Little_by_Little_3 对数据进行测试集训练集验证集进行划分
目的
将
划分成
训练集占8成,valid和test各占一成.
源代码
import os
import random
import shutil
def makedir(new_dir):#创建新文件,若没有就不创建
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
random.seed(1)
#1
dataset_dir = os.path.join("..", "..", "data", "RMB_data")
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1#此条无用
#2
for root, dirs, files in os.walk(dataset_dir):#files无用
'''
def walk(top: T,
topdown: bool = True,
onerror: Optional[(Exception) -> None] = None,
followlinks: bool = False) -> Iterator[Tuple[T, List[T], List[T]]]
top -- 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
topdown --可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
onerror -- 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
followlinks -- 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
'''
#3
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))#所指的是当前正在遍历的这个文件夹的本身的地址+子目录的地址
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))#提取出文件中end为jpg的文件名且把他变成list
random.shuffle(imgs)#打乱图片
img_count = len(imgs)#图片个数
train_point = int(img_count * train_pct)#训练集数
valid_point = int(img_count * (train_pct + valid_pct))#训练集数+测试集数
#4
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)#
elif i < valid_point:#取够训练集就取验证集
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])#拼接outdir和img名,目标文件的路径
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])#抓取文件的路径
shutil.copy(src_path, target_path)#复制操作
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
#1分析
dataset_dir = os.path.join("..", "..", "data", "RMB_data")
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1#此条无用
dataset_dir = os.path.join("..", "..", "data", "RMB_data")此条的作用是提取data所在的文件路径
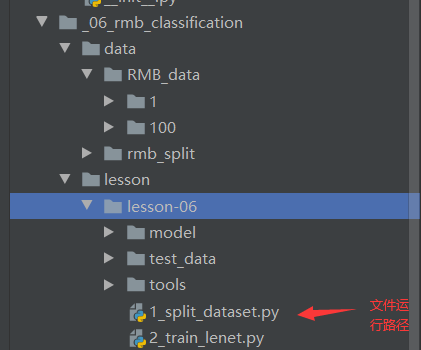
数据路径图如上图所示,要往上两层才能导_06_rmb_classification(主文件夹)所以要加两个'..'.
train_pct = 0.8划分训练集所占比例
#2 分析
for root, dirs, files in os.walk(dataset_dir):#files无用 在
- 里面进行循环接收root(RMB_data本文件的路径),dirs(1文件夹和2文件夹的文件夹名)
#3 分析
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))#所指的是当前正在遍历的这个文件夹的本身的地址+子目录的地址
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))#提取出文件中end为jpg的文件名且把他变成list
random.shuffle(imgs)#打乱图片
img_count = len(imgs)#图片个数
train_point = int(img_count * train_pct)#训练集数
valid_point = int(img_count * (train_pct + valid_pct))#训练集数+测试集数
-
对rmb_data里面的文件夹里面的文件进行循环

-
imgs = os.listdir(os.path.join(root, sub_dir))提取出当前正在遍历的这个文件夹的本身的地址+子目录的地址,并把地址里面的文件变成list. -
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))把地址里面以.jpg的文件的文件名提取出来.
#4 分析
#4
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)#
elif i < valid_point:#取够训练集就取验证集
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])#拼接outdir和img名,目标文件的路径
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])#抓取文件的路径
shutil.copy(src_path, target_path)#复制操作
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
-
for i in range(img_count):循环次数定位1或100文件里面的文件数 -
if i < train_point: out_dir = os.path.join(train_dir, sub_dir)# elif i < valid_point:#取够训练集就取验证集 out_dir = os.path.join(valid_dir, sub_dir) else: out_dir = os.path.join(test_dir, sub_dir)控制训练集,测试集和验证集的数量.通过设置输出文件的路径来控制
-
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])设置抓取文件的路径 -
shutil.copy(src_path, target_path)复制操作