转:
漫谈linux文件IO
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO。本篇文件打算详细全面,深入浅出。剖析文件IO的细节。从多个角度探索如何提高IO性能。本文尽量用通俗易懂的视角去阐述。不copy内核代码。
阐述之前,要先有个大视角,让我们站在万米高空,鸟瞰我们的文件IO,它们设计是分层的,分层有2个好处,一是架构清晰,二是解耦。让我们看一下下面这张图。

图一
1. 穿越各层写文件方式
程序的最终目的是要把数据写到磁盘上, 但是系统从通用性和性能角度,尽量提供一个折中的方案来保证这些。让我们来看一个最常用的写文件典型example,也是路径最长的IO。
{
char *buf = malloc(MAX_BUF_SIZE);
strncpy(buf, src, , MAX_BUF_SIZE);
fwrite(buf, MAX_BUF_SIZE, 1, fp);
fclose(fp);
}
这里malloc的buf对于图层中的application buffer,即应用程序的buffer;调用fwrite后,把数据从application buffer 拷贝到了 CLib buffer,即C库标准IObuffer。fwrite返回后,数据还在CLib buffer,如果这时候进程core掉。这些数据会丢失。没有写到磁盘介质上。当调用fclose的时候,fclose调用会把这些数据刷新到磁盘介质上。除了fclose方法外,还有一个主动刷新操作fflush 函数,不过fflush函数只是把数据从CLib buffer 拷贝到page cache 中,并没有刷新到磁盘上,从page cache刷新到磁盘上可以通过调用fsync函数完成。
从上面类子看到,一个常用的fwrite函数过程,基本上历经千辛万苦,数据经过多次copy,才到达目的地。有人心生疑问,这样会提高性能吗,反而会降低性能吧。这个问题先放一放。
有人说,我不想通过fwrite+fflush这样组合,我想直接写到page cache。这就是我们常见的文件IO调用read/write函数。这些函数基本上是一个函数对应着一个系统调用,如sys_read/sys_write. 调用write函数,是直接通过系统调用把数据从应用层拷贝到内核层,从application buffer 拷贝到 page cache 中。
系统调用,write会触发用户态/内核态切换?是的。那有没有办法避免这些消耗。这时候该mmap出场了,mmap把page cache 地址空间映射到用户空间,应用程序像操作应用层内存一样,写文件。省去了系统调用开销。
那如果继续刨根问底,如果想绕过page cache,直接把数据送到磁盘设备上怎么办。通过open文件带上O_DIRECT参数,这是write该文件。就是直接写到设备上。
如果继续较劲,直接写扇区有没有办法。这就是所谓的RAW设备写,绕开了文件系统,直接写扇区,想fdsik,dd,cpio之类的工具就是这一类操作。
2. IO调用链
列举了上述各种穿透各种cache 层写操作,可以看到系统提供的接口相当丰富,满足你各种写要求。下面通过讲解图一,了解一下文件IO的调用链。
fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个buffer,将多次小数据量相邻写操作先缓存起来,合并,最终调用write函数一次性写入(或者将大块数据分解多次write调用)。
Write函数通过调用系统调用接口,将数据从应用层copy到内核层,所以write会触发内核态/用户态切换。当数据到达page cache后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write是一个异步调用。这一点和read不同,read调用是先检查page cache里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。当然你也可以把write的异步过程改成同步过程,就是在open文件的时候带上O_SYNC标记。
数据到了page cache后,内核有pdflush线程在不停的检测脏页,判断是否要写回到磁盘中。把需要写回的页提交到IO队列——即IO调度队列。又IO调度队列调度策略调度何时写回。
提到IO调度队列,不得不提一下磁盘结构。这里要讲一下,磁头和电梯一样,尽量走到头再回来,避免来回抢占是跑,磁盘也是单向旋转,不会反复逆时针顺时针转的。从网上copy一个图下来,具体这里就不介绍。
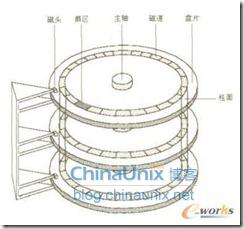
IO队列有2个主要任务。一是合并相邻扇区的,而是排序。合并相信很容易理解,排序就是尽量按照磁盘选择方向和磁头前进方向排序。因为磁头寻道时间是和昂贵的。
这里IO队列和我们常用的分析工具IOStat关系密切。IOStat中rrqm/s wrqm/s表示读写合并个数。avgqu-sz表示平均队列长度。
内核中有多种IO调度算法。当硬盘是SSD时候,没有什么磁道磁头,人家是随机读写的,加上这些调度算法反而画蛇添足。OK,刚好有个调度算法叫noop调度算法,就是什么都不错(合并是做了)。刚好可以用来配置SSD硬盘的系统。
从IO队列出来后,就到了驱动层(当然内核中有更多的细分层,这里忽略掉),驱动层通过DMA,将数据写入磁盘cache。
至于磁盘cache时候写入磁盘介质,那是磁盘控制器自己的事情。如果想要睡个安慰觉,确认要写到磁盘介质上。就调用fsync函数吧。可以确定写到磁盘上了。
3. 一致性和安全性
谈完调用细节,再将一下一致性问题和安全问题。既然数据没有到到磁盘介质前,可能处在不同的物理内存cache中,那么如果出现进程死机,内核死,掉电这样事件发生。数据会丢失吗。
当进程死机后:只有数据还处在application cache或CLib cache时候,数据会丢失。数据到了page cache。进程core掉,即使数据还没有到硬盘。数据也不会丢失。
当内核core掉后,只要数据没有到达disk cache,数据都会丢失。
掉电情况呢,哈哈,这时候神也救不了你,哭吧。
那么一致性呢,如果两个进程或线程同时写,会写乱吗?或A进程写,B进程读,会写脏吗?
文章写到这里,写得太长了,就举出各种各样的例子。讲一下大概判断原则吧。fwrite操作的buffer是在进程私有空间,两个线程读写,肯定需要锁保护的。如果进程,各有各的地址空间。是否要加锁,看应用场景。
write操作如果写大小小于PIPE_BUF(一般是4096),是原子操作,能保证两个进程“AAA”,“BBB”写操作,不会出现“ABAABB”这样的数据交错。O_APPEND 标志能保证每次重新计算pos,写到文件尾的原子性。
数据到了内核层后,内核会加锁,会保证一致性的。
4. 性能问题
性能从系统层面和设备层面去分析;磁盘的物理特性从根本上决定了性能。IO的调度策略,系统调用也是致命杀手。
磁盘的寻道时间是相当的慢,平均寻道时间大概是在10ms,也就是是每秒只能100-200次寻道。
磁盘转速也是影响性能的关键,目前最快15000rpm,大概就每秒500转,满打满算,就让磁头不寻道,设想所有的数据连续存放在一个柱面上。大家可以算一下每秒最多可以读多少数据。当然这个是理论值。一般情况下,盘片转太快,磁头感应跟不上,所以需要转几圈才能完全读出磁道内容。
另外设备接口总线传输率是实际速率的上限。
另外有些等密度磁盘,磁盘外围磁道扇区多,线速度快,如果频繁操作的数据放在外围扇区,也能提高性能。
利用多磁盘并发操作,也不失为提高性能的手段。
这里给个业界经验值:机械硬盘顺序写~30MB,顺序读取速率一般~50MB好的可以达到100多M, SSD读达到~400MB,SSD写性能和机械硬盘差不多。
Ps:
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。
而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。
一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。
而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。
两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
《直接io的优缺点》https://www.ibm.com/developerworks/cn/linux/l-cn-directio/
《aio和direct io关系以及DMA》http://blog.csdn.net/brucexu1978/article/details/7085924
《io模型矩阵》http://www.ibm.com/developerworks/cn/linux/l-async/
《为什么nginx引入多线程:减少阻塞IO影响》http://www.aikaiyuan.com/10228.html
《aio机制在nginx之中的使用:output chain 》http://www.aikaiyuan.com/8867.html
《nginx对Linux native AIO机制的封装》http://www.aikaiyuan.com/8869.html
《nginx output chain 分析》https://my.oschina.net/astute/blog/316954
《sendfile和read/write的内核切换次数》http://www.cnblogs.com/zfyouxi/p/4196170.html
Linux 2.6 中的直接 I/O 技术
所有的 I/O 操作都是通过读文件或者写文件来完成的。在这里,我们把所有的外围设备,包括键盘和显示器,都看成是文件系统中的文件。访问文件的方法多种多样,这里列出下边这几种 Linux 2.6 中支持的文件访问方式。
在 Linux 中,这种访问文件的方式是通过两个系统调用实现的:read() 和 write()。当应用程序调用 read() 系统调用读取一块数据的时候,如果该块数据已经在内存中了,那么就直接从内存中读出该数据并返回给应用程序;如果该块数据不在内存中,那么数据会被从磁盘上读到页高缓存中去,然后再从页缓存中拷贝到用户地址空间中去。如果一个进程读取某个文件,那么其他进程就都不可以读取或者更改该文件;对于写数据操作来说,当一个进程调用了 write() 系统调用往某个文件中写数据的时候,数据会先从用户地址空间拷贝到操作系统内核地址空间的页缓存中去,然后才被写到磁盘上。但是对于这种标准的访问文件的方式来说,在数据被写到页缓存中的时候,write() 系统调用就算执行完成,并不会等数据完全写入到磁盘上。Linux 在这里采用的是我们前边提到的延迟写机制( deferred writes )。
图1.以标准方式对文件进行读写

同步访问文件的方式与上边这种标准的访问文件的方式比较类似,这两种方法一个很关键的区别就是:同步访问文件的时候,写数据的操作是在数据完全被写回磁盘上才算完成的;而标准访问文件方式的写数据操作是在数据被写到页高速缓冲存储器中的时候就算执行完成了。
图2.数据同步写回磁盘

在很多操作系统包括 Linux 中,内存区域( memory region )是可以跟一个普通的文件或者块设备文件的某一个部分关联起来的,若进程要访问内存页中某个字节的数据,操作系统就会将访问该内存区域的操作转换为相应的访问文件的某个字节的操作。Linux 中提供了系统调用 mmap() 来实现这种文件访问方式。与标准的访问文件的方式相比,内存映射方式可以减少标准访问文件方式中 read() 系统调用所带来的数据拷贝操作,即减少数据在用户地址空间和操作系统内核地址空间之间的拷贝操作。映射通常适用于较大范围,对于相同长度的数据来讲,映射所带来的开销远远低于 CPU 拷贝所带来的开销。当大量数据需要传输的时候,采用内存映射方式去访问文件会获得比较好的效率。
图3.利用mmap代替read

凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存的支持。操作系统层提供的缓存往往会使应用程序在读写数据的时候获得更好的性能,但是对于某些特殊的应用程序,比如说数据库管理系统这类应用,他们更倾向于选择他们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
图四.数据传输不经过操作系统内核缓冲区

Linux 异步 I/O 是 Linux 2.6 中的一个标准特性,其本质思想就是进程发出数据传输请求之后,进程不会被阻塞,也不用等待任何操作完成,进程可以在数据传输的时候继续执行其他的操作。相对于同步访问文件的方式来说,异步访问文件的方式可以提高应用程序的效率,并且提高系统资源利用率。直接 I/O 经常会和异步访问文件的方式结合在一起使用。
图5.CPU处理其他任务和I/O操作可以重叠进行

Linux 2.6 中直接 I/O 的设计与实现
在块设备或者网络设备中执行直接 I/O 完全不用担心实现直接 I/O 的问题,Linux 2.6 操作系统内核中高层代码已经设置和使用了直接 I/O,驱动程序级别的代码甚至不需要知道已经执行了直接 I/O;但是对于字符设备来说,执行直接 I/O 是不可行的,Linux 2.6 提供了函数 get_user_pages() 用于实现直接 I/O。本小节会分别对这两种情况进行介绍。
内核为块设备执行直接 I/O 提供的支持
要在块设备中执行直接 I/O,进程必须在打开文件的时候设置对文件的访问模式为 O_DIRECT,这样就等于告诉操作系统进程在接下来使用 read() 或者 write() 系统调用去读写文件的时候使用的是直接 I/O 方式,所传输的数据均不经过操作系统内核缓存空间。使用直接 I/O 读写数据必须要注意缓冲区对齐( buffer alignment )以及缓冲区的大小的问题,即对应 read() 以及 write() 系统调用的第二个和第三个参数。这里边说的对齐指的是文件系统块大小的对齐,缓冲区的大小也必须是该块大小的整数倍。
这一节主要介绍三个函数:open(),read() 以及 write()。Linux 中访问文件具有多样性,所以这三个函数对于处理不同的文件访问方式定义了不同的处理方法,本文主要介绍其与直接 I/O 方式相关的函数与功能.首先,先来看 open() 系统调用,其函数原型如下所示:
|
1
|
int open(const char *pathname, int oflag, … /*, mode_t mode * / ) ; |
以下列出了 Linux 2.6 内核定义的系统调用 open() 所使用的标识符宏定义:
表 1. open() 系统调用提供的标识符
当应用程序需要直接访问文件而不经过操作系统页高速缓冲存储器的时候,它打开文件的时候需要指定 O_DIRECT 标识符。
操作系统内核中处理 open() 系统调用的内核函数是 sys_open(),sys_open() 会调用 do_sys_open() 去处理主要的打开操作。它主要做了三件事情:首先, 它调用 getname() 从进程地址空间中读取文件的路径名;接着,do_sys_open() 调用 get_unused_fd() 从进程的文件表中找到一个空闲的文件表指针,相应的新文件描述符就存放在本地变量 fd 中;之后,函数 do_filp_open() 会根据传入的参数去执行相应的打开操作。清单 1 列出了操作系统内核中处理 open() 系统调用的一个主要函数关系图。
清单 1. 主要调用函数关系图
|
1
2
3
4
5
6
7
|
sys_open() |-----do_sys_open() |---------getname() |---------get_unused_fd() |---------do_filp_open() |--------nameidata_to_filp() |----------__dentry_open() |
函数 do_flip_open() 在执行的过程中会调用函数 nameidata_to_filp(),而 nameidata_to_filp() 最终会调用 __dentry_open() 函数,若进程指定了 O_DIRECT 标识符,则该函数会检查直接 I./O 操作是否可以作用于该文件。清单 2 列出了 __dentry_open() 函数中与直接 I/O 操作相关的代码。
清单 2. 函数 dentry_open() 中与直接 I/O 相关的代码
|
1
2
3
4
5
6
7
8
|
if (f->f_flags & O_DIRECT) { if (!f->f_mapping->a_ops || ((!f->f_mapping->a_ops->direct_IO) && (!f->f_mapping->a_ops->get_xip_page))) { fput(f); f = ERR_PTR(-EINVAL); } } |
当文件打开时指定了 O_DIRECT 标识符,那么操作系统就会知道接下来对文件的读或者写操作都是要使用直接 I/O 方式的。
下边我们来看一下当进程通过 read() 系统调用读取一个已经设置了 O_DIRECT 标识符的文件的时候,系统都做了哪些处理。 函数 read() 的原型如下所示:
|
1
|
ssize_t read(int feledes, void *buff, size_t nbytes) ; |
操作系统中处理 read() 函数的入口函数是 sys_read(),其主要的调用函数关系图如下清单 3 所示:
清单 3. 主调用函数关系图
|
1
2
3
4
5
|
sys_read() |-----vfs_read() |----generic_file_read() |----generic_file_aio_read() |--------- generic_file_direct_IO() |
函数 sys_read() 从进程中获取文件描述符以及文件当前的操作位置后会调用 vfs_read() 函数去执行具体的操作过程,而 vfs_read() 函数最终是调用了 file 结构中的相关操作去完成文件的读操作,即调用了 generic_file_read() 函数,其代码如下所示:
清单 4. 函数 generic_file_read()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
ssize_t generic_file_read(struct file *filp, char __user *buf, size_t count, loff_t *ppos) { struct iovec local_iov = { .iov_base = buf, .iov_len = count }; struct kiocb kiocb; ssize_t ret; init_sync_kiocb(&kiocb, filp); ret = __generic_file_aio_read(&kiocb, &local_iov, 1, ppos); if (-EIOCBQUEUED == ret) ret = wait_on_sync_kiocb(&kiocb); return ret; } |
函数 generic_file_read() 初始化了 iovec 以及 kiocb 描述符。描述符 iovec 主要是用于存放两个内容:用来接收所读取数据的用户地址空间缓冲区的地址和缓冲区的大小;描述符 kiocb 用来跟踪 I/O 操作的完成状态。之后,函数 generic_file_read() 凋用函数 __generic_file_aio_read()。该函数检查 iovec 中描述的用户地址空间缓冲区是否可用,接着检查访问模式,若访问模式描述符设置了 O_DIRECT,则执行与直接 I/O 相关的代码。函数 __generic_file_aio_read() 中与直接 I/O 有关的代码如下所示:
清单 5. 函数 __generic_file_aio_read() 中与直接 I/O 有关的代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
if (filp->f_flags & O_DIRECT) { loff_t pos = *ppos, size; struct address_space *mapping; struct inode *inode; mapping = filp->f_mapping; inode = mapping->host; retval = 0; if (!count) goto out; size = i_size_read(inode); if (pos < size) { retval = generic_file_direct_IO(READ, iocb, iov, pos, nr_segs); if (retval > 0 && !is_sync_kiocb(iocb)) retval = -EIOCBQUEUED; if (retval > 0) *ppos = pos + retval; } file_accessed(filp); goto out; } |
上边的代码段主要是检查了文件指针的值,文件的大小以及所请求读取的字节数目等,之后,该函数调用 generic_file_direct_io(),并将操作类型 READ,描述符 iocb,描述符 iovec,当前文件指针的值以及在描述符 io_vec 中指定的用户地址空间缓冲区的个数等值作为参数传给它。当 generic_file_direct_io() 函数执行完成,函数 __generic_file_aio_read()会继续执行去完成后续操作:更新文件指针,设置访问文件 i 节点的时间戳;这些操作全部执行完成以后,函数返回。 函数 generic_file_direct_IO() 会用到五个参数,各参数的含义如下所示:
- rw:操作类型,可以是 READ 或者 WRITE
- iocb:指针,指向 kiocb 描述符
- iov:指针,指向 iovec 描述符数组
- offset:file 结构偏移量
- nr_segs:iov 数组中 iovec 的个数
|
1
|
函数 generic_file_direct_IO() 代码如下所示: |
清单 6. 函数 generic_file_direct_IO()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
static ssize_t generic_file_direct_IO(int rw, struct kiocb *iocb, const struct iovec *iov, loff_t offset, unsigned long nr_segs) { struct file *file = iocb->ki_filp; struct address_space *mapping = file->f_mapping; ssize_t retval; size_t write_len = 0; if (rw == WRITE) { write_len = iov_length(iov, nr_segs); if (mapping_mapped(mapping)) unmap_mapping_range(mapping, offset, write_len, 0); } retval = filemap_write_and_wait(mapping); if (retval == 0) { retval = mapping->a_ops->direct_IO(rw, iocb, iov, offset, nr_segs); if (rw == WRITE && mapping->nrpages) { pgoff_t end = (offset + write_len - 1) >> PAGE_CACHE_SHIFT; int err = invalidate_inode_pages2_range(mapping, offset >> PAGE_CACHE_SHIFT, end); if (err) retval = err; } } return retval; } |
函数 generic_file_direct_IO() 对 WRITE 操作类型进行了一些特殊处理,这在下边介绍 write() 系统调用的时候再做说明。除此之外,它主要是调用了 direct_IO 方法去执行直接 I/O 的读或者写操作。在进行直接 I/O 读操作之前,先将页缓存中的相关脏数据刷回到磁盘上去,这样做可以确保从磁盘上读到的是最新的数据。这里的 direct_IO 方法最终会对应到 __blockdev_direct_IO() 函数上去。__blockdev_direct_IO() 函数的代码如下所示:
清单 7. 函数 __blockdev_direct_IO()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
ssize_t __blockdev_direct_IO(int rw, struct kiocb *iocb, struct inode *inode, struct block_device *bdev, const struct iovec *iov, loff_t offset, unsigned long nr_segs, get_block_t get_block, dio_iodone_t end_io, int dio_lock_type) { int seg; size_t size; unsigned long addr; unsigned blkbits = inode->i_blkbits; unsigned bdev_blkbits = 0; unsigned blocksize_mask = (1 << blkbits) - 1; ssize_t retval = -EINVAL; loff_t end = offset; struct dio *dio; int release_i_mutex = 0; int acquire_i_mutex = 0; if (rw & WRITE) rw = WRITE_SYNC; if (bdev) bdev_blkbits = blksize_bits(bdev_hardsect_size(bdev)); if (offset & blocksize_mask) { if (bdev) blkbits = bdev_blkbits; blocksize_mask = (1 << blkbits) - 1; if (offset & blocksize_mask) goto out; } for (seg = 0; seg < nr_segs; seg++) { addr = (unsigned long)iov[seg].iov_base; size = iov[seg].iov_len; end += size; if ((addr & blocksize_mask) || (size & blocksize_mask)) { if (bdev) blkbits = bdev_blkbits; blocksize_mask = (1 << blkbits) - 1; if ((addr & blocksize_mask) || (size & blocksize_mask)) goto out; } } dio = kmalloc(sizeof(*dio), GFP_KERNEL); retval = -ENOMEM; if (!dio) goto out; dio->lock_type = dio_lock_type; if (dio_lock_type != DIO_NO_LOCKING) { if (rw == READ && end > offset) { struct address_space *mapping; mapping = iocb->ki_filp->f_mapping; if (dio_lock_type != DIO_OWN_LOCKING) { mutex_lock(&inode->i_mutex); release_i_mutex = 1; } retval = filemap_write_and_wait_range(mapping, offset, end - 1); if (retval) { kfree(dio); goto out; } if (dio_lock_type == DIO_OWN_LOCKING) { mutex_unlock(&inode->i_mutex); acquire_i_mutex = 1; } } if (dio_lock_type == DIO_LOCKING) down_read_non_owner(&inode->i_alloc_sem); } dio->is_async = !is_sync_kiocb(iocb) && !((rw & WRITE) && (end > i_size_read(inode))); retval = direct_io_worker(rw, iocb, inode, iov, offset, nr_segs, blkbits, get_block, end_io, dio); if (rw == READ && dio_lock_type == DIO_LOCKING) release_i_mutex = 0; out: if (release_i_mutex) mutex_unlock(&inode->i_mutex); else if (acquire_i_mutex) mutex_lock(&inode->i_mutex); return retval; } |
该函数将要读或者要写的数据进行拆分,并检查缓冲区对齐的情况。本文在前边介绍 open() 函数的时候指出,使用直接 I/O 读写数据的时候必须要注意缓冲区对齐的问题,从上边的代码可以看出,缓冲区对齐的检查是在 __blockdev_direct_IO() 函数里边进行的。用户地址空间的缓冲区可以通过 iov 数组中的 iovec 描述符确定。直接 I/O 的读操作或者写操作都是同步进行的,也就是说,函数 __blockdev_direct_IO() 会一直等到所有的 I/O 操作都结束才会返回,因此,一旦应用程序 read() 系统调用返回,应用程序就可以访问用户地址空间中含有相应数据的缓冲区。但是,这种方法在应用程序读操作完成之前不能关闭应用程序,这将会导致关闭应用程序缓慢。
|
1
2
3
4
5
6
|
接下来我们看一下 write() 系统调用中与直接 I/O 相关的处理实现过程。函数 write() 的原型如下所示: ssize_t write(int filedes, const void * buff, size_t nbytes) ; 操作系统中处理 write() 系统调用的入口函数是 sys_write()。其主要的调用函数关系如下所示: |
清单 8. 主调用函数关系图
|
1
2
3
4
5
6
7
8
|
sys_write() |-----vfs_write() |----generic_file_write() |----generic_file_aio_read() |---- __generic_file_write_nolock() |-- __generic_file_aio_write_nolock |-- generic_file_direct_write() |-- generic_file_direct_IO() |
函数 sys_write() 几乎与 sys_read() 执行相同的步骤,它从进程中获取文件描述符以及文件当前的操作位置后即调用 vfs_write() 函数去执行具体的操作过程,而 vfs_write() 函数最终是调用了 file 结构中的相关操作完成文件的写操作,即调用了 generic_file_write() 函数。在函数 generic_file_write() 中, 函数 generic_file_write_nolock() 最终调用 generic_file_aio_write_nolock() 函数去检查 O_DIRECT 的设置,并且调用 generic_file_direct_write() 函数去执行直接 I/O 写操作。
|
1
|
函数 generic_file_aio_write_nolock() 中与直接 I/O 相关的代码如下所示: |
清单 9. 函数 generic_file_aio_write_nolock() 中与直接 I/O 相关的代码
|
1
2
3
4
5
6
7
8
9
|
if (unlikely(file->f_flags & O_DIRECT)) { written = generic_file_direct_write(iocb, iov, &nr_segs, pos, ppos, count, ocount); if (written < 0 || written == count) goto out; pos += written; count -= written; } |
从上边代码可以看出, generic_file_aio_write_nolock() 调用了 generic_file_direct_write() 函数去执行直接 I/O 操作;而在 generic_file_direct_write() 函数中,跟读操作过程类似,它最终也是调用了 generic_file_direct_IO() 函数去执行直接 I/O 写操作。与直接 I/O 读操作不同的是,这次需要将操作类型 WRITE 作为参数传给函数 generic_file_direct_IO()。
前边介绍了 generic_file_direct_IO() 的主体 direct_IO 方法:__blockdev_direct_IO()。函数 generic_file_direct_IO() 对 WRITE 操作类型进行了一些额外的处理。当操作类型是 WRITE 的时候,若发现该使用直接 I/O 的文件已经与其他一个或者多个进程存在关联的内存映射,那么就调用 unmap_mapping_range() 函数去取消建立在该文件上的所有的内存映射,并将页缓存中相关的所有 dirty 位被置位的脏页面刷回到磁盘上去。对于直接 I/O 写操作来说,这样做可以保证写到磁盘上的数据是最新的,否则,即将用直接 I/O 方式写入到磁盘上的数据很可能会因为页缓存中已经存在的脏数据而失效。在直接 I/O 写操作完成之后,在页缓存中相关的脏数据就都已经失效了,磁盘与页缓存中的数据内容必须保持同步。
如何在字符设备中执行直接 I/O
在字符设备中执行直接 I/O 可能是有害的,只有在确定了设置缓冲 I/O 的开销非常巨大的时候才建议使用直接 I/O。在 Linux 2.6 的内核中,实现直接 I/O 的关键是函数 get_user_pages() 函数。其函数原型如下所示:
|
1
2
3
4
5
6
7
8
|
int get_user_pages(struct task_struct *tsk, struct mm_struct *mm, unsigned long start, int len, int write, int force, struct page **pages, struct vm_area_struct **vmas); |
该函数的参数含义如下所示:
- tsk:指向执行映射的进程的指针;该参数的主要用途是用来告诉操作系统内核,映射页面所产生的页错误由谁来负责,该参数几乎总是 current。
- mm:指向被映射的用户地址空间的内存管理结构的指针,该参数通常是 current->mm 。
- start: 需要映射的用户地址空间的地址。
- len:页内缓冲区的长度。
- write:如果需要对所映射的页面有写权限,该参数的设置得是非零。
- force:该参数的设置通知 get_user_pages() 函数无需考虑对指定内存页的保护,直接提供所请求的读或者写访问。
- page:输出参数。调用成功后,该参数中包含一个描述用户空间页面的 page 结构的指针列表。
- vmas:输出参数。若该参数非空,则该参数包含一个指向 vm_area_struct 结构的指针,该 vm_area_struct 结构包含了每一个所映射的页面。
在使用 get_user_pages() 函数的时候,往往还需要配合使用以下这些函数:
|
1
2
3
4
|
void down_read(struct rw_semaphore *sem); void up_read(struct rw_semaphore *sem); void SetPageDirty(struct page *page); void page_cache_release(struct page *page); |
首先,在使用 get_user_pages() 函数之前,需要先调用 down_read() 函数将 mmap 为获得用户地址空间的读取者 / 写入者信号量设置为读模式;在调用完 get_user_pages() 函数之后,再调用配对函数 up_read() 释放信号量 sem。若 get_user_pages() 调用失败,则返回错误代码;若调用成功,则返回实际被映射的页面数,该数目有可能比请求的数量少。调用成功后所映射的用户页面被锁在内存中,调用者可以通过 page 结构的指针去访问这些用户页面。
直接 I/O 的调用者必须进行善后工作,一旦直接 I/O 操作完成,用户内存页面必须从页缓存中释放。在用户内存页被释放之前,如果这些页面中的内容改变了,那么调用者必须要通知操作系统内核,否则虚拟存储子系统会认为这些页面是干净的,从而导致这些数据被修改了的页面在被释放之前无法被写回到永久存储中去。因此,如果改变了页中的数据,那么就必须使用 SetPageDirty() 函数标记出每个被改变的页。对于 Linux 2.6.18.1,该宏定义在 /include/linux/page_flags.h 中。执行该操作的代码一般需要先检查页,以确保该页不在内存映射的保留区域内,因为这个区的页是不会被交换出去的,其代码如下所示:
|
1
2
|
if (!PageReserved(page)) SetPageDirty(page); |
但是,由于用户空间所映射的页面通常不会被标记为保留,所以上述代码中的检查并不是严格要求的。
最终,在直接 I/O 操作完成之后,不管页面是否被改变,它们都必须从页缓存中释放,否则那些页面永远都会存在在那里。函数 page_cache_release() 就是用于释放这些页的。页面被释放之后,调用者就不能再次访问它们。
关于如何在字符设备驱动程序中加入对直接 I/O 的支持,Linux 2.6.18.1 源代码中 /drivers/scsi/st.c 给出了一个完整的例子。其中,函数 sgl_map_user_pages()和 sgl_map_user_pages()几乎涵盖了本节中介绍的所有内容。
直接 I/O 技术的特点
直接 I/O 的优点
直接 I/O 最主要的优点就是通过减少操作系统内核缓冲区和应用程序地址空间的数据拷贝次数,降低了对文件读取和写入时所带来的 CPU 的使用以及内存带宽的占用。这对于某些特殊的应用程序,比如自缓存应用程序来说,不失为一种好的选择。如果要传输的数据量很大,使用直接 I/O 的方式进行数据传输,而不需要操作系统内核地址空间拷贝数据操作的参与,这将会大大提高性能。
直接 I/O 潜在可能存在的问题
直接 I/O 并不一定总能提供令人满意的性能上的飞跃。设置直接 I/O 的开销非常大,而直接 I/O 又不能提供缓存 I/O 的优势。缓存 I/O 的读操作可以从高速缓冲存储器中获取数据,而直接 I/O 的读数据操作会造成磁盘的同步读,这会带来性能上的差异 , 并且导致进程需要较长的时间才能执行完;对于写数据操作来说,使用直接 I/O 需要 write() 系统调用同步执行,否则应用程序将会不知道什么时候才能够再次使用它的 I/O 缓冲区。与直接 I/O 读操作类似的是,直接 I/O 写操作也会导致应用程序关闭缓慢。所以,应用程序使用直接 I/O 进行数据传输的时候通常会和使用异步 I/O 结合使用。
总结
Linux 中的直接 I/O 访问文件方式可以减少 CPU 的使用率以及内存带宽的占用,但是直接 I/O 有时候也会对性能产生负面影响。所以在使用直接 I/O 之前一定要对应用程序有一个很清醒的认识,只有在确定了设置缓冲 I/O 的开销非常巨大的情况下,才考虑使用直接 I/O。直接 I/O 经常需要跟异步 I/O 结合起来使用,本文对异步 I/O 没有作详细介绍,有兴趣的读者可以参看 Linux 2.6 中相关的文档介绍。
相关主题
- 关于数据库管理系统使用直接 I/O 进行性能调优请参考 developerWorks 上的文章 http://www.ibm.com/developerworks/cn/data/library/techarticles/dm-0509wright/。在 Understanding the Linux Kernel(3rdEdition) 中,有关于 Linux 中直接 I/O 的介绍。
- http://lwn.net/Articles/28548/上可以找到 Linux 上零拷贝技术中关于用户地址空间访问技术的介绍。
- Linux 内核源代码中包含了直接 I/O 的具体实现,本文中引用的内核代码来自于 2.6.18.1 版本的内核。
- Linux 内核情景分析 ( 上 ) 一书的文件系统一章详细描述了 Linux 中文件系统调用。
- 在 developerWorks Linux 专区 寻找为 Linux 开发人员(包括 Linux 新手入门)准备的更多参考资料,查阅我们 最受欢迎的文章和教程。
- 在 developerWorks 上查阅所有 Linux 技巧 和 Linux 教程。
- 随时关注 developerWorks 技术活动和网络广播。
linux aio
知道异步IO已经很久了,但是直到最近,才真正用它来解决一下实际问题(在一个CPU密集型的应用中,有一些需要处理的数据可能放在磁盘上。预先知道这些数据的位置,所以预先发起异步IO读请求。等到真正需要用到这些数据的时候,再等待异步IO完成。使用了异步IO,在发起IO请求到实际使用数据这段时间内,程序还可以继续做其他事情)。
假此机会,也顺便研究了一下linux下的异步IO的实现。
linux下主要有两套异步IO,一套是由glibc实现的(以下称之为glibc版本)、一套是由linux内核实现,并由libaio来封装调用接口(以下称之为linux版本)。
glibc版本
接口
glibc版本主要包含如下接口:
int aio_read(struct aiocb *aiocbp); /* 提交一个异步读 */
int aio_write(struct aiocb *aiocbp); /* 提交一个异步写 */
int aio_cancel(int fildes, struct aiocb *aiocbp); /* 取消一个异步请求(或基于一个fd的所有异步请求,aiocbp==NULL) */
int aio_error(const struct aiocb *aiocbp); /* 查看一个异步请求的状态(进行中EINPROGRESS?还是已经结束或出错?) */
ssize_t aio_return(struct aiocb *aiocbp); /* 查看一个异步请求的返回值(跟同步读写定义的一样) */
int aio_suspend(const struct aiocb * const list[], int nent, const struct timespec *timeout); /* 阻塞等待请求完成 */
其中,struct aiocb主要包含以下字段:
int aio_fildes; /* 要被读写的fd */
void * aio_buf; /* 读写操作对应的内存buffer */
__off64_t aio_offset; /* 读写操作对应的文件偏移 */
size_t aio_nbytes; /* 需要读写的字节长度 */
int aio_reqprio; /* 请求的优先级 */
struct sigevent aio_sigevent; /* 异步事件,定义异步操作完成时的通知信号或回调函数 */
实现
glibc的aio实现是比较通俗易懂的:
1、异步请求被提交到request_queue中;
2、request_queue实际上是一个表结构,"行"是fd、"列"是具体的请求。也就是说,同一个fd的请求会被组织在一起;
3、异步请求有优先级概念,属于同一个fd的请求会按优先级排序,并且最终被按优先级顺序处理;
4、随着异步请求的提交,一些异步处理线程被动态创建。这些线程要做的事情就是从request_queue中取出请求,然后处理之;
5、为避免异步处理线程之间的竞争,同一个fd所对应的请求只由一个线程来处理;
6、异步处理线程同步地处理每一个请求,处理完成后在对应的aiocb中填充结果,然后触发可能的信号通知或回调函数(回调函数是需要创建新线程来调用的);
7、异步处理线程在完成某个fd的所有请求后,进入闲置状态;
8、异步处理线程在闲置状态时,如果request_queue中有新的fd加入,则重新投入工作,去处理这个新fd的请求(新fd和它上一次处理的fd可以不是同一个);
9、异步处理线程处于闲置状态一段时间后(没有新的请求),则会自动退出。等到再有新的请求时,再去动态创建;
看起来,换作是我们,要在用户态实现一个异步IO,似乎大概也会设计成类似的样子……
linux版本
接口
下面再来看看linux版本的异步IO。它主要包含如下系统调用接口:
int io_setup(int maxevents, io_context_t *ctxp); /* 创建一个异步IO上下文(io_context_t是一个句柄) */
int io_destroy(io_context_t ctx); /* 销毁一个异步IO上下文(如果有正在进行的异步IO,取消并等待它们完成) */
long io_submit(aio_context_t ctx_id, long nr, struct iocb **iocbpp); /* 提交异步IO请求 */
long io_cancel(aio_context_t ctx_id, struct iocb *iocb, struct io_event *result); /* 取消一个异步IO请求 */
longio_getevents(aio_context_t ctx_id, long min_nr, long nr, structio_event *events, struct timespec *timeout) /*等待并获取异步IO请求的事件(也就是异步请求的处理结果) */
其中,struct iocb主要包含以下字段:
__u16 aio_lio_opcode; /* 请求类型(如:IOCB_CMD_PREAD=读、IOCB_CMD_PWRITE=写、等) */
__u32 aio_fildes; /* 要被操作的fd */
__u64 aio_buf; /* 读写操作对应的内存buffer */
__u64 aio_nbytes; /* 需要读写的字节长度 */
__s64 aio_offset; /* 读写操作对应的文件偏移 */
__u64 aio_data; /* 请求可携带的私有数据(在io_getevents时能够从io_event结果中取得) */
__u32 aio_flags; /* 可选IOCB_FLAG_RESFD标记,表示异步请求处理完成时使用eventfd进行通知(百度一下) */
__u32 aio_resfd; /* 有IOCB_FLAG_RESFD标记时,接收通知的eventfd */
其中,struct io_event主要包含以下字段:
__u64 data; /* 对应iocb的aio_data的值 */
__u64 obj; /* 指向对应iocb的指针 */
__s64 res; /* 对应IO请求的结果(>=0: 相当于对应的同步调用的返回值;<0: -errno) */
实现
io_context_t句柄在内核中对应一个struct kioctx结构,用来给一组异步IO请求提供一个上下文。其主要包含以下字段:
struct mm_struct* mm; /* 调用者进程对应的内存管理结构(代表了调用者的虚拟地址空间) */
unsigned long user_id; /* 上下文ID,也就是io_context_t句柄的值(等于ring_info.mmap_base) */
struct hlist_node list; /* 属于同一地址空间的所有kioctx结构通过这个list串连起来,链表头是mm->ioctx_list */
wait_queue_head_t wait; /* 等待队列(io_getevents系统调用可能需要等待,调用者就在该等待队列上睡眠) */
int reqs_active; /* 进行中的请求数目 */
struct list_head active_reqs; /* 进行中的请求队列 */
unsigned max_reqs; /* 最大请求数(对应io_setup调用的int maxevents参数) */
struct list_head run_list; /* 需要aio线程处理的请求列表(某些情况下,IO请求可能交给aio线程来提交) */
struct delayed_work wq; /* 延迟任务队列(当需要aio线程处理请求时,将wq挂入aio线程对应的请求队列) */
struct aio_ring_info ring_info; /* 存放请求结果io_event结构的ring buffer */
其中,这个aio_ring_info结构比较值得一提,它是用于存放请求结果io_event结构的ring buffer。它主要包含了如下字段:
unsigned long mmap_base; /* ring buffer的地始地址 */
unsigned long mmap_size; /* ring buffer分配空间的大小 */
struct page** ring_pages; /* ring buffer对应的page数组 */
long nr_pages; /* 分配空间对应的页面数目(nr_pages * PAGE_SIZE = mmap_size) */
unsigned nr, tail; /* 包含io_event的数目及存取游标 */
这个数据结构看起来有些奇怪,直接弄一个io_event数组不就完事了么?为什么要维护mmap_base、mmap_size、ring_pages、nr_pages这么复杂的一组信息,而又把io_event结构隐藏起来呢?
这里的奇妙之处就在于,io_event结构的buffer是在用户态地址空间上分配的。注意,我们在内核里面看到了诸多数据结构都是在内核地址空间上分配的,因为这些结构都是内核专有的,没必要给用户程序看到,更不能让用户程序去修改。而这里的io_event却是有意让用户程序看到,而且用户就算修改了也不会对内核的正确性造成影响。于是这里使用了这样一个有些取巧的办法,由内核在用户态地址空间上分配buffer。(如果换一个保守点的做法,内核态可以维护io_event的buffer,然后io_getevents的时候,将对应的io_event复制一份到用户空间。)
按照这样的思路,io_setup时,内核会通过mmap在对应的用户空间分配一段内存,mmap_base、mmap_size就是这个内存映射对应的位置和大小。然后,光有映射还不行,还必须立马分配物理内存,ring_pages、nr_pages就是分配好的物理页面。(因为这些内存是要被内核直接访问的,内核会将异步IO的结果写入其中。如果物理页面延迟分配,那么内核访问这些内存的时候会发生缺页异常。而处理内核态的缺页异常又很麻烦,所以还不如直接分配物理内存的好。其二,内核在访问这个buffer里的信息时,也并不是通过mmap_base这个虚拟地址去直接访问的。既然是异步,那么结果写回的时候可能是在另一个上下文上面,虚拟地址空间都不同。为了避免进行虚拟地址空间的切换,内核干脆直接通过kmap将ring_pages映射到高端内存上去访问好了。)
然后,在mmap_base指向的用户空间的地址上,会存放着一个struct aio_ring结构,用来管理这个ring buffer。其主要包含了如下字段:
unsigned id; /* 等于aio_ring_info中的user_id */
unsigned nr; /* 等于aio_ring_info中的nr */
unsigned head,tail; /* io_events数组的游标 */
unsigned magic,compat_features,incompat_features;
unsigned header_length; /* aio_ring结构的大小 */
struct io_event io_events[0]; /* io_event的buffer */
终于,我们期待的io_event数组出现了。
看到这里,如果前面的内容你已经理解清楚了,你一定会有个疑问:既然整个aio_ring结构及其中的io_event缓冲都是放在用户空间的,内核还提供io_getevents系统调用干什么?用户程序不是直接就可以取用io_event,并且修改游标了么(内核作为生产者,修改aio_ring->tail;用户作为消费者,修改aio_ring->head)?我想,aio_ring之所以要放在用户空间,其原本用意应该就是这样的。
那么,用户空间如何知道aio_ring结构的地址(aio_ring_info->mmap_base)呢?其实kioctx结构中的user_id,也就是io_setup返回给用户的io_context_t,就等于aio_ring_info->mmap_base。
然后,aio_ring结构中还有诸如magic、compat_features、incompat_features这样的字段,用户空间可以读这些magic,以确定数据结构没有被异常篡改。如果一切可控,那么就自己动手、丰衣足食;否则就还是走io_getevents系统调用。而io_getevents系统调用通过aio_ring_info->ring_pages得到aio_ring结构,再将相应的io_event拷贝到用户空间。
下面贴一段libaio中的io_getevents的代码(前面提到过,linux版本的异步IO是由用户态的libaio来封装的):
int io_getevents_0_4(io_context_t ctx, long min_nr, long nr, struct io_event * events, struct timespec * timeout){
struct aio_ring *ring;
ring = (struct aio_ring*)ctx;
if (ring==NULL || ring->magic != AIO_RING_MAGIC)
goto do_syscall;
if (timeout!=NULL && timeout->tv_sec == 0 && timeout->tv_nsec == 0) {
if (ring->head == ring->tail)
return 0;
}
do_syscall:
return __io_getevents_0_4(ctx, min_nr, nr, events, timeout);
}
其中确实用到了用户空间上的aio_ring结构的信息,不过尺度还是不够大。
以上就是异步IO的context的结构。那么,为什么linux版本的异步IO需要“上下文”这么个概念,而glibc版本则不需要呢?
在glibc版本中,异步处理线程是glibc在调用者进程中动态创建的线程,它和调用者必定是在同一个虚拟地址空间中的。这里已经隐含了“同一上下文”这么个关系。
而对于内核来说,要面对的是任意的进程,任意的虚拟地址空间。当处理一个异步请求时,内核需要在调用者对应的地址空间中存取数据,必须知道这个虚拟地址空间是什么。不过当然,如果设计上要想把“上下文”这个概念隐藏了也是肯定可以的(比如让每个mm隐含一个异步IO上下文)。具体如何选择,只是设计上的问题。
struct iocb在内核中又对应到struct kiocb结构,主要包含以下字段:
struct kioctx* ki_ctx; /* 请求对应的kioctx(上下文结构) */
struct list_head ki_run_list; /* 需要aio线程处理的请求,通过该字段链入ki_ctx->run_list */
struct list_head ki_list; /* 链入ki_ctx->active_reqs */
struct file* ki_filp; /* 对应的文件指针 */
void __user* ki_obj.user; /* 指向用户态的iocb结构 */
__u64 ki_user_data; /* 等于iocb->aio_data */
loff_t ki_pos; /* 等于iocb->aio_offset */
unsigned short ki_opcode; /* 等于iocb->aio_lio_opcode */
size_t ki_nbytes; /* 等于iocb->aio_nbytes */
char __user * ki_buf; /* 等于iocb->aio_buf */
size_t ki_left; /* 该请求剩余字节数(初值等于iocb->aio_nbytes) */
struct eventfd_ctx* ki_eventfd; /* 由iocb->aio_resfd对应的eventfd对象 */
ssize_t (*ki_retry)(struct kiocb *); /*由ki_opcode选择的请求提交函数*/
调用io_submit后,对应于用户传递的每一个iocb结构,会在内核态生成一个与之对应的kiocb结构,并且在对应kioctx结构的ring_info中预留一个io_events的空间。之后,请求的处理结果就被写到这个io_event中。
然后,对应的异步读写(或其他)请求就被提交到了虚拟文件系统,实际上就是调用了file->f_op->aio_read或file->f_op->aio_write(或其他)。也就是,在经历磁盘高速缓存层、通用块层之后,请求被提交到IO调度层,等待被处理。这个跟普通的文件读写请求是类似的。
在《linux文件读写浅析》中可以看到,对于非direct-io的读请求来说,如果pagecache不命中,那么IO请求会被提交到底层。之后,do_generic_file_read会通过lock_page操作,等待数据最终读完。这一点跟异步IO是背道而驰的,因为异步就意味着请求提交后不能等待,必须马上返回。而对于非direct-io的写请求,写操作一般仅仅是将数据更新作用到page cache上,并不需要真正的写磁盘。pagecache写回磁盘本身是一个异步的过程。可见,对于非direct-io的文件读写,使用linux版本的异步IO接口完全没有意义(就跟使用同步接口效果一样)。
为什么会有这样的设计呢?因为非direct-io的文件读写是只跟page cache打交道的。而pagecache是内存,跟内存打交道又不会存在阻塞,那么也就没有什么异步的概念了。至于读写磁盘时发生的阻塞,那是pagecache跟磁盘打交道时发生的事情,跟应用程序又没有直接关系。
然而,对于direct-io来说,异步则是有意义的。因为direct-io是应用程序的buffer跟磁盘的直接交互(不使用page cache)。
这里,在使用direct-io的情况下,file->f_op->aio_{read,write}提交完IO请求就直接返回了,然后io_submit系统调用返回。(见后面的执行流程。)
通过linux内核异步触发的IO调度(如:被时钟中断触发、被其他的IO请求触发、等),已经提交的IO请求被调度,由对应的设备驱动程序提交给具体的设备。对于磁盘,一般来说,驱动程序会发起一次DMA。然后又经过若干时间,读写请求被磁盘处理完成,CPU将收到表示DMA完成的中断信号,设备驱动程序注册的处理函数将在中断上下文中被调用。这个处理函数会调用end_request函数来结束这次请求。这个流程跟《linux文件读写浅析》中所说的非direct-io读操作的情况是一样的。
不同的是,对于同步非direct-io,end_request将通过清除page结构的PG_locked标记来唤醒被阻塞的读操作流程,异步IO和同步IO效果一样。而对于direct-io,除了唤醒被阻塞的读操作流程(同步IO)或io_getevents流程(异步IO)之外,还需要将IO请求的处理结果填回对应的io_event中。
最后,等到调用者调用io_getevents的时候,就能获取到请求对应的结果(io_event)。而如果调用io_getevents的时候结果还没出来,流程也会被阻塞,并且会在direct-io的end_request过程中得到唤醒。
linux版本的异步IO也有aio线程(每CPU一个),但是跟glibc版本中的异步处理线程不同,这里的aio线程是用来处理请求重试的。某些情况下,file->f_op->aio_{read,write}可能会返回-EIOCBRETRY,表示需要重试(只有一些特殊的IO设备会这样)。而调用者既然使用的是异步IO接口,肯定不希望里面会有等待/重试的逻辑。所以,如果遇到-EIOCBRETRY,内核就在当前CPU对应的aio线程添加一个任务,让aio线程来完成请求的重新提交。而调用流程可以直接返回,不需要阻塞。
请求在aio线程中提交和在调用者进程中提交相比,有一个最大的不同,就是aio线程使用的地址空间可能跟调用者线程不一样。需要利用kioctx->mm切换到正确的地址空间,然后才能发请求。(参见《浅尝异步IO》中的讨论。)
内核处理流程
最后,整理一下direct-io异步读操作的处理流程:
io_submit。对于提交的iocbpp数组中的每一个iocb(异步请求),调用io_submit_one来提交它们;
io_submit_one。为请求分配一个kiocb结构,并且在对应的kioctx的ring_info中为它预留一个对应的io_event。然后调用aio_rw_vect_retry来提交这个读请求;
aio_rw_vect_retry。调用file->f_op->aio_read。这个函数通常是由generic_file_aio_read或者其封装来实现的;
generic_file_aio_read。对于非direct-io,会调用do_generic_file_read来处理请求(见《linux文件读写浅析》)。而对于direct-io,则是调用mapping->a_ops->direct_IO。这个函数通常就是blkdev_direct_IO;
blkdev_direct_IO。调用filemap_write_and_wait_range将相应位置可能存在的page cache废弃掉或刷回磁盘(避免产生不一致),然后调用direct_io_worker来处理请求;
direct_io_worker。一次读可能包含多个读操作(对应于类readv系统调用),对于其中的每一个,调用do_direct_IO;
do_direct_IO。调用submit_page_section;
submit_page_section。调用dio_new_bio分配对应的bio结构,然后调用dio_bio_submit来提交bio;
dio_bio_submit。调用submit_bio提交请求。后面的流程就跟非direct-io是一样的了,然后等到请求完成,驱动程序将调用bio->bi_end_io来结束这次请求。对于direct-io下的异步IO,bio->bi_end_io等于dio_bio_end_aio;
dio_bio_end_aio。调用wake_up_process唤醒被阻塞的进程(异步IO下,主要是io_getevents的调用者)。然后调用aio_complete;
aio_complete。将处理结果写回到对应的io_event中;
比较
从上面的流程可以看出,linux版本的异步IO实际上只是利用了CPU和IO设备可以异步工作的特性(IO请求提交的过程主要还是在调用者线程上同步完成的,请求提交后由于CPU与IO设备可以并行工作,所以调用流程可以返回,调用者可以继续做其他事情)。相比同步IO,并不会占用额外的CPU资源。
而glibc版本的异步IO则是利用了线程与线程之间可以异步工作的特性,使用了新的线程来完成IO请求,这种做法会额外占用CPU资源(对线程的创建、销毁、调度都存在CPU开销,并且调用者线程和异步处理线程之间还存在线程间通信的开销)。不过,IO请求提交的过程都由异步处理线程来完成了(而linux版本是调用者来完成的请求提交),调用者线程可以更快地响应其他事情。如果CPU资源很富足,这种实现倒也还不错。
还有一点,当调用者连续调用异步IO接口,提交多个异步IO请求时。在glibc版本的异步IO中,同一个fd的读写请求由同一个异步处理线程来完成。而异步处理线程又是同步地、一个一个地去处理这些请求。所以,对于底层的IO调度器来说,它一次只能看到一个请求。处理完这个请求,异步处理线程才会提交下一个。而内核实现的异步IO,则是直接将所有请求都提交给了IO调度器,IO调度器能看到所有的请求。请求多了,IO调度器使用的类电梯算法就能发挥更大的功效。请求少了,极端情况下(比如系统中的IO请求都集中在同一个fd上,并且不使用预读),IO调度器总是只能看到一个请求,那么电梯算法将退化成先来先服务算法,可能会极大的增加碰头移动的开销。
最后,glibc版本的异步IO支持非direct-io,可以利用内核提供的page cache来提高效率。而linux版本只支持direct-io,cache的工作就只能靠用户程序来实现了。
Linux aio是Linux下的异步读写模型。
对于文件的读写,即使以O_NONBLOCK方式来打开一个文件,也会处于"阻塞"状态。因为文件时时刻刻处于可读状态。而从磁盘到内存所等待的时间是惊人的。为了充份发挥把数据从磁盘复制到内存的时间,引入了aio模型。linux下有aio封装,但是aio采用的是线程或信号用以通知,为了能更多的控制io行为,可以使用更为低级libaio。
一、基本函数与结构
1. libaio函数
extern int io_setup(int maxevents, io_context_t *ctxp); extern int io_destroy(io_context_t ctx); extern int io_submit(io_context_t ctx, long nr, struct iocb *ios[]); extern int io_cancel(io_context_t ctx, struct iocb *iocb, struct io_event *evt); extern int io_getevents(io_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);
2. 结构
struct io_iocb_poll {
PADDED(int events, __pad1);
}; /* result code is the set of result flags or -'ve errno */
struct io_iocb_sockaddr {
struct sockaddr *addr;
int len;
}; /* result code is the length of the sockaddr, or -'ve errno */
struct io_iocb_common {
PADDEDptr(void *buf, __pad1);
PADDEDul(nbytes, __pad2);
long long offset;
long long __pad3;
unsigned flags;
unsigned resfd;
}; /* result code is the amount read or -'ve errno */
struct io_iocb_vector {
const struct iovec *vec;
int nr;
long long offset;
}; /* result code is the amount read or -'ve errno */
struct iocb {
PADDEDptr(void *data, __pad1); /* Return in the io completion event */
PADDED(unsigned key, __pad2); /* For use in identifying io requests */
short aio_lio_opcode;
short aio_reqprio;
int aio_fildes;
union {
struct io_iocb_common c;
struct io_iocb_vector v;
struct io_iocb_poll poll;
struct io_iocb_sockaddr saddr;
} u;
};
struct io_event {
PADDEDptr(void *data, __pad1);
PADDEDptr(struct iocb *obj, __pad2);
PADDEDul(res, __pad3);
PADDEDul(res2, __pad4);
};
3. 内联函数
static inline void io_set_callback(struct iocb *iocb, io_callback_t cb); static inline void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count, long long offset); static inline void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count, long long offset); static inline void io_prep_preadv(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset); static inline void io_prep_pwritev(struct iocb *iocb, int fd, const struct iovec *iov, int iovcnt, long long offset); /* Jeff Moyer says this was implemented in Red Hat AS2.1 and RHEL3. * AFAICT, it was never in mainline, and should not be used. --RR */ static inline void io_prep_poll(struct iocb *iocb, int fd, int events); static inline int io_poll(io_context_t ctx, struct iocb *iocb, io_callback_t cb, int fd, int events); static inline void io_prep_fsync(struct iocb *iocb, int fd); static inline int io_fsync(io_context_t ctx, struct iocb *iocb, io_callback_t cb, int fd); static inline void io_prep_fdsync(struct iocb *iocb, int fd); static inline int io_fdsync(io_context_t ctx, struct iocb *iocb, io_callback_t cb, int fd); static inline void io_set_eventfd(struct iocb *iocb, int eventfd);
二、使用方法
1、初使化io_context
2、open文件取得fd
3、根据fd,buffer offset等息建立iocb
4、submit iocb到context
5、io_getevents取得events状态
6、回到3步
三、例子
- #include <unistd.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #include <error.h>
- #include <errno.h>
- #include <fcntl.h>
- #include <libaio.h>
- int main(int argc, char *argv[])
- {
- // 每次读入32K字节
- const int buffer_size = 0x8000;
- // 最大事件数 32
- const int nr_events = 32;
- int rt;
- io_context_t ctx = {0};
- // 初使化 io_context_t
- rt = io_setup(nr_events, &ctx);
- if ( rt != 0 )
- error(1, rt, "io_setup");
- // 依次读取参数作为文件名加入提交到ctx
- int pagesize = sysconf(_SC_PAGESIZE);
- for (int i=1; i<argc; ++i) {
- iocb *cb = (iocb*)malloc(sizeof(iocb));
- void *buffer;
- // 要使用O_DIRECT, 必须要对齐
- posix_memalign(&buffer, pagesize, buffer_size);
- io_prep_pread(cb, open(argv[i], O_RDONLY | O_DIRECT), buffer, buffer_size, 0);
- rt = io_submit(ctx, 1, &cb);
- if (rt < 0)
- error(1, -rt, "io_submit %s", argv[i]);;
- }
- io_event events[nr_events];
- iocb *cbs[nr_events];
- int remain = argc - 1;
- int n = 0;
- // 接收数据最小返回的请求数为1,最大为nr_events
- while (remain && (n = io_getevents(ctx, 1, nr_events, events, 0))) {
- int nr_cbs = 0;
- for (int i=0; i<n; ++i) {
- io_event &event = events[i];
- iocb *cb = event.obj;
- // event.res为unsigned
- //printf("%d receive %d bytes ", cb->aio_fildes, event.res);
- if (event.res > buffer_size) {
- printf("%s ", strerror(-event.res));
- }
- if (event.res != buffer_size || event.res2 != 0) {
- --remain;
- // 释放buffer, fd 与 cb
- free(cb->u.c.buf);
- close(cb->aio_fildes);
- free(cb);
- } else {
- // 更新cb的offset
- cb->u.c.offset += event.res;
- cbs[nr_cbs++] = cb;
- }
- }
- if (nr_cbs) {
- // 继续接收数据
- io_submit(ctx, nr_cbs, cbs);
- }
- }
- return 0;
- }
- #include <unistd.h>
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #include <error.h>
- #include <errno.h>
- #include <fcntl.h>
- #include <libaio.h>
- int main(int argc, char *argv[])
- {
- // 每次读入32K字节
- const int buffer_size = 0x8000;
- // 最大事件数 32
- const int nr_events = 32;
- int rt;
- io_context_t ctx = {0};
- // 初使化 io_context_t
- rt = io_setup(nr_events, &ctx);
- if ( rt != 0 )
- error(1, rt, "io_setup");
- // 依次读取参数作为文件名加入提交到ctx
- int pagesize = sysconf(_SC_PAGESIZE);
- for (int i=1; i<argc; ++i) {
- iocb *cb = (iocb*)malloc(sizeof(iocb));
- void *buffer;
- // 要使用O_DIRECT, 必须要对齐
- posix_memalign(&buffer, pagesize, buffer_size);
- io_prep_pread(cb, open(argv[i], O_RDONLY | O_DIRECT), buffer, buffer_size, 0);
- rt = io_submit(ctx, 1, &cb);
- if (rt < 0)
- error(1, -rt, "io_submit %s", argv[i]);;
- }
- io_event events[nr_events];
- iocb *cbs[nr_events];
- int remain = argc - 1;
- int n = 0;
- // 接收数据最小返回的请求数为1,最大为nr_events
- while (remain && (n = io_getevents(ctx, 1, nr_events, events, 0))) {
- int nr_cbs = 0;
- for (int i=0; i<n; ++i) {
- io_event &event = events[i];
- iocb *cb = event.obj;
- // event.res为unsigned
- //printf("%d receive %d bytes ", cb->aio_fildes, event.res);
- if (event.res > buffer_size) {
- printf("%s ", strerror(-event.res));
- }
- if (event.res != buffer_size || event.res2 != 0) {
- --remain;
- // 释放buffer, fd 与 cb
- free(cb->u.c.buf);
- close(cb->aio_fildes);
- free(cb);
- } else {
- // 更新cb的offset
- cb->u.c.offset += event.res;
- cbs[nr_cbs++] = cb;
- }
- }
- if (nr_cbs) {
- // 继续接收数据
- io_submit(ctx, nr_cbs, cbs);
- }
- }
- return 0;
- }
运行
$ truncate foo.txt -s 100K $ truncate foo2.txt -s 200K $ g++ -O3 libaio_simple.cc -laio && ./a.out foo.txt foo2.txt 3 received 32768 bytes 4 received 32768 bytes 3 received 32768 bytes 4 received 32768 bytes 3 received 32768 bytes 4 received 32768 bytes 3 received 4096 bytes 3 done. 4 received 32768 bytes 4 received 32768 bytes 4 received 32768 bytes 4 received 8192 bytes 4 done.
四、其它
这里有个问题,因为O_DIRECT跳过系统缓存,直接从磁盘读取,对于读写来讲是个大问题。要自已实现缓存,需要一堆东西要啃,而且还不一定写得好。