import matplotlib.pyplot as plt import pandas as pd import numpy as np from pandas import Series, DataFrame # 线形图 s = Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10)).plot() df = DataFrame(np.random.randn(10,4).cumsum(0),columns=['A','B','C','D'],index=np.arange(0,100,10)).plot()
# 柱状图 fig,axes = plt.subplots(2,1) data = Series(np.random.randn(16),index=list('abcdefghijklmnop')) data.plot(kind='bar',ax=axes[0],color='g',alpha=0.7) data.plot(kind='barh',ax=axes[1],color='b',alpha=0.7) # rand [0, 1) df = DataFrame(np.random.rand(6,4), index=['one','two','three','four','five','six'], columns=pd.Index(['A','B','C','D'],name='name')) df.plot(kind='barh',alpha=0.5) df.plot(kind='barh',stacked=True,alpha=0.5) # stacked=True 每行值堆积在一起
# 直方图和密度图 comp1 = np.random.normal(0,1,size=200) comp2 = np.random.normal(10,2,size=200) values = Series(np.concatenate([comp1,comp2])) #values.hist(bins=100,alpha=0.3,color='g',density=True) values.hist(bins=100,alpha=0.3,color='g',density=True,stacked=True) values.plot(kind='kde',style='k--',alpha=0.3)
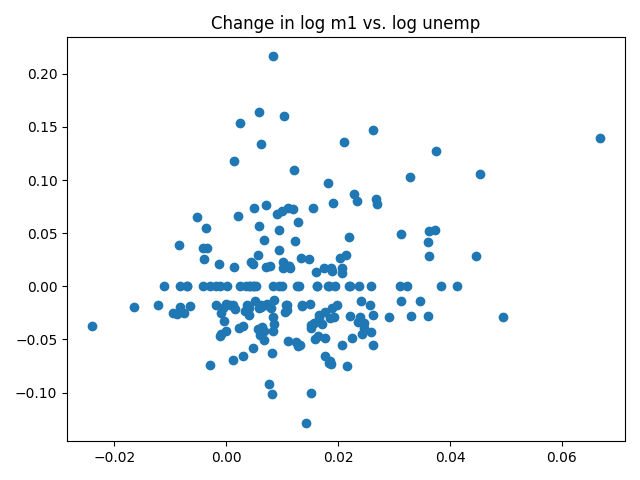
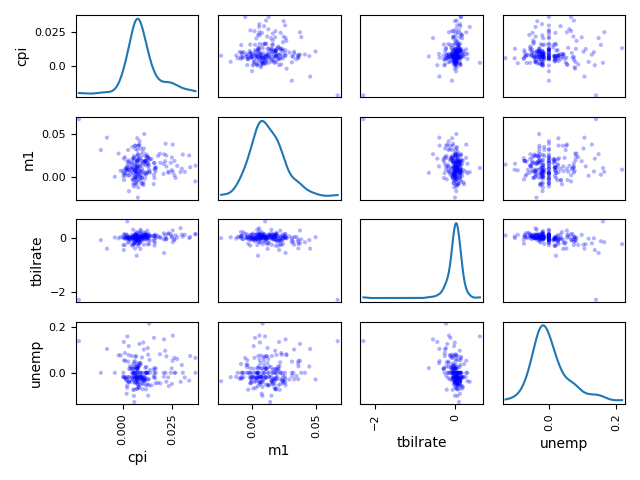
# 散布图 macro = pd.read_csv('macrodata.csv') data = macro[['cpi','m1','tbilrate','unemp']] trans_data = np.log(data).diff().dropna() plt.scatter(trans_data['m1'],trans_data['unemp']) plt.title('Change in log %s vs. log %s' %('m1','unemp')) pd.plotting.scatter_matrix(trans_data,diagonal='kde',color='b',alpha=0.3)