 executemany()``(以及 ``params 是否是一个值系列,还是一系列值的序列)。
-
context -- 一个字典,包含带有关于调用上下文的数据。
-
-

-
-
路由
-
Django 加载该 Python 模块并寻找可用的 urlpatterns 。它是 django.urls.path() 和(或) django.urls.re_path() 实例的序列(sequence)。
-
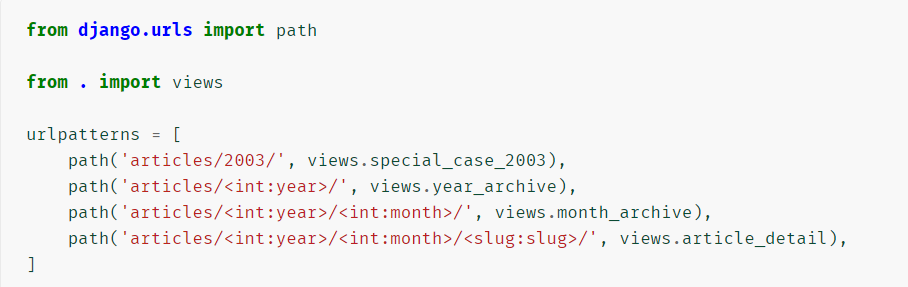
-
路径转换器
-
str - 匹配除了 '/' 之外的非空字符串。如果表达式内不包含转换器,则会默认匹配字符串。
-
int - 匹配 0 或任何正整数。返回一个 int 。
-
slug - 匹配任意由 ASCII 字母或数字以及连字符和下划线组成的短标签。比如,building-your-1st-django-site。
-
uuid - 匹配一个格式化的 UUID 。为了防止多个 URL 映射到同一个页面,必须包含破折号并且字符都为小写。比如,075194d3-6885-417e-a8a8-6c931e272f00。返回一个 UUID 实例。
-
path - 匹配非空字段,包括路径分隔符 '/' 。它允许你匹配完整的 URL 路径而不是像 str 那样匹配 URL 的一部分。
-
正则表达式
-
使用re_path
-
(?P<name>pattern) ,其中 name 是组名,pattern 是要匹配的模式。
-
以^起始,$截至
-

-
嵌套参数
-
搞不明白
-
指定视图函数的默认值
-
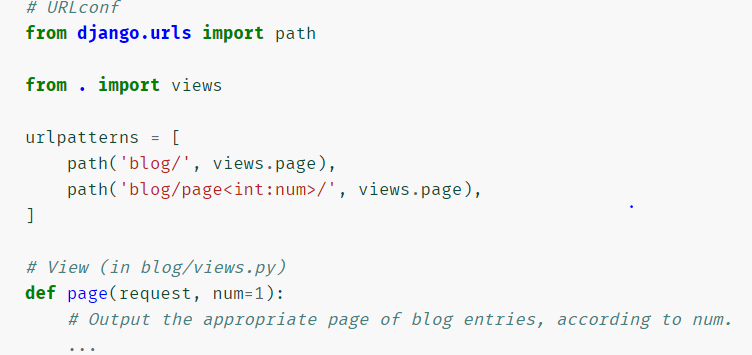
-
传递额外的选项给视图函数
-
path() 函数可带有可选的第三参数(必须是字典),传递到视图函数里
-
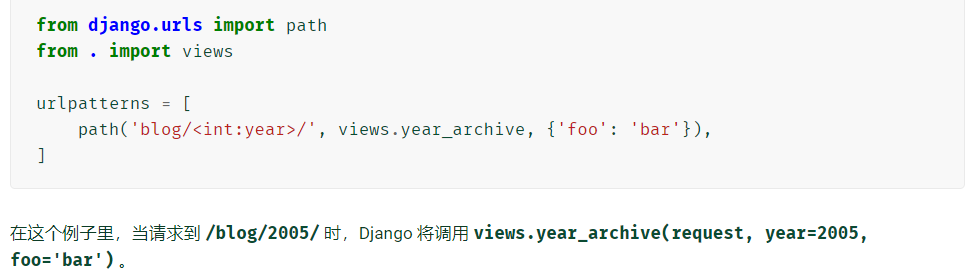
-
传递额外的选项给include()
-
URL 反向解析
-
在模板里:使用 url 模板标签。
-
在 Python 编码:使用 reverse() 函数。
-
在与 Django 模型实例的 URL 处理相关的高级代码中: get_absolute_url() 方法。
-
urlpatterns = [
-
path('articles/<int:year>/',views.year_archive, name='news-year-archive'),
-
return HttpResponseRedirect(reverse('news-year-archive', args=(year,)))
-
-
视图装饰器
-
允许的HTTP方法
-
equire_GET()
-
equire_POST()
-
equire_safe() 只接收 GET 和 HEAD 方法
-
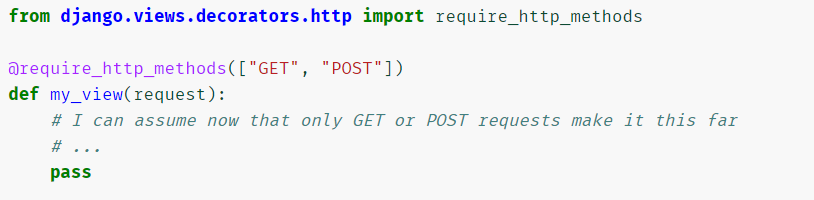
-
条件视图处理
-
下面 django.views.decorators.http 的装饰器被用来控制特殊视图中的缓存行为。
-
condition(etag_func=None, last_modified_func=None)
-
etag(etag_func)
-
last_modified(last_modified_func)
-
Gzip压缩
-
gzip_page()
-
如果浏览器允许 gzip 压缩,那么这个装饰器将压缩内容。它相应的设置了 Vary 头部,这样缓存将基于 Accept-Encoding 头进行存储。
-
Vary头
-
django.views.decorators.vary 里的装饰器被用来根据特殊请求头的缓存控制。
-
vary_on_cookie(func
-
vary_on_headers(*headers
-
Vary 头定义了缓存机制在构建其缓存密钥时应该考虑哪些请求报头
-
缓存
-
django.views.decorators.cache 中的装饰器控制服务器及客户端的缓存。
-
cache_control(**kwargs)
-
这个装饰器通过添加所有关键字参数来修补响应的 Cache-Control 头
-
never_cache(view_func)
-
这个装饰器添加 Cache-Control: max-age=0, no-cache, no-store, must-revalidate 头到一个响应来标识禁止缓存该页面。
-
-
文件上传
-
只有在请求是通过 POST 提交且提交的 <form> 表单有 enctype="multipart/form-data" 属性的时候,request.FILES 才会包含文件数据,否则的话, request.FILES 是空的
-
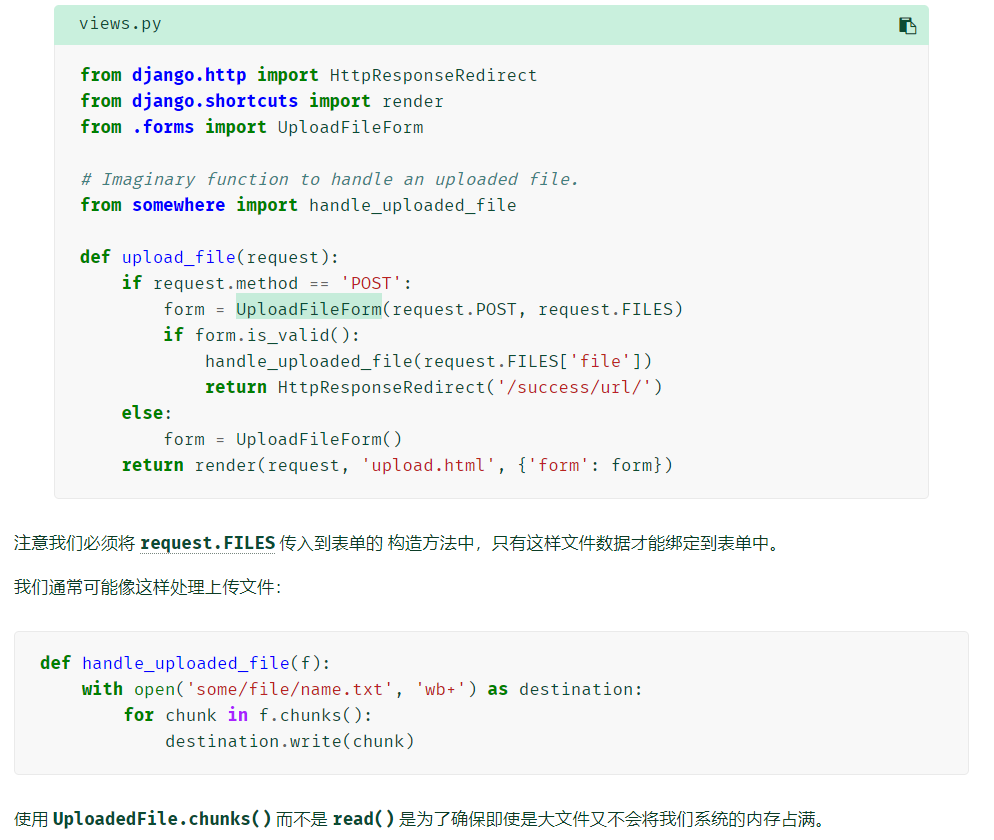
-
通过模型来处理上传文件
-
上传多个文件
-
使用一个表单字段上传多个文件,则需要设置字段的 widget 的 multiple HTML 属性。
-
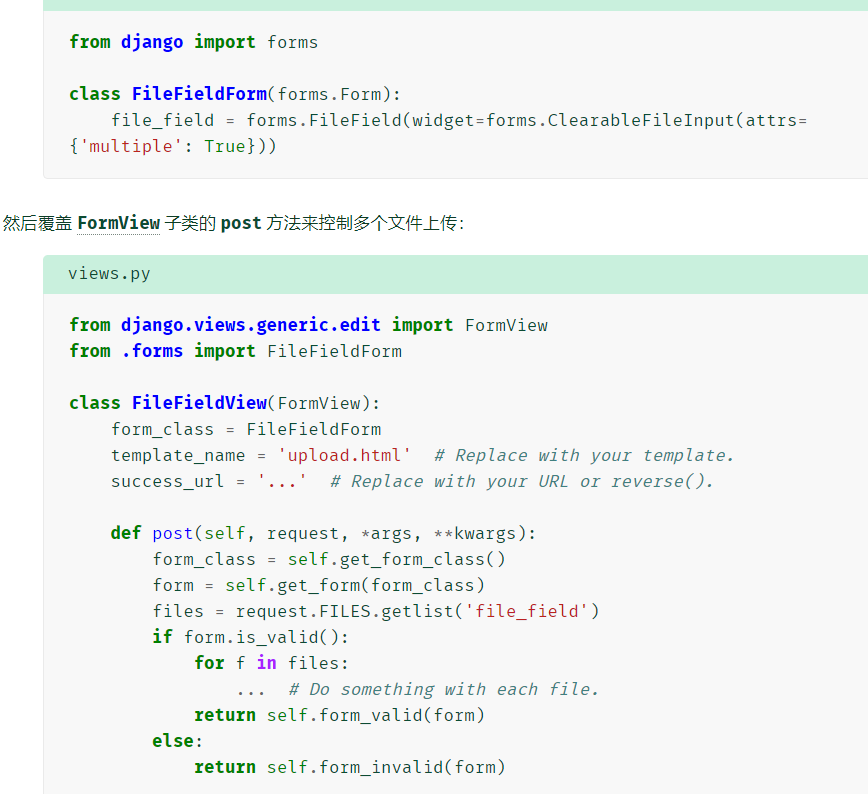
-
上传Handlers
-
当一个用户上传文件时,Django 会把文件数据传递给 upload handler —— 这是一个很小的类,它用来在上传时处理文件数据。上传处理模块最初定义在 FILE_UPLOAD_HANDLERS 里,默认为
-
["django.core.files.uploadhandler.MemoryFileUploadHandler",
-
"django.core.files.uploadhandler.TemporaryFileUploadHandler"]
-
提供 Django 默认文件上传行为,小文件读入内存,大文件存在磁盘上。
-
上传数据的存储
-
小文件<2.5M
-
Django 将把文件的所有内容保存到内存里。这意味着保存文件只涉及从内存中读取和写入磁盘,因此这很快。
-
大文件
-
如果上传的文件很大,Django 会把文件写入系统临时目录的临时文件里存储
-
在类 Unix 平台里这意味着 Django 会生成一个类似名为 /tmp/tmpzfp6I6.upload 的文件
-
Django 将数据流式传输到磁盘上。
-
-
Django快捷函数
-
render
-
render(request, template_name, context=None, content_type=None, status=None, using=None)¶
-
-
将给定的模板与给定的上下文字典组合在一起,并以渲染的文本返回一个 HttpResponse 对象
-
-
必选参数 :request , template_name 要使用的模板的全名或模板名称的序列
-
可选参数:context (要添加到模板上下文的字典),content_type (结果文档的MIME类型,默认‘text/html’status:默认为200 ,using:用于加载模板的模板引擎的: setting:`NAME `
-
redirect(to, *args, permanent=False, **kwargs)
-
将一个HttpResponseRedirect 返回到传递的适当URL
-
论点可以是:
-
model:模型的 get_absolute_url() 函数会被调用。
-

-
视图名,可能带有的参数:reverse() 将被用于反向解析名称。
-

-
一个绝对或相对 URL,将按原样用作重定向位置。
-

-
默认情况下发出临时重定向,通过传递参数permanent=True 发出永久重定向
-
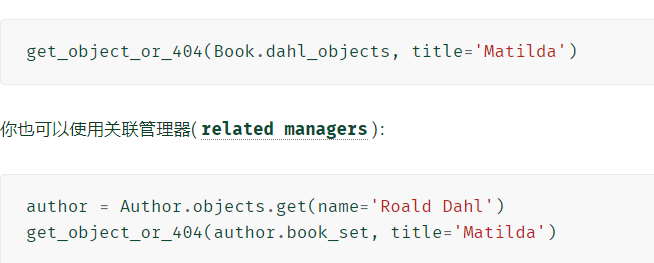
get_object_or_404( klass, *args, **kwargs)
-
必选参数
-
**kwargs 查询参数,应采用 get() 和 filter() 接受的格式。
-
传入model
-
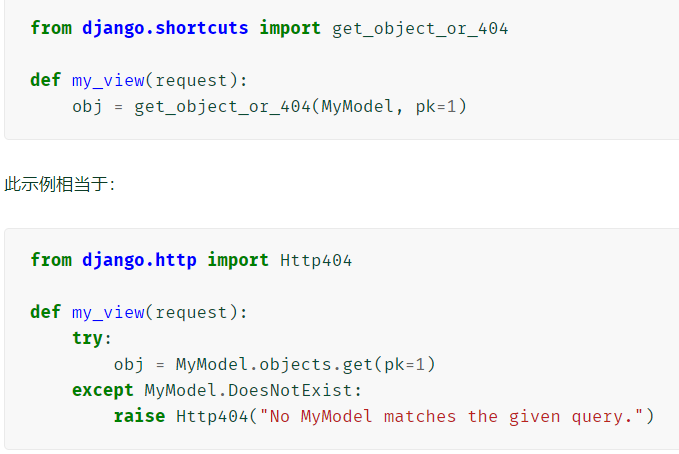
-
传入queryset实例
-

-
传入manager
-
-
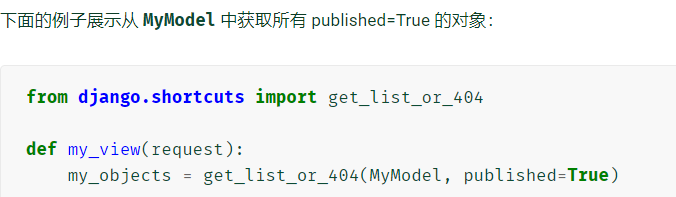
get_list_or_404( (klass, *args, **kwargs)
-
-
-
内置的基于类的视图
-
点击劫持保护
-
设置 X-Frame-Options HTTP 响应头,不允许在框架或Iframe 中加载非同源的资源
-
在所有响应中设置表头的中间件
-
一组视图装饰器,可用于覆盖中间件或仅为某些视图设置标头
-
如果X-Frame-OptionsHTTP头尚未在响应中出现,则仅由中间件或视图装饰器设置。
-
在中间件中设置
-
MIDDLEWARE = [ 'django.middleware.clickjacking.XFrameOptionsMiddleware',]
-
默认情况下,中间件将为每个outgoing 将X-Frame-Options标头设置 DENY。如果您希望此标头使用其他任何值,请进行以下X_FRAME_OPTIONS设置:X_FRAME_OPTIONS = 'SAMEORIGIN'(仅允许加载同源)
-
有些视图可能不希望设置 X-Frame-Options标头,可使用装饰器告知中间件不要设置标头
-
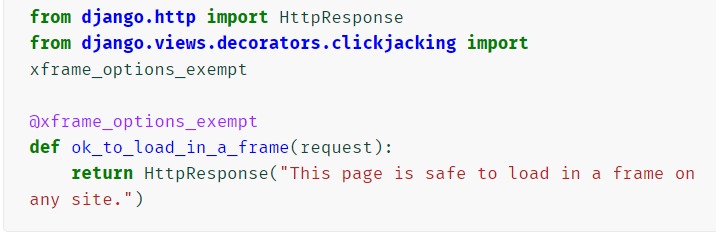
-
基于每个视图设置不同的值
-
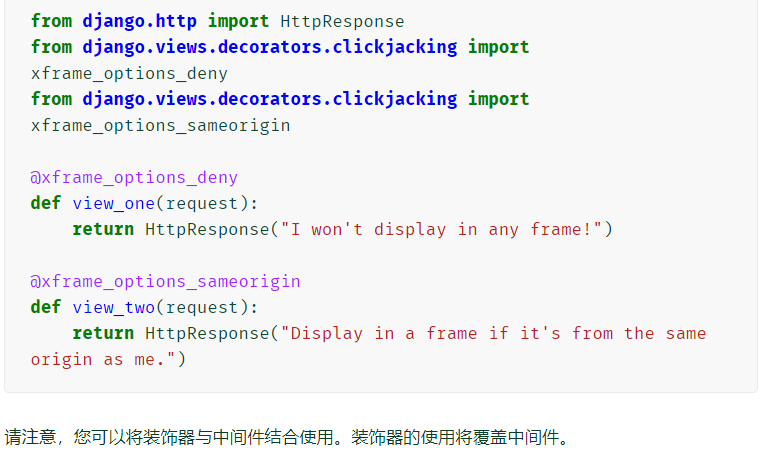
-
局限性
-
该X-Frame-Options头只会防止在现代浏览器中点击劫持。较旧的浏览器将安静地忽略标题,并需要其他防止点击劫持的技术。
-

