大端编码方式:字数据的高字节存储在低地址中。
小端编码方式:字数据的低字节存储在低地址中。
简单而直观地说,大端的存储是顺序的,小端的存储是逆序的(当然这种理解方式是不严谨的)。
看了下一篇CSDN博客写得挺全面,文末会给出相关地址,不过内容实在是有点太多了,所以还是自己写写学习笔记吧,虽然不是新知识了,温故而知新总是好的。
在这里请允许我摘录自己需要的那部分:
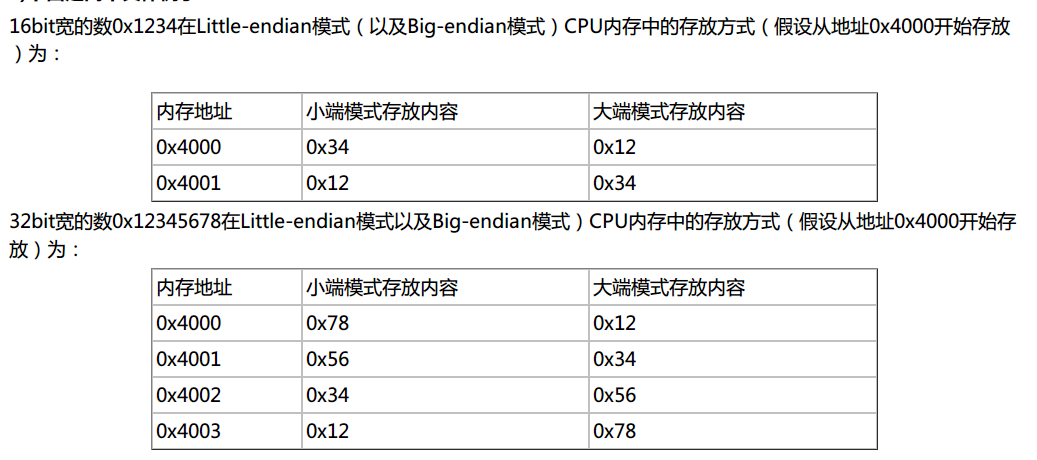
另有就是面试的时候经常会遇到的,写一个小程序判断编译器是大端还是小端模式(大端返回0,小端返回1):
int JudgeEndingFormat1() { { union w { int a; char b; } c; c.a = 1; return(c.b == 1); } }
每次看到这个代码都觉得很蛋疼,主要是因为自己理解得本来就不是特别深刻,所以给出另外一种更直观明了的判断方法:
int JudgeEndingFormat3() { union w { int a; char b; }c; c.a = 0x1234; return (c.b == 0x12); }
因为联合体的中所有成员都是从低地址开始存放的,所以直接去比较c.b和0x12的值即可,如果相同,那就说明是大端格式了(返回1);如果不同,那就说明是小端格式了(返回0)。
大小端问题来源:
大小端地址是怎么来的?
在操作系统中我们存储数据以字节为单位,一个字节byte型8个bit,char型short型16个bit,还有int型float型long型(取决于编译器)32个bit,double的64个bit。这个时候就需要区分存储模式了。
而int型和long型又要取决于平台和编译器,比如编写C或者C++程序,有时考虑到跨平台的兼容性问题,我们就需要明确使用__int8, __int16, __int32, __int64。
实际问题:
实际上,操作系统一般都是小端的,而像Java和所有网络通信协议都是大端的,所以当我们进行网络编程如socket编程的时候就要注意这点,也因此我们经常需要用到这些函数ntohs()、htons()、ntohl()和htonl()等进行大小端字节序的转换(不过应用的时候我只会照搬照套,实际上理解得并不深刻)。
如果想要再深入理解的话,就要翻翻计算机操作系统相关的书籍了。这方面的相关知识实在是太薄弱了...《现代操作系统》这本书不错,《自己动手写操作系统》这本书听说也很好,名字听着就显得很亲民——自己写。。。有机会要读一读写一写。
如果还想了解一下其他相关知识,可以参考下面的博文: