一、requests库的get()函数访问必应主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。
1>返回状态。
常见的几个状态码:
- 200 – 服务器成功返回网页
- 404 – 请求的网页不存在
- 301 – 资源(网页等)被永久转移到其它URL
- 500 – 服务器内部错误
代码如下:
import requests from bs4 import BeautifulSoup def JudgeState(r): x = r.status_code print("获得响应的状态码:", x , end="") if x == 200 : print("------请求成功") if x == 301: print("----资源(网页等)被永久转移到其它URL") if x == 404: print("----请求的资源(网页等)不存在") if x == 500: print("------内部服务器错误") return '' r = requests.get("https://cn.bing.com/",timeout = 30) for i in range(1,21): #访问必应网站20次,查看连接状态 print("第{}次".format(i)) JudgeState(r)
1.1运行结果:

2>text()内容·【网页html代码】
使用如下函数即可获得text内容:
def GetHTMLText(url): try : r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = "utf-8" return r.text except: return ""
完整代码:
import requests from bs4 import BeautifulSoup def GetHTMLText(url): try : r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = "utf-8" return r.text except: return "" url = "https://cn.bing.com/" r = GetHTMLText(url) print(r)
1.2部分运行结果:
3>计算text()属性和contents()属性所返回网页内容的长度
代码如下:
import requests from bs4 import BeautifulSoup url = "https://cn.bing.com/" r = requests.get(url,timeout = 30) r.encoding = "utf-8" print("text属性返回的网页内容长度:{}".format(len(r.text))) print("content属性返回的网页内容长度:{}".format(len(r.content)))
1.3运行结果:

二、完成对简单的html页面的相关计算要求。
【html页面如下】要求获取其中的head、body,id为first的标签内容。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id=first>我的第一个段落。</p > </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
相关操作如下:(ps:根据作业要求,小编先将该html代码储存到电脑上,用打开文件方式打开该html)
import requests from bs4 import BeautifulSoup f = open("D:\桌面\pytest\test.html",'r',encoding="utf-8") r = f.read() f.close() soup = BeautifulSoup(r,"html.parser") print("(1)head标签: ",soup.head) print("(2)body标签内容: ",soup.title) print("(3)id为first的标签对象: ",soup.find(id='first')) print("(4)获取该html中的中文字符:",soup.title.string,soup.find('h1').string, soup.find(id='first').string)
运行结果如下:

在解决(4)时,小编使用的是提取标签内容的方法,显然结果存在错误。百度查找,得到以下解决方法:
import requests from bs4 import BeautifulSoup f = open("D:\桌面\pytest\test.html",'r',encoding="utf-8") r = f.read() f.close() soup = BeautifulSoup(r,"html.parser") import re #使用正则匹配来获取html字符串的中文字符,依据汉字的Unicode码表: 从u4e00~u9fa5, 即代表了符合汉字GB18030规范的字符集 pattern = re.compile(r'[u4e00-u9fa5]+') result = pattern.findall(r) print("中文字符:",result)
结果如下:
![]()
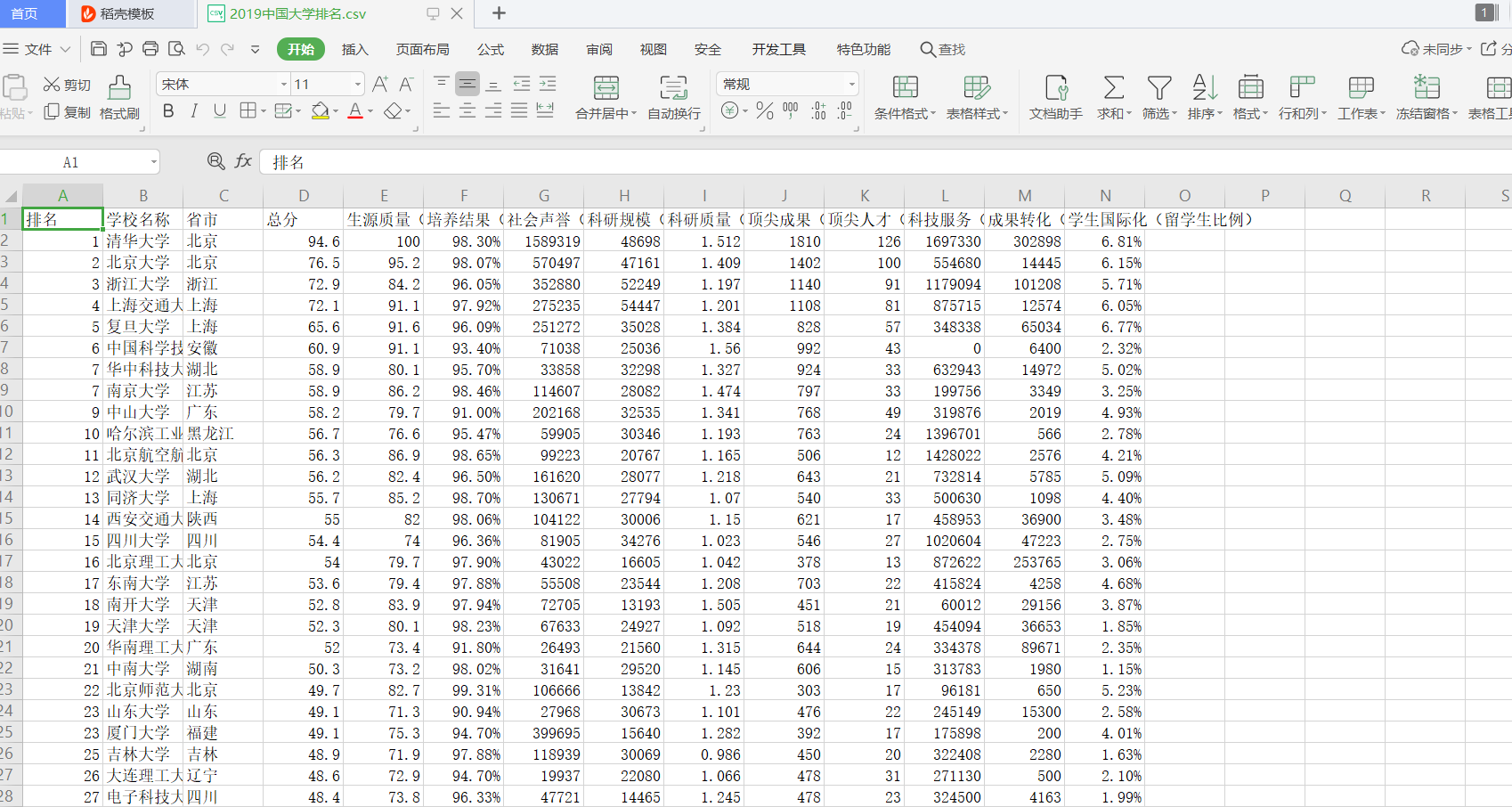
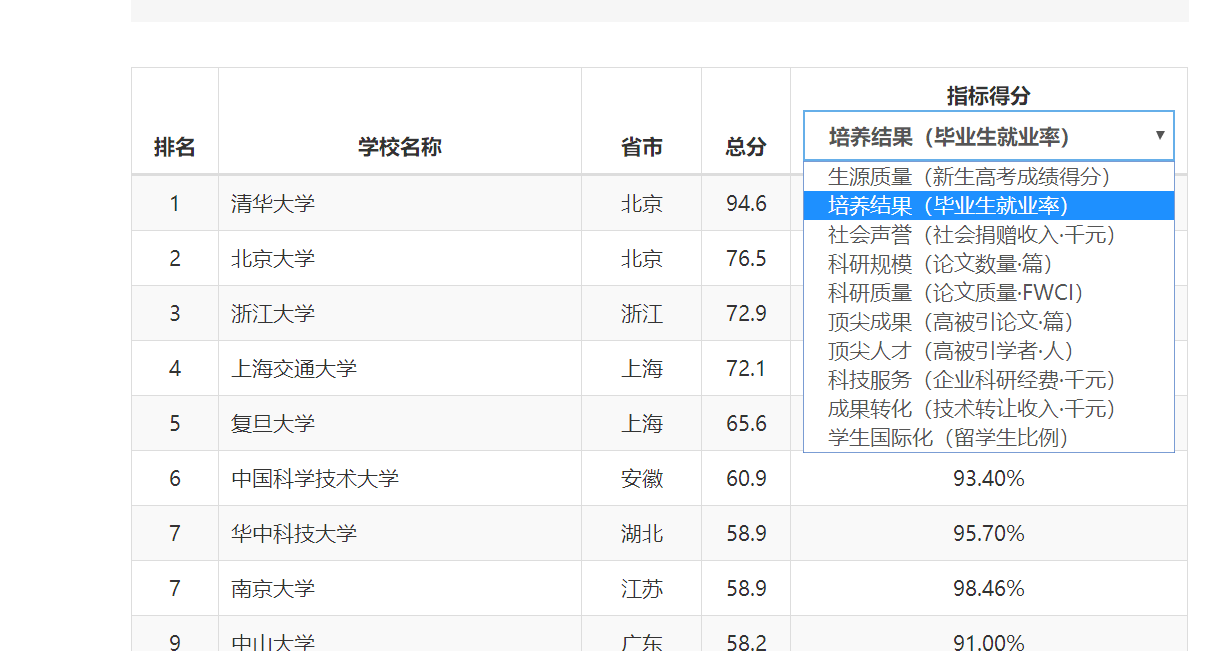
三、爬中国大学排名网站内容,并存为csv。
要求获取如下图的数据:
具体代码如下:
# 中国大学排名.py import requests from bs4 import BeautifulSoup def GetHTMLText(url): try : r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = "utf-8" return r.text except: return "" def FindUnivList(soup): data = soup.find_all('tr') lth = data[0].find_all('th') #通过查看网页html代码,找到第一个'tr'标签下的'th'标签就是表格标题。 thead = [] for th in lth[:4]: #前四个表格标题(第五个特殊,下面处理) thead.append(th.string) tOptions = data[0].find_all('option') #处理第五个特殊的表格标题 for tOption in tOptions: thead.append(tOption.string) allUniv.append(thead) for tr in data: #获取数据内容 ltd = tr.find_all('td') if len(ltd) == 0: continue tbodies = [] for td in ltd: if td.string is None: #对无数据内容处理 tbodies.append('') continue tbodies.append(td.string) allUniv.append(tbodies) def main(): url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html" html = GetHTMLText(url) soup = BeautifulSoup(html,"html.parser") FindUnivList(soup) #储存为csv f = open('2019中国大学排名.csv','w',encoding='utf-8') for row in allUniv: f.write(','.join(row)+' ') f.close() allUniv = [] main()
关于在获取数据时,对于无数据内容的处理:
例如,某所大学的得分指标没有(不存在),这时如果不进行处理就会出现如下错误
TypeError: sequence item 5: expected str instance, NoneType found
具体解决方法见上述代码。
结果如下:(只显示部分)