-
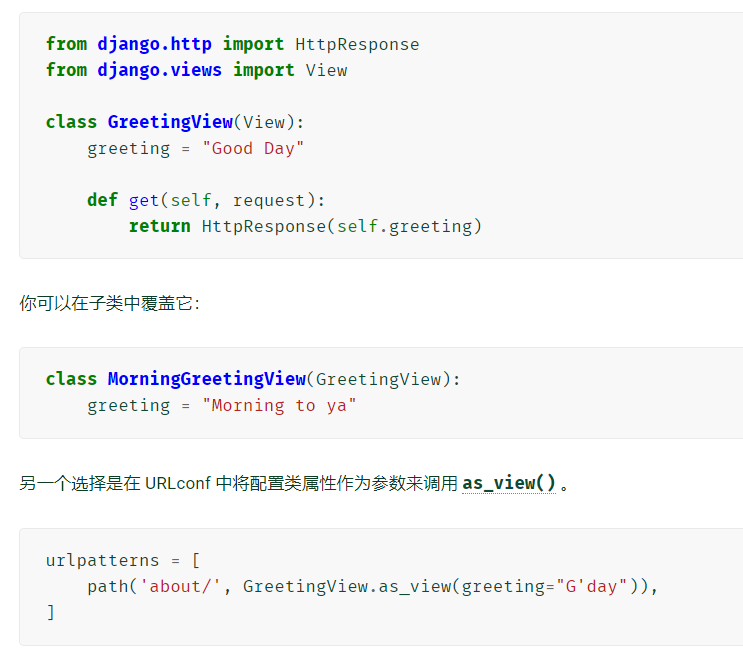
-

-

-
-
管理文件
-
默认情况下,Django 使用 MEDIA_ROOT 和 MEDIA_URL 设置本地存储
-

-
file 对象
-
文件存储
-
Django 的默认文件存储通过 DEFAULT_FILE_STORAGE 配置;如果你不显式地提供存储系统,这里会使用默认配置。
-
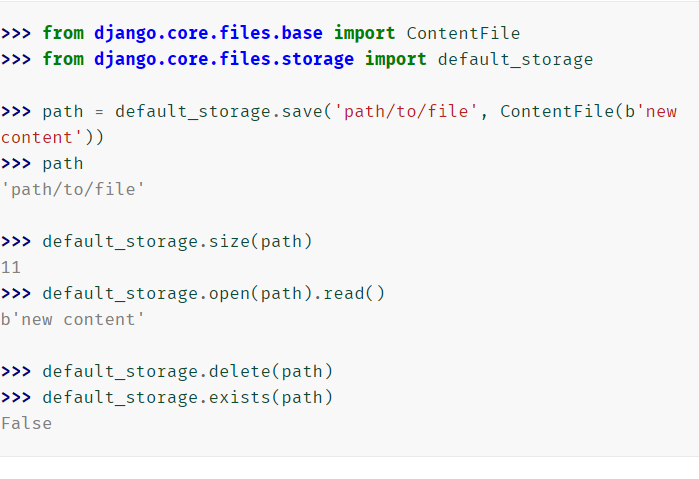
-
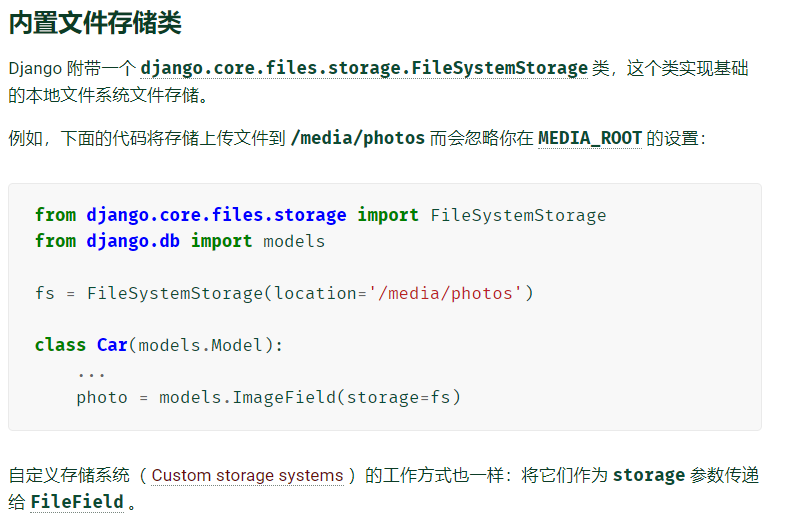
-
-
Django 中的测试类
-
自动化测试是一个非常有用的发现 bug 的工具。你可以使用一套测试—— 测试套件 ——去解决
-
Django 的单元测试采用 Python 的标准模块: unittest。该模块以类的形式定义测试。
-
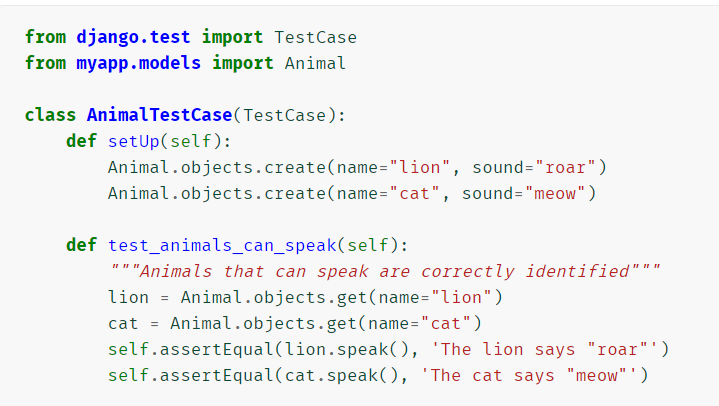
-
如果你的测试依赖数据库连接,比如创建或查询模型,请确保继承 django.test.TestCase 实现你的测试类,而不是 unittest.TestCase。
-
运行测试 ./manage.py test
-
测试工具
-
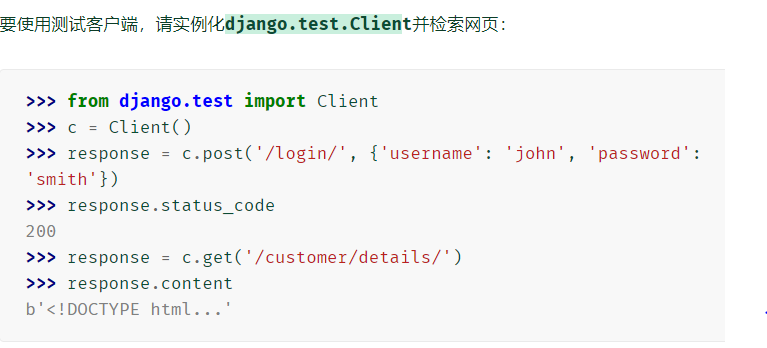
django.test.Client测试客户端是一个Python类,它充当虚拟Web浏览器,使您可以测试视图并以编程方式与Django驱动的应用程序进行交互。
-
模拟URL上的GET和POST请求并观察响应-从低级HTTP(结果标头和状态代码)到页面内容,应有尽有。
-
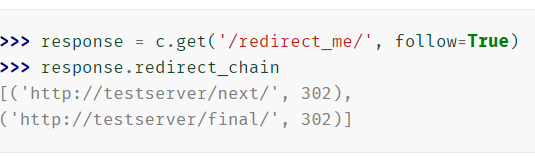
查看重定向链(如果有),并在每个步骤中检查URL和状态代码。
-
测试给定的请求是否由给定的Django模板以及包含某些值的模板上下文呈现。
