| 姓名 | 今日任务 | 明日任务 |
| 黄新越 | 按照热度排序->产生柱状图 | 按照热度排序->产生柱状图 |
| 刘垚鹏 | 1增设选择网址txt文件按钮,原本的yes+start按钮弹出选择文件框设计不友好 2没有网址或者没有输入数字都会出异常但是无法弹出窗口提示用户的bug修复 |
总体代码架构整合 |
| 王骜 | 记录爬取时间并且实时动态显示:爬取成功网页数,过滤网页数,根据分类显示对应百分比柱状图 | 总体代码架构整合 |
| 林旭鹏 | 修复(聚集型)关键字爬取功能无法进行中文关键字的爬取bug | 优化整体UI布局 |
| 安康 | 没有网址或者没有输入数字都会出异常但是无法弹出窗口提示用户的bug修复 | 优化整体UI布局 |
| 黄伟龙 | 爬虫程序现有BUG的测试 | 预先合作编写测试用例 |
| 马佐霖 | 爬虫程序现有BUG的测试 | 预先合作编写测试用例 |
| 李桐 | 爬虫程序现有BUG的测试与会议记录 | 预先合作编写测试用例与会议记录 |
大家的任务确实基本都完成了,明天将黄新越的代码功能整合到我们的已有程序中迭代一的任务就算初步成型了。到目前为止迭代一有三个问题,一是饼状图依然没有实现动态效果,这个经过研究如果要改的话还要改API,具体会不会继续完善我们在下一轮迭代中会进行需求分析讨论性价比后再做决定。二是目前的(综合型)链接+关键字爬取的过滤算法算法相对比较简单,虽然适用于大多数的网页筛选,但是有些特殊的网页不能有效的进行过滤,造成符合条件的网页的流失,更加精确的算法的研究和实现将放在下一轮迭代中;三是暂停后已经正在下载的文件会继续下载,这个问题我们也准备留到下一轮迭代,应该不会很难。
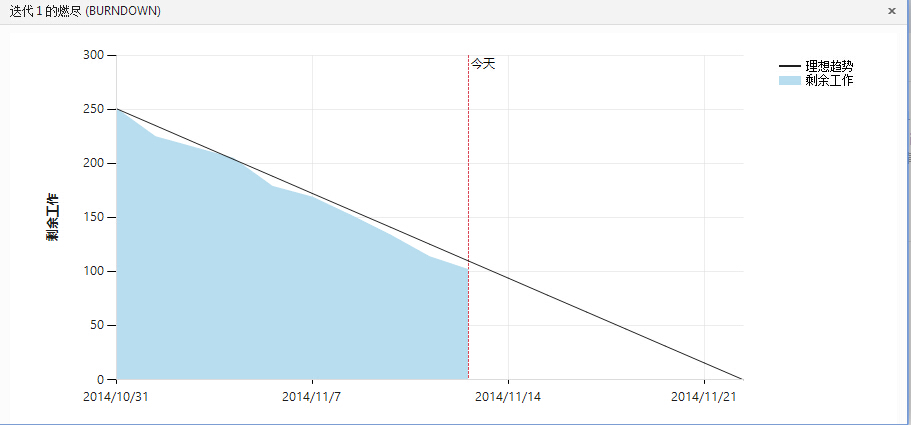
燃尽图如下:(P.S这个燃尽图真的没有糊弄作假,我们这一轮迭代在短时间内集中开了两三次会后完成的确实比较顺利)