最难读的Theano代码
这份LSTM代码的作者,感觉和前面Tutorial代码作者不是同一个人。对于Theano、Python的手法使用得非常娴熟。
尤其是在两重并行设计上:
①LSTM各个门之间并行
②Mini-batch让多个句子并行
同时,在训练、预处理上使用了诸多技巧,相比之前的Tutorial,更接近一个完整的框架,所以导致代码阅读十分困难。
本文旨在梳理这份LSTM代码的脉络。
数据集:IMDB Large Movie Review Dataset
来源
该数据集是来自Stanford的一个爬虫数据集。
对IMDB每部电影的评论页面的每条评论进行爬虫,分为正面/负面两类情感标签。
相比于朴素贝叶斯用于垃圾邮件分类,显然,分析一段文字的情感难度比较大。
因为语义在各个词之间连锁着,有些喜欢玩梗的负面讽刺语义需要一个强力的Represention Extractor。
该数据集同时也在CS224D:Deep Learning for NLP [Leture4]中演示,用于体现Pre-Training过后的词向量威力。
数据读取
原始数据集被Bengio组封装过,链接 http://www.iro.umontreal.ca/~lisa/deep/data/imdb.pkl
cPickle封装的格式如下:
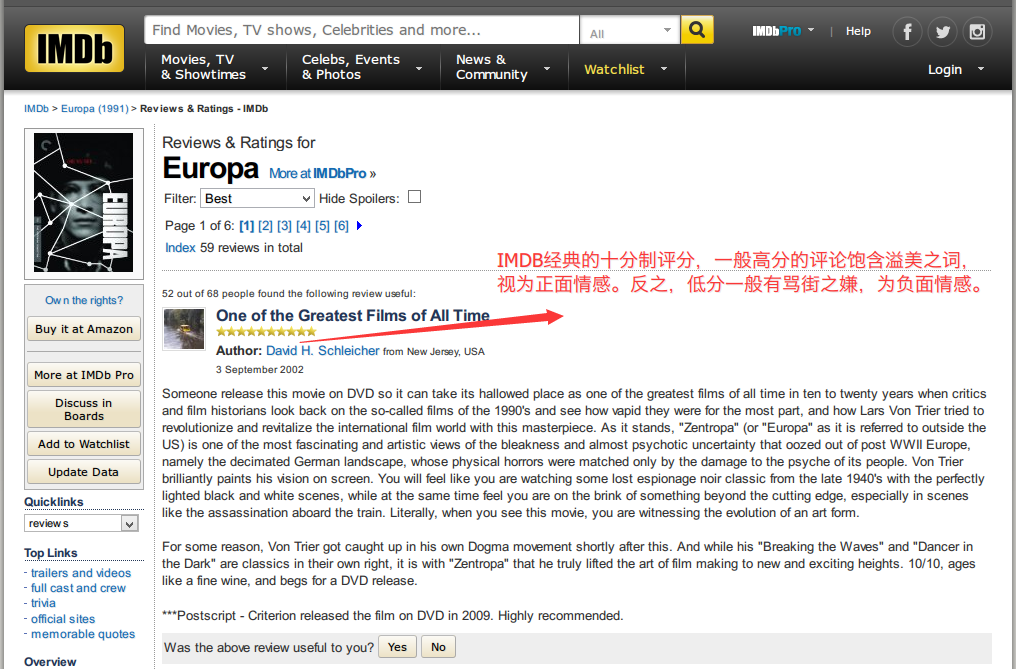
train_set[0] ----> 一个包含所有句子的二重列表,列表的每个元素也为一个列表,内容为:
[词索引1,词索引2,.....,词索引n],构成一个句子。熟悉文本数据的应该很清楚。
词索引之前建立了一个词库,实际使用的时候如果要对照索引,获取真实的词,则需要词库:~Link~
train_set[0][n]指的是第n个句子。
————————————————————————————————————————————
train_set[1] ----> 一个一重列表,每个元素为每个句子的情感标签,0/1。
test_set格式相同。
————————————————————————————————————————————
本Tutorial使用的一些简单处理包括:maxLen句子词数剪枝、词库越界词剪枝、句子词数排序(不知道啥作用)
数据变形与预处理
这份代码的经典之处在于,让多个句子并行训练,构成一个mini-batch。
在RNN章节中,每次训练只是一个句子,所以输入就是一个向量,但mini-batch之后就是一个矩阵。
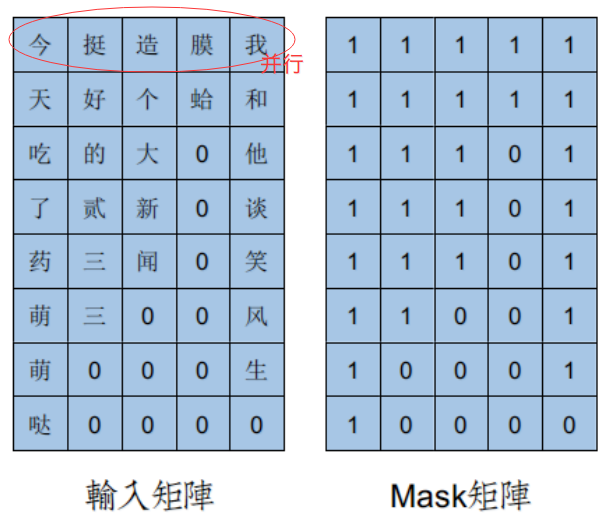
这个矩阵最大不同在于,xy轴是倒置的,文字方向在竖式伸展。
这么做的原因是由于theano.tensor.scan函数的工作机制。
scan函数的一旦sequence不为空,就进入序列循环模式,设sequence=[x],则
①Step1:取x[0]作为循环函数第一参数
②Step2:取x[1]作为循环函数第一参数
........
③StepN: 取x[N]作为循环函数第一参数
对应语言模型的序列学习算法,每个Step就相当于取一个句子的一个词。
竖式伸展,每次scan取的一排词,称为examples,数量等于batch_size。
横向batch并行,纵向序列时序伸展,这是mini-batch和序列学习的共同作用结果。
——————————————————————————————————————————
每个句子长度是不同的,为了便于并行矩阵计算,必须选定最长句子,最大化矩阵。句子词较少的,用0填充。
而在实际LSTM计算中,这个0填充则成了麻烦,因为你不能让标记为0的Padding参与递归网络计算,需要剔除。
这时候就需要Mask矩阵。来看LSTM.py中的实际代码:
$c = m\_[:, None] * c + (1. - m\_)[:, None] * c\_$
由于mask矩阵也在sequence中,所以m_被降成了1D,通过Numpy的第二维None扩充,可以和c([batch_size,dim_proj])
进行点乘(不是矩阵乘法)。
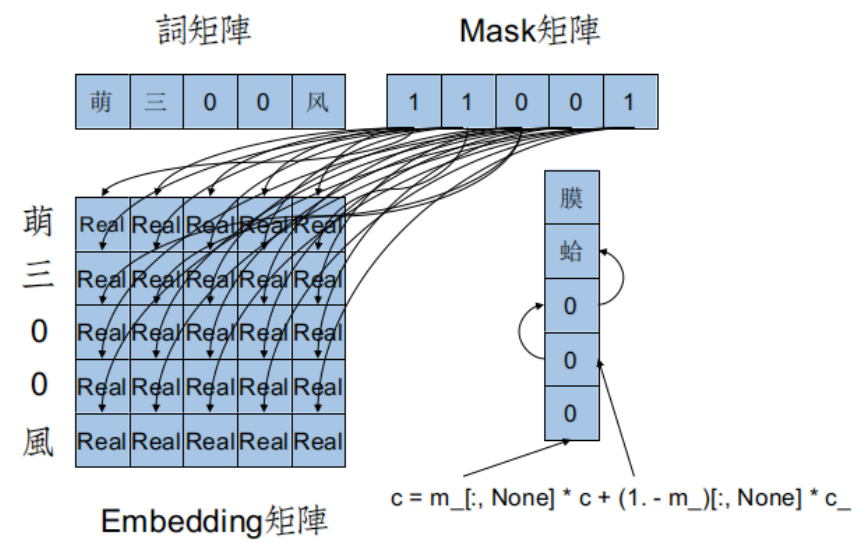
Mask矩阵的作用就是对于Padding,通过递推,直接滚到到上一个非0的状态,而不引入Padding。
源码解析
def get_minibatches_idx(n, minibatch_size, shuffle=False)
这部分设计对数据(句子)Shuffle随机排列。首先获取数据集所有句子数n,
对所有句子,按照batch_size,划分出 (n//batch_size)+1个列表。
拼在一起,构成一个二重列表。
返回一个zip(batch索引,batch内容),用于运行。
每份batch是一个列表,包含句子的索引。后续会根据句子的索引,拼出一个小量的x,
进过prepare_data处理过之后,方能使用。
def dropout_layer(state_before, use_noise, trng)
50%的Dropout,开了之后千万不要加Weght_Decay,两种一叠加,惩罚太重了。
