G1: Garbage First 低延迟、服务侧分代垃圾回收器。
详细介绍参见:JVM之G1收集器,这里不再赘述。
关于调优目标:延迟、吞吐量
一、延迟,单次的延迟
单次的延迟关系到服务的响应时延,比如,在要求接口响应不超过100ms的服务里,单次的延迟目标必然不能超过100ms。
服务的响应时间目标,不应该是指100%时间的服务响应。服务不可能是100%可用的,通常,我们对于服务的响应延迟目标也不是100%可用时间内的。
实际应用中,我们可能会以99.9%时间内,延迟不超过100ms为目标。
对于G1,会有一些默认设置,以使应用者在不做任何调整的情况下,依然能高效的运行。
-XX:MaxGCPauseMillis=200:目标最大gc暂停时间,默认为200ms,这只是期望的目标延迟。我们知道G1有相应的收集算法,会根据收集的信息及检测的垃圾量动态的调整年轻代与老年代的大小以尽力达到这个目标。
使用此配置需要注意的一点是,不要和 Xmn 年轻代同时设置,我们上面提到过,G1会为了最大gc暂停时间目标而动态的调整年轻代大小,因此,如果设定了 Xmn,那么固定了年轻代的大小就会影响G1的智能调整适应。
二、吞吐量,有多少总的延迟
总的延迟关系到服务的可用时间率、吞吐量,比如,100分钟内总的gc延迟1分钟,那么服务的可用率就是99%。如果既定的目标是99.9%,那么总的延迟就不能超过6秒钟。
总的延迟=单次延迟*gc次数。
单次延迟我们在一.1中已经论述,那么现在就需要通过降低gc次数来达到降低总延迟的目标,
gc触发于应用内存占用达到一定比例阈值,因此想要降低gc频次,那么就需要适当调大应用可使用堆大小:Xmx。
应用到底需要使用多大的应用内存,这个需要根据实际的需求确定,可以通过压测,不断的微调来找到最适合的Xmx设置,过大或者过小都会影响服务的服务能力。
三、gc日志
配置输出gc日志:-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps。
下面是一段实际应用中的yong GC日志:
1 [GC pause (G1 Evacuation Pause) (young), 0.1006389 secs] 2 [Parallel Time: 45.6 ms, GC Workers: 38] 3 [GC Worker Start (ms): Min: 4053175.2, Avg: 4053184.8, Max: 4053215.7, Diff: 40.5] 4 [Ext Root Scanning (ms): Min: 0.0, Avg: 1.2, Max: 8.6, Diff: 8.6, Sum: 47.1] 5 [Update RS (ms): Min: 0.0, Avg: 8.4, Max: 41.3, Diff: 41.3, Sum: 317.3] 6 [Processed Buffers: Min: 0, Avg: 13.3, Max: 39, Diff: 39, Sum: 505] 7 [Scan RS (ms): Min: 0.0, Avg: 0.2, Max: 0.4, Diff: 0.4, Sum: 7.7] 8 [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.3] 9 [Object Copy (ms): Min: 0.0, Avg: 20.6, Max: 32.6, Diff: 32.5, Sum: 783.9] 10 [Termination (ms): Min: 0.0, Avg: 4.5, Max: 5.2, Diff: 5.2, Sum: 171.5] 11 [GC Worker Other (ms): Min: 0.0, Avg: 0.2, Max: 0.6, Diff: 0.6, Sum: 5.9] 12 [GC Worker Total (ms): Min: 4.1, Avg: 35.1, Max: 44.6, Diff: 40.5, Sum: 1333.8] 13 [GC Worker End (ms): Min: 4053219.7, Avg: 4053219.9, Max: 4053220.4, Diff: 0.8] 14 [Code Root Fixup: 0.3 ms] 15 [Code