-
请注意,测试客户端无意替代Selenium或其他“浏览器内”框架。Django的测试客户端有不同的重点。简而言之:
-
使用Django的测试客户端建立正确的模板,并向模板传递正确的上下文数据。
-
使用诸如Selenium之类的浏览器内框架来测试渲染的 HTML和Web页面的 行为,即JavaScript功能。Django还为这些框架提供了特殊的支持。有关LiveServerTestCase更多详细信息,请参见部分 。
-
-
默认情况下,测试客户端将禁用您的站点执行的所有CSRF检查。
-

-
发出请求
-
Client(execute_csrf_checks = False,json_encoder = DjangoJSONEncoder,** defaults)
-
您可以使用关键字参数指定一些默认标题。例如,这将User-Agent在每个请求中发送一个HTTP标头: c = Client(HTTP_USER_AGENT='Mozilla/5.0')
-
client实例可调用的方法
-
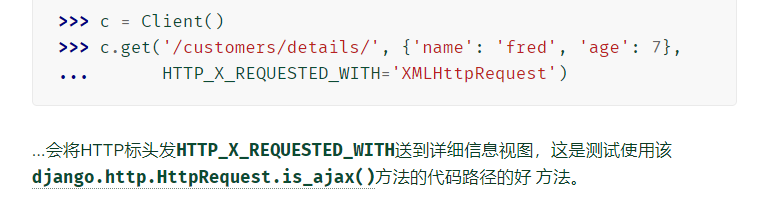
get(path,data = None,follow = False,secure = False,**额外)
-
c.get('/customers/details/', {'name': 'fred', 'age': 7})
-
=/customers/details/?name=fred&age=7
-
=c.get('/customers/details/?name=fred&age=7')
-
-
如果设置follow为,True则客户端将遵循任何重定向
-
-
post(path,data = None,content_type = MULTIPART_CONTENT,follow = False,secure = False,**额外)
-

-
提交文件
-

-
head(path,data = None,follow = False,secure = False,**额外)
-
对提供的HEAD请求path并返回一个 Response对象, 但它不会返回消息正文。
-
options(path,data ='',content_type ='application / octet-stream',follow = False,secure = False,**额外)
-
对提供path的Response对象进行OPTIONS请求并返回一个 对象。对于测试RESTful接口很有用。
-
put(path,data ='',content_type ='application / octet-stream',follow = False,secure = False,**额外)
-
提供的内容上进行PUT请求path并返回一个 Response对象。对于测试RESTful接口很有用。
-
patch(path,data ='',content_type ='application / octet-stream',follow = False,secure = False,**额外)
-
在提供的内容上发出PATCH请求path并返回一个 Response对象。对于测试RESTful接口很有用。
-
delete(path,data ='',content_type ='application / octet-stream',follow = False,secure = False,**额外)
-
对提供的内容进行DELETE请求path并返回一个 Response对象。对于测试RESTful接口很有用。
-
trace(path,follow = False,secure = False,**额外)
-
对提供path的Response对象进行TRACE请求并返回一个 对象。用于模拟诊断探针。
-
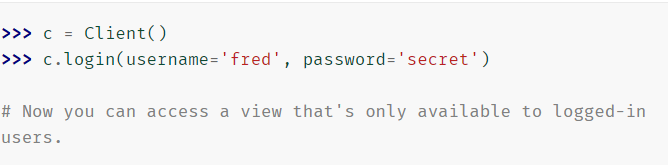
login(**凭据)
-
如果您的站点使用Django的身份验证系统 并且您要处理用户登录,则可以使用测试客户端的login()方法来模拟用户登录站点的效果。 login()返回True是否接受凭据且登录成功。
-
-
force_login(user,backend = None)
-
不同于login(),此方法跳过了身份验证和验证步骤:is_active=False允许非活动用户()登录,并且不需要提供用户凭据。
-
logout()
-
如果您的站点使用Django的身份验证系统,则该logout()方法可用于模拟用户退出站点的效果。
-
测试响应
-
该get()和post()方法都返回一个Response对象。这个 Response对象是不一样的HttpResponse由Django的视图返回的对象; 测试响应对象还有一些其他数据,可用于验证测试代码。
-
response 类
-
client 用于发出导致响应的请求的测试客户端
-
content 响应的主体,以字节串形式。这是视图或任何错误消息所呈现的最终页面内容。
-
context 用于渲染产生响应内容的模板的模板实例。
-

-
exc_info
-
三个值的元组,它们提供有关在视图期间发生的未处理异常(如果有)的信息。
-
type:异常的类型。
-
value:异常实例。
-
traceback:一个追溯对象,在最初发生异常的地方封装了调用堆栈。
-
如果没有发生异常,exc_info则将为None。
-
json(**kwargs)
-
响应的主体,解析为JSON。额外的关键字参数传递给json.loads()。
-
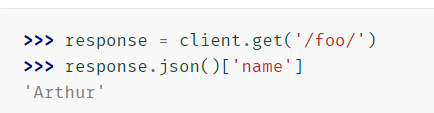
-
request 激发响应的请求数据
-
wsgi_request
-
WSGIRequest由测试处理程序生成的实例,该实例生成了响应。
-
status_code
-
响应的HTTP状态,以整数形式
-
templates
-
Template用于渲染最终内容的实例列表(按渲染顺序)
-
resolver_match
-
您可以使用属性来验证提供响应的视图
-

-
cookie 和session
-
Client.cookies
-
一个Python SimpleCookie对象,其中包含所有客户端cookie的当前值
-
Client.session
-
包含会话信息的类字典对象。有关完整的详细信息
-

-
Django提供的测试用例类
-
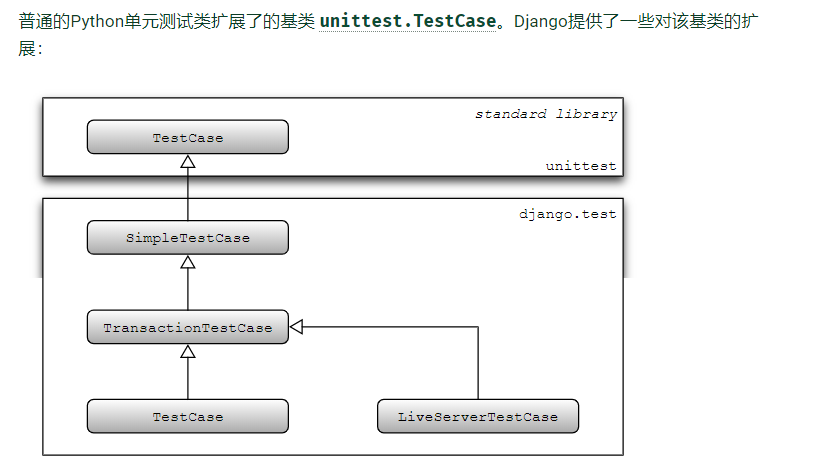
-
SimpleTestCase
-
继承unittest.TestCase,增加了一些断言功能, SimpleTestCase默认情况下不允许数据库查询
-

-
TransactionTestCase
-
继承SimpleTestCase以添加一些特定于数据库的功能:
-
可以调用提交和回滚,并观察这些调用对数据库的影响。
-

-
TestCase
-
这是在Django中编写测试最常用的类。它继承自TransactionTestCase(并通过扩展SimpleTestCase)
-
将测试包装在两个嵌套的atomic() 块中:一个用于整个类,一个用于每个测试。因此,如果要测试某些特定的数据库事务行为,请使用 TransactionTestCase。在每次测试结束时检查可延迟的数据库约束。
-
TestCase.setUpTestData()
-
atomic上面描述的类级别块允许一次在整个级别上创建初始数据TestCase。与使用相比,该技术可以进行更快的测试setUp()。
-

-
liveServerTestCase
-
继承TransactionTestCase,附加功能 :它会在设置时在后台启动实时Django服务器,并在拆卸时将其关闭
-
并且希望在测试执行期间提供静态文件, 替换为StaticLiveServerTestCase
-
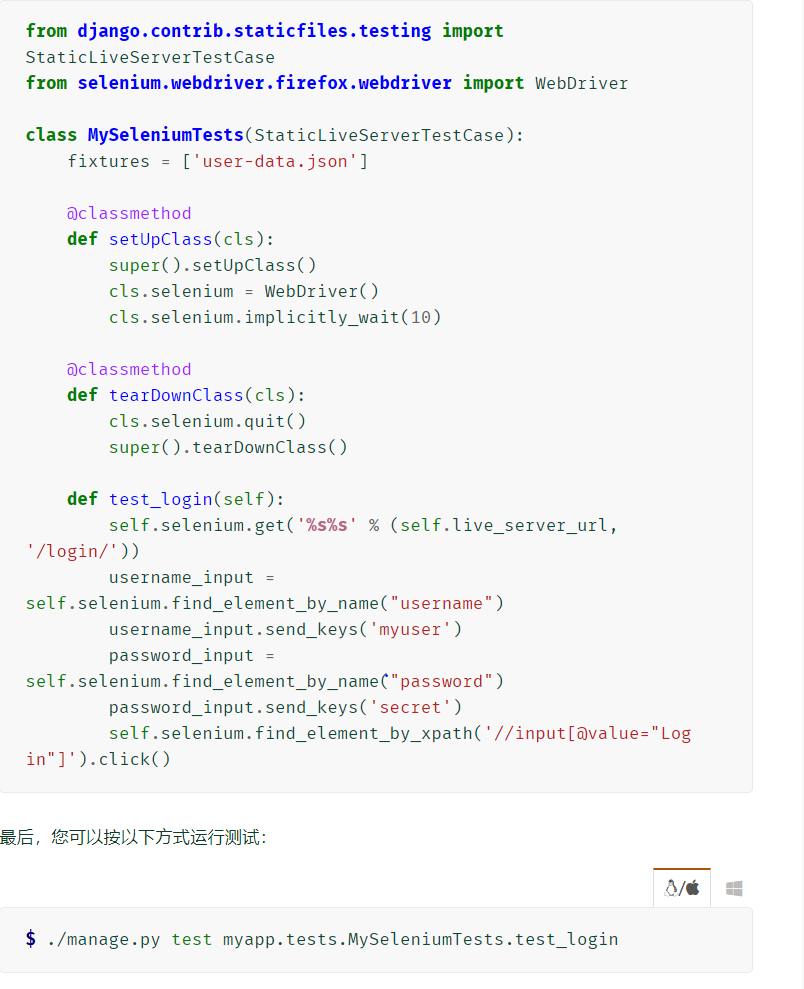
-