一 . K-近邻算法(KNN)概述
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
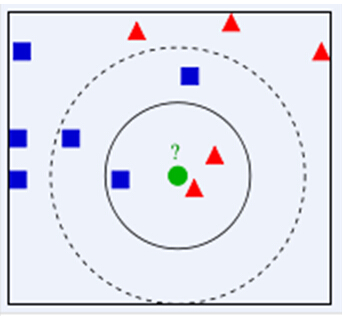
由此也说明了KNN算法的结果很大程度取决于K的选择。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
二 .python实现
首先呢,需要说明的是我用的是python3.4.3,里面有一些用法与2.7还是有些出入。
建立一个KNN.py文件对算法的可行性进行验证,如下:


#coding:utf-8 from numpy import * import operator ##给出训练数据以及对应的类别 def createDataSet(): group = array([[1.0,2.0],[1.2,0.1],[0.1,1.4],[0.3,3.5]]) labels = ['A','A','B','B'] return group,labels ###通过KNN进行分类 def classify(input,dataSe t,label,k): dataSize = dataSet.shape[0] ####计算欧式距离 diff = tile(input,(dataSize,1)) - dataSet sqdiff = diff ** 2 squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量 dist = squareDist ** 0.5 ##对距离进行排序 sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标 classCount={} for i in range(k): voteLabel = label[sortedDistIndex[i]] ###对选取的K个样本所属的类别个数进行统计 classCount[voteLabel] = classCount.get(voteLabel,0) + 1 ###选取出现的类别次数最多的类别 maxCount = 0 for key,value in classCount.items(): if value > maxCount: maxCount = value classes = key return classes
接下来,在命令行窗口或新建一个python文件输入如下代码:
#-*-coding:utf-8 -*- import sys sys.path.append("...文件路径...") import KNN from numpy import * dataSet,labels = KNN.createDataSet() input = array([1.1,0.3]) K = 3 output = KNN.classify(input,dataSet,labels,K) print("测试数据为:",input,"分类结果为:",output)
回车之后的结果为:
测试数据为: [ 1.1 0.3] 分类为: A
答案符合我们的预期,要证明算法的准确性,势必还需要通过处理复杂问题进行验证,之后另行说明。
三 实战
之前,对KNN进行了一个简单的验证,今天我们使用KNN改进约会网站的效果,个人理解,这个问题也可以转化为其它的比如各个网站迎合客户的喜好所作出的推荐之类的,当然,今天的这个例子功能也实在有限。
在这里根据一个人收集的约会数据,根据主要的样本特征以及得到的分类,对一些未知类别的数据进行分类,大致就是这样。
我使用的是python 3.4.3,首先建立一个文件,例如date.py,具体的代码如下:
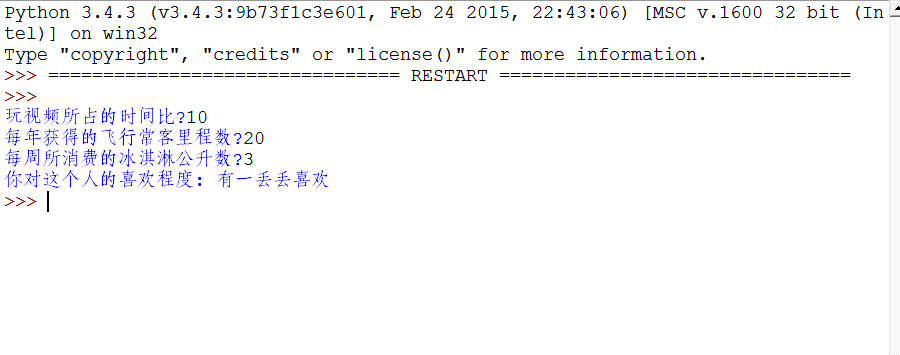
#coding:utf-8 from numpy import * import operator from collections import Counter import matplotlib import matplotlib.pyplot as plt ###导入特征数据 def file2matrix(filename): fr = open(filename) contain = fr.readlines()###读取文件的所有内容 count = len(contain) returnMat = zeros((count,3)) classLabelVector = [] index = 0 for line in contain: line = line.strip() ###截取所有的回车字符 listFromLine = line.split(' ') returnMat[index,:] = listFromLine[0:3]###选取前三个元素,存储在特征矩阵中 classLabelVector.append(listFromLine[-1])###将列表的最后一列存储到向量classLabelVector中 index += 1 ##将列表的最后一列由字符串转化为数字,便于以后的计算 dictClassLabel = Counter(classLabelVector) classLabel = [] kind = list(dictClassLabel) for item in classLabelVector: if item == kind[0]: item = 1 elif item == kind[1]: item = 2 else: item = 3 classLabel.append(item) return returnMat,classLabel#####将文本中的数据导入到列表 ##绘图(可以直观的表示出各特征对分类结果的影响程度) datingDataMat,datingLabels = file2matrix('D:pythonMechine learing in ActionKNNdatingTestSet.txt') fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels)) plt.show() ## 归一化数据,保证特征等权重 def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = zeros(shape(dataSet))##建立与dataSet结构一样的矩阵 m = dataSet.shape[0] for i in range(1,m): normDataSet[i,:] = (dataSet[i,:] - minVals) / ranges return normDataSet,ranges,minVals ##KNN算法 def classify(input,dataSet,label,k): dataSize = dataSet.shape[0] ####计算欧式距离 diff = tile(input,(dataSize,1)) - dataSet sqdiff = diff ** 2 squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量 dist = squareDist ** 0.5 ##对距离进行排序 sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标 classCount={} for i in range(k): voteLabel = label[sortedDistIndex[i]] ###对选取的K个样本所属的类别个数进行统计 classCount[voteLabel] = classCount.get(voteLabel,0) + 1 ###选取出现的类别次数最多的类别 maxCount = 0 for key,value in classCount.items(): if value > maxCount: maxCount = value classes = key return classes ##测试(选取10%测试) def datingTest(): rate = 0.10 datingDataMat,datingLabels = file2matrix('D:pythonMechine learing in ActionKNNdatingTestSet.txt') normMat,ranges,minVals = autoNorm(datingDataMat) m = normMat.shape[0] testNum = int(m * rate) errorCount = 0.0 for i in range(1,testNum): classifyResult = classify(normMat[i,:],normMat[testNum:m,:],datingLabels[testNum:m],3) print("分类后的结果为:,", classifyResult) print("原结果为:",datingLabels[i]) if(classifyResult != datingLabels[i]): errorCount += 1.0 print("误分率为:",(errorCount/float(testNum))) ###预测函数 def classifyPerson(): resultList = ['一点也不喜欢','有一丢丢喜欢','灰常喜欢'] percentTats = float(input("玩视频所占的时间比?")) miles = float(input("每年获得的飞行常客里程数?")) iceCream = float(input("每周所消费的冰淇淋公升数?")) datingDataMat,datingLabels = file2matrix('D:pythonMechine learing in ActionKNNdatingTestSet2.txt') normMat,ranges,minVals = autoNorm(datingDataMat) inArr = array([miles,percentTats,iceCream]) classifierResult = classify((inArr-minVals)/ranges,normMat,datingLabels,3) print("你对这个人的喜欢程度:",resultList[classifierResult - 1])
新建test.py文件了解程序的运行结果,代码:
#coding:utf-8 from numpy import * import operator from collections import Counter import matplotlib import matplotlib.pyplot as plt import sys sys.path.append("D:pythonMechine learing in ActionKNN") import date date.classifyPerson()
运行结果如下图: