redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
redis是一个软件,帮助开发者对一台机器的内存进行操作
安装:
- redis软件 - yum install redis redis-server /etc/redis.conf 默认端口:6379 配置文件: bind 0.0.0.0 port 6379
特点:
1. 持久化 2. 单进程、单线程 3. 五大数据类型:字符串、列表、集合、有序集合、哈希类型(字典)
基于python操作redis:
import redis # 创建连接 # conn = redis.Redis(host='47.94.172.xxx',port=6379,password="xxx") # # conn.set('k1','neozheng',ex=5) # 在redis中设置 ;ex 表示超时时间 # 可以把redis看成一个在字典 # val = conn.get('k1') # 获取 # set()、get():redis的字符串操作 # print(val) # 连接池(推荐使用连接池;能提高性能) pool = redis.ConnectionPool(host='47.94.172.xxx',port=6379,password="xxx",max_connections=1000) # 创建连接池; max_connections 表示 最多创建1000个连接 conn = redis.Redis(connection_pool=pool) # 从连接池中取一个连接 conn.set('foo','Bar') # 设置值 """ 连接池优化: POOL = redis.ConnectionPool(host='47.94.172.xxx',port=6379,password="xxx",max_connections=1000) 把这个连接池改成单例模式,如: 放到另外一个 py文件中来导入 """
String操作:
redis中的String在在内存中按照一个name对应一个value来存储。如图:
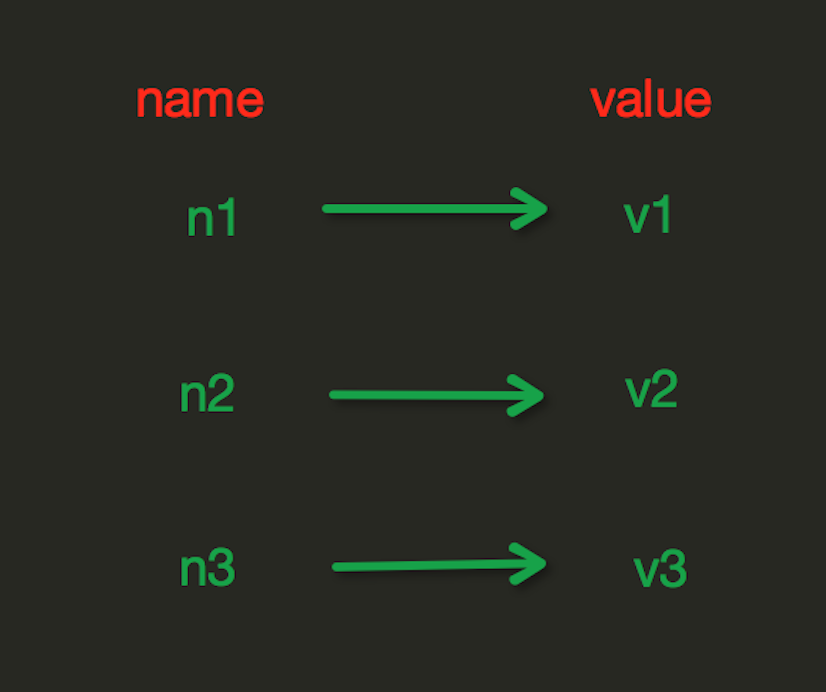
set(name, value, ex=None, px=None, nx=False, xx=False)
1 在Redis中设置值,默认,不存在则创建,存在则修改 2 参数: 3 ex,过期时间(秒) 4 px,过期时间(毫秒) 5 nx,如果设置为True,则只有name不存在时,当前set操作才执行 6 xx,如果设置为True,则只有name存在时,岗前set操作才执行
1 setnx(name, value) 2 # 设置值,只有name不存在时,执行设置操作(添加) 3 4 setex(name, value, time) 5 # 设置值 6 # 参数: 7 # time_ms,过期时间(数字毫秒 或 timedelta对象) 8 9 mset(*args, **kwargs) 10 批量设置值 11 如: 12 mset(k1='v1', k2='v2') 13 或 14 mget({'k1': 'v1', 'k2': 'v2'}) 15 16 get(name) 17 获取值 18 19 mget(keys, *args) 20 批量获取 21 如: 22 mget('k1', 'k2') 23 或 24 r.mget(['k1', 'k2']) 25 26 getset(name, value) 27 设置新值并获取原来的值 28 29 getrange(key, start, end) 30 31 # 获取子序列(根据字节获取,非字符) 32 # 参数: 33 # name,Redis 的 name 34 # start,起始位置(字节) 35 # end,结束位置(字节) 36 # 如: "苍井空" ,0-3表示 "苍" 37 38 setrange(name, offset, value) 39 # 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) 40 # 参数: 41 # offset,字符串的索引,字节(一个汉字三个字节) 42 # value,要设置的值 43 44 strlen(name) 45 # 返回name对应值的字节长度(一个汉字3个字节) 46 47 incr(self, name, amount=1) 48 # 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 49 50 # 参数: 51 # name,Redis的name 52 # amount,自增数(必须是整数) 53 54 # 注:同incrby 55 56 incrbyfloat(self, name, amount=1.0) 57 # 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 58 59 # 参数: 60 # name,Redis的name 61 # amount,自增数(浮点型) 62 63 decr(self, name, amount=1) 64 # 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 65 66 # 参数: 67 # name,Redis的name 68 # amount,自减数(整数) 69 70 append(key, value) 71 # 在redis name对应的值后面追加内容 72 73 # 参数: 74 key, redis的name 75 value, 要追加的字符串
Hash操作:
redis中Hash在内存中的存储格式如下图:
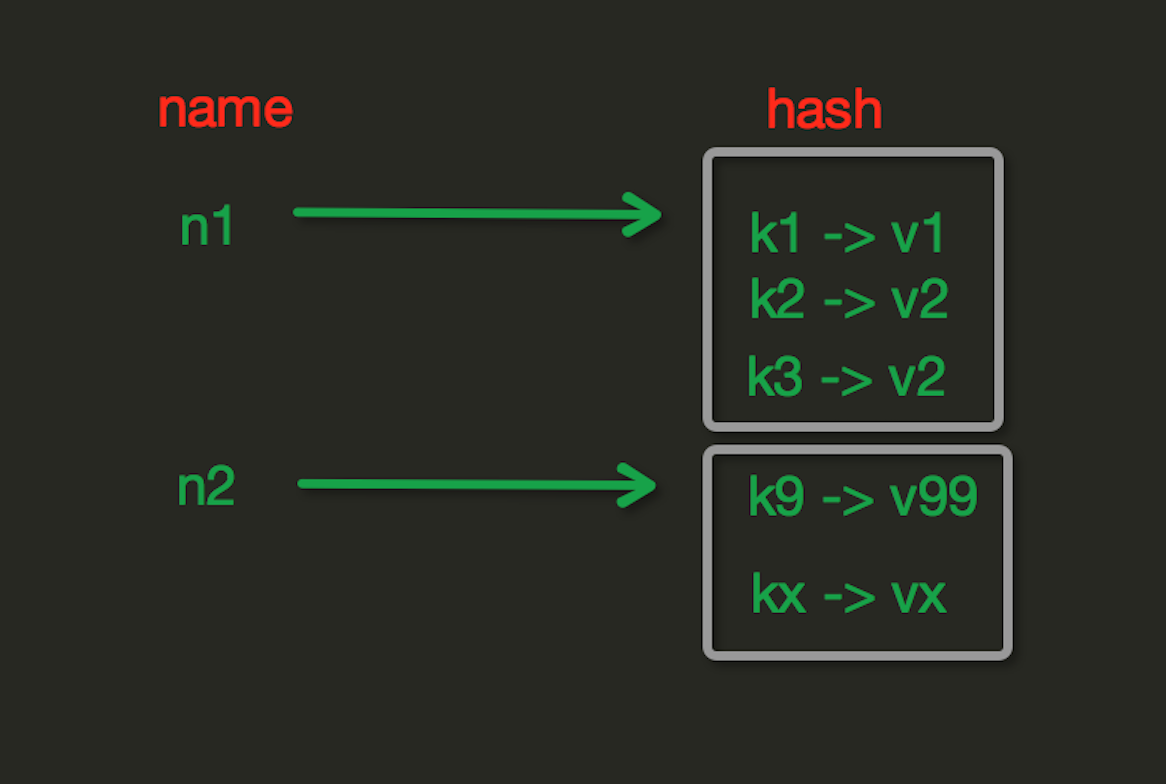
hset(name, key, value)
1 # name对应的hash中设置一个键值对(不存在,则创建;否则,修改) 2 3 # 参数: 4 # name,redis的name 5 # key,name对应的hash中的key 6 # value,name对应的hash中的value 7 8 # 注: 9 # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
1 # 在name对应的hash中批量设置键值对 2 3 # 参数: 4 # name,redis的name 5 # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} 6 7 # 如: 8 # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
1 # 在name对应的hash中获取多个key的值 2 3 # 参数: 4 # name,reids对应的name 5 # keys,要获取key集合,如:['k1', 'k2', 'k3'] 6 # *args,要获取的key,如:k1,k2,k3 7 8 # 如: 9 # r.mget('xx', ['k1', 'k2']) 10 # 或 11 # print r.hmget('xx', 'k1', 'k2')
hgetall(name) # 获取name对应hash的所有键值(key和value);注:redis中存储的都是 bytes 格式 hlen(name) # 获取name对应的hash中键值对的个数 hkeys(name) # 获取name对应的hash中所有的key的值 hvals(name) # 获取name对应的hash中所有的value的值 hexists(name, key) # 检查name对应的hash是否存在当前传入的key hdel(name,*keys) # 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
1 # 自增name对应的hash中的指定key的值,不存在则创建key=amount 2 # 参数: 3 # name,redis中的name 4 # key, hash对应的key 5 # amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
1 # 自增name对应的hash中的指定key的值,不存在则创建key=amount 2 3 # 参数: 4 # name,redis中的name 5 # key, hash对应的key 6 # amount,自增数(浮点数) 7 8 # 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数: # name,redis的name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter('xx'): # print item
补充:
问题:如果redis的某个key对应的字典中有 1000w条数据,要求打印所有的数据 # 不可取:从redis取到数据之后,服务器内存无法承受,爆栈(切记不要用这种方式) # res = conn.hgetall('key') # print(res) # 正确做法: ret = conn.hscan_iter('key',count=100) # ret是一个生成器;count=100 表示每次取100个 for item in ret: print(item) 注意:redis操作时,只有第一层的value支持 列表、字典等的操作
自定义连接池:
urls.py
from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^index/', views.index), url(r'^order/', views.order), ]
app01/views.py
import redis from django.shortcuts import render,HttpResponse from utils.redis_pool import POOL # 导入自定义连接池 def index(request): conn = redis.Redis(connection_pool=POOL) # 取一个连接 conn.hset('kkk','age',18) return HttpResponse('设置成功') def order(request): conn = redis.Redis(connection_pool=POOL) conn.hget('kkk','age') return HttpResponse('获取成功')
utils/redis_pool.py
import redis POOL = redis.ConnectionPool(host='10.211.55.4', port=6379,password='luffy1234',max_connections=1000)
使用第三方组件 django_redis:(只有django有这个组件)
settings.py中关于redis的配置:
# redis配置 CACHES = { "default": { # 频率限制组件的记录 session 就是放到了 这个名为 "default" 的缓存中 "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100} # "PASSWORD": "密码", } }, "back": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", "CONNECTION_POOL_KWARGS": {"max_connections": 100} # "PASSWORD": "密码", } } }
views.py
from django.shortcuts import render,HttpResponse from django_redis import get_redis_connection # django_redis组件中的功能 def index(request): conn = get_redis_connection("default") # settings 中名为 "default" 的连接池 return HttpResponse('设置成功') def order(request): conn = get_redis_connection("back") # settings 中名为 "back" 的连接池 return HttpResponse('获取成功')
redis全站缓存:
只需在 setting.py 中配置中间件:
MIDDLEWARE = [ 'django.middleware.cache.UpdateCacheMiddleware', # 只有一个 process_response,即只处理响应;作用:从数据库获取数据后,给用户一份,同时放到redis缓存中一份;这个只处理响应的中间件放在第一个是因为:应该等其它中间件完成处理之后(如写cookie、设置其它的响应头等),再添加自己写的响应处理 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', 'django.middleware.cache.FetchFromCacheMiddleware', # 只有一个 process_request,即只处理请求;作用:先去redis中看有没有对应数据的缓存,如果有就获取该数据,如果没有就去数据库中取数据;这个只处理请求的中间件放到最后是因为:其它中间件的检验全部通过之后才能让它获取数据 ]
django已经把其它的给你配置好了.
另外,超时时间的配置:
CACHE_MIDDLEWARE_SECONDS = ""
单视图缓存:
from django.views.decorators.cache import cache_page @cache_page(60*15) # 单视图缓存装饰器; ()中的参数是超时时间 # 这个的优先级比全局的要高 def index(request): ctime = str(time.time()) return HttpResponse(ctime)
局部视图缓存:
a. 引入TemplateTag {% load cache %} b. 使用缓存 {% cache 5000 缓存key %} 缓存内容 {% endcache %}
# 5000表示超时时间5000秒
补充:rest framework框架访问频率限制推荐放到 redis/memcached
List操作:
redis中的List在在内存中按照一个name对应一个List来存储。如图:

lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如: # r.lpush('oo', 11,22,33) # 保存顺序为: 33,22,11 # 扩展: # rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多: # rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数: # name,redis的name # index,list的索引位置 # value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多: # rpop(name) 表示从右向左操作
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 # 参数: # src,要取数据的列表的name # dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素 # 参数: # keys,redis的name的集合 # timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 # 更多: # r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧 # 参数: # src,取出并要移除元素的列表对应的name # dst,要插入元素的列表对应的name # timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
补充:
# 队列:先进先出; # 栈:先进后出
列表 自定义增量迭代:
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要: # 1、获取name对应的所有列表 # 2、循环列表 # 但是,如果列表非常大,那么就有可能在第一步时就将程序的内存撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name,count=100): # 默认一次取100个 """ 自定义redis列表增量迭代 :param name: redis中的name,即:迭代name对应的列表 :return: yield 返回 列表元素 """ index = 0 while True: data_list = conn.lrange(name,index,index+count-1) if not data_list: return index += count for item in data_list: yield item # 使用 for item in list_iter('pp',count=10): print(item)
其他常用操作:
1 delete(*names) 2 # 根据删除redis中的任意数据类型 3 4 exists(name) 5 # 检测redis的name是否存在 6 7 keys(pattern='*') 8 9 # 根据模型获取redis的name 10 # 更多: 11 # KEYS * 匹配数据库中所有 key 。 12 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 13 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 14 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo 15 16 expire(name ,time) 17 # 为某个redis的某个name设置超时时间(设置的是时间间隔) 18 19 rename(src, dst) 20 # 对redis的name重命名为 21 22 move(name, db)) 23 # 将redis的某个值移动到指定的db下 24 25 randomkey() 26 # 随机获取一个redis的name(不删除) 27 28 type(name) 29 # 获取name对应值的类型 30 31 scan(cursor=0, match=None, count=None) 32 scan_iter(match=None, count=None) # 迭代获取 redis 的 name 33 # 同字符串操作,用于增量迭代获取key;match可用 * 这种正则表达来匹配;count 表示 一次取多少个
事务--管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) # transaction=True 事务:要成功都成功,要失败都失败 pipe.multi() # 表示要做批量操作 pipe.set('name', 'alex') pipe.set('role', 'sb') pipe.execute() # 执行
小结:
redis列表: - 左右都能操作 - hang住 (b:block) - 数据特别多的时候,通过yield构造一个生成器 redis字典: - hscan_iter 事务: 连接池 单进程、单线程 持久化:(FAII) - AOF - RDB