Dropout的实现,利用了Tensor.switch(Bool,Ture Operation,False Operation)来动态实现。
传入的use_noise,在训练时置为1,这时候Dropout为动态概率屏蔽。
反之在测试时,置为0,这时候Dropout为平均网络。
具体原理见Hinton关于Dropout的论文:
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
def init_params(options)
这部分主要是初始化全部参数。分为两个部分:
①初始化Embedding参数、Softmax输出层参数
②初始化LSTM参数,在下面的 def param_init_lstm()函数中。
①中参数莫名其妙使用了[0,0.01]的随机值初始化,不知道为什么不用负值。
像Word2Vec的初始化,可能更好些:
$ Init \, sim \, Rand(frac{-0.5}{Emb\_Dim},frac{0.5}{Emb\_Dim}) $
Emb大小为$[VocabSize,Emb\_Dim]$,Softmax参数大小为$[Emb\_Dim,2]$
def param_init_lstm(options, params, prefix='lstm')
这部分用于初始化LSTM参数,W阵、U阵。
LSTM的初始化值很特殊,先用[0,1]随机数生成矩阵,然后对随机矩阵进行SVD奇异值分解。
取正交基矩阵来初始化,即 ortho_weight,原理不明,没有找到相关文献。
————————————————————————————————————————
值得注意的就是numpy.concatenate函数的使用,它锁定了AXIS=1轴(横向,列,第二维)
将Input、Forget、Output三态门与Cell的RNN核的相同操作$Wx+Uh^{'}$合并,并行计算。
如果$x$是$[1000,100]$,即$dim\_proj=100$, 那么$W$大小是$[100,100*4]$。
一次计算,有$Wx$的大小是$[1000,400]$,四个部分在矩阵中被并行计算了。
矩阵计算和FOR循环在串行算法下速度是差不多的,但是在并行算法下,矩阵同时计算比先后串行计算快不少。
def init_tparams(params)
这个函数意义就是一键将Numpy标准的params全部转为Theano.shared标准。
替代大量的Theano.shared(......)
启用tparams作为Model的正式params,而原来的params废弃。
def lstm_layer(tparams, state_below, options, prefix='lstm', mask=None)
LSTM的计算核心。
首先得注意参数state_below,这是个3D矩阵,$[n\_Step,BatchSize,Emb\_Dim]$
在scan函数的Sequence里,每步循环,都会降解第一维n_Step,得到一个Emb矩阵,作为输入$X\_$
计算过程:
①用 $[state\_below] cdot [lstm\_W]$。
这步很奇妙,这是一个3D矩阵与2D矩阵的乘法,由于每个Step,都需要做$Wx$
所以无须每一个Step做一次$Wx$,而是把所有Step的$Wx$预计算好了,并行量很大。
②进入scan函数过程,每一个Step:
I、将前一时序$h'$与4倍化$U$阵并行计算,并加上4倍化$Wx$的预计算
II、分离计算,按照LSTM结构定义,分别计算$Input Gate$、$Forget Gate$、$Outout Gate$
$ ilde{Cell}$、$Cell$、$h$
③返回rval[0],即h矩阵。注意,scan函数的输出结果会增加1D。
每个Step里,h结果是一个2D矩阵,$[BatchSize,Emb\_Dim]$
而rval[0]是一个3D矩阵,$[n\_Step,BatchSize,Emb\_Dim]$。
后续会对第一维$n\_Step$进行Mean Pooling,之后才能降解成用于Softmax的2D输入。
def sgd|adadelta|rmsprop(lr, tparams, grads, x, mask, y, cost)
这是三个可选梯度更新算法。由于作者想要保持格式一致,所以AdaDelta和RMSProp写的有点啰嗦。
AdaDelta详见我的 自适应学习率调整:AdaDelta
至于Hinton在2014 Winter的公开课提出的RMSProp,没有找到具体的数学推导,不好解释。
应该是由AdaDelta改良过来的,代码很费解。由可视化结果来看,RMSProp在某些特殊情况下,比AdaDelta要稳定。
官方代码里默认用的是AdaDelta,毕竟有Matthew D. Zeiler的论文详细推导与说明。
AdaDelta和RMSProp都是模拟二阶梯度更新,所以可以和Learning Rate这个恶心的超参说Bye~Bye了。值得把玩。
def build_model(tparams, options)
该部分是联合LSTM和Softmax,构成完整Theano.function的重要部分。
①首先是定义几个Tensor量,$x$、$y$、$mask$。
②接着,从tparams['Wemb']中取出Words*Sentences数量的词向量,并且变形为3D矩阵。
x.flatten()的使用非常巧妙,它将词矩阵拆成1D列表,然后按顺序取出词向量,然后再按顺序变形成3D形态。
体现了Python和Numpy的强大之处。
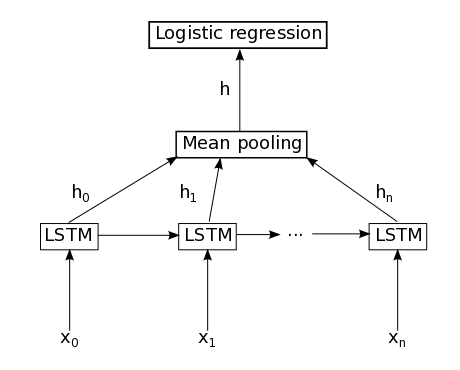
③得到3D的输入state_below之后,配合mask,经过LSTM,得到一个3D的h矩阵proj。
④对3D的h矩阵,各个时序进行Mean Pooling,得到2D矩阵,有点像Dropout的平均网络。
⑤Dropout处理
⑥Softmax、构建prob、pred、cost,都是老面孔了。
特别的是,这里有一个offset,防止prob爆0,造成log溢出。碰到这种情况可能不大。
def pred_probs|pred_error()
用于Cross-Validation计算Print信息。也就是Debug Mode...
def train_lstm()
训练过程。Theano代码块中最冗长、最臃肿的部分。
①options=locals().copy()是python中的一个小trick。
它能将函数中所有参数按爬虫下来,保存为一个词典,方便访问。
②load_data。定义在imdb.py中,获取train、vaild、test三个数据集
让人费解的是,既然这里要对test做shuffle,又何必在load_data里把test排序呢?
③初始化params,并且build_model,返回theano.function的pred、prob、cost。
④WeightDecay。有Dropout之后,必要性不大。
⑤利用cost,得到grad。利用tparams、grad,得到theano.function的update。
这里代码很啰嗦,如cost完全没有必要通过theano.function转化出来,保持Tensor状态是可以带入T.grad
而前面就没有这么写。代码风格和前面的章节截然不同。
至此,准备工作完毕,进入mini-batch执行阶段。
——————————————————————————————————————————————
①首先获取vaild和test的zip化minibatch。
每轮zip返回一个二元组(batch_idx,batch_content_list),idx实际并不用。
list是指当前batch中所有句子的idx。然后,对这些离散的idx,拼出实际的1D$x$。
经过imdb.py下的prepare_data,得到2D的$x$,作为Word Embedding的预备输入。
②进入max_epochs循环阶段:
包括early stopping优化,这部分与之前章节大致相同。
——————————————————————————————————————————————
至此,这份源码算是解析完了。