Root Purge: 0.0 ms] 16 [Clear CT: 1.5 ms] 17 [Other: 53.2 ms] 18 [Choose CSet: 0.0 ms] 19 [Ref Proc: 39.2 ms] 20 [Ref Enq: 8.6 ms] 21 [Redirty Cards: 1.3 ms] 22 [Humongous Reclaim: 0.0 ms] 23 [Free CSet: 2.0 ms] 24 [Eden: 4708.0M(4708.0M)->0.0B(4724.0M) Survivors: 204.0M->188.0M Heap: 5528.0M(8192.0M)->804.9M(8192.0M)] 25 [Times: user=1.37 sys=0.02, real=0.10 secs]
第一行:指明GC类型,一次GC的总耗时 0.1006389 secs,即100ms。
第二行:并行阶段STW时间汇,GC工作线程数(配置:-XX:ParallelGCThreads。CPU数量小于8时,值取CPU个数,最大为8,CPU数量大于8时,值取(CPU个数*5/8))。
第三行:GC线程开始工作时间,Min最小值、Avg平均值、Max最大值、Diff偏移平均的值(Max-Min)
第四行:外部根区扫描,包括堆外区、JNI引用、JVM系统目录、Classloaders等。Sum总耗时。
第五行:RSets(Remembered Sets )时间信息更新,G1依据-XX:MaxGCPauseMillis参数来设定目标暂停时间,RSet更新的时间耗时应小于目标暂停时间的10%。可以通过修改配置 XX:G1RSetUpdatingPauseTimePercent 设预期定耗时占用比。
第六行:已处理缓冲区:即在优化线程中处理dirty card分区扫描时记录的日志缓冲区。
第七行:RSets扫描。
第八行:代码Root扫描,经过JIT编译后的代码里引用了heap中的对象,引用关系保存在RSet中。
第九行:拷贝存活对象到新的Region耗时。
第十行:GC线程完成任务之后尝试结束到真正结束的耗时。GC线程结束前会检查其它线程是否有未完成的任务,如果有则会协助完成之后再结束。
第十一行:线程花费在其他工作上的时间,
第十二行:并行阶段的GC时间总和,包含GC以及GC Worker Other时间(47.1+317.3+7.7+0.3+783.9+171.5+5.9)。
第十三行:GC线程结束时间,Min最小值、Avg平均值、Max最大值、Diff偏移平均的值(Max-Min)
第十四行:修复GC期间code root指针改变的耗时。
第十五行:清除code root耗时,root中已经失效,不再指向Region中对象的引用。
第十六行:清除card tables 中的dirty card的耗时。
第十七行:其它GC活动耗时。
第十八行:选择要进行回收的分区放入CSet(G1选择的标准是垃圾最多的分区优先,也就是存活对象率最低的分区优先)
第十九行:处理各种引用——soft、weak、final、phantom、JNI等。
第二十行:遍历所有的引用,将不能回收的放入pending列表。
第二十一行:在回收过程中被修改的card将会被重置为dirty。
第二十二行:JDK8特性,巨型对象可以在新生代收集的时候被回收,可以通过G1ReclaimDeadHumongousObjectsAtYoungGC进行配置,默认为true。
第二十三行:释放CSet,将要释放的分区还回到free列表。
第二十四行:年轻代回收状态,Eden区满,执行回收,回收后占用为0,且Eden区大小重新调整(G1根据预测算法动态调整);Survivors变小说明有提升;Heap收集前内存占用及最大值,GC收集后内存占用及最大值。最大值由Xmx配置,保持不变。
第二十五行:user:垃圾收集线程在新生代垃圾收集过程中消耗的CPU时间,这个时间跟垃圾收集线程的个数有关,可能会比real time大很多;sys:内核态线程消耗的CPU时间;real:本次垃圾收集真正消耗的时间。
四、分析工具
1、个人推荐gcviewer,图形化展示各个收集指标,另附Summary、Memory及Pause等明细统计,可以查看gc次数,总的GC耗时,最大、最小耗时、吞吐量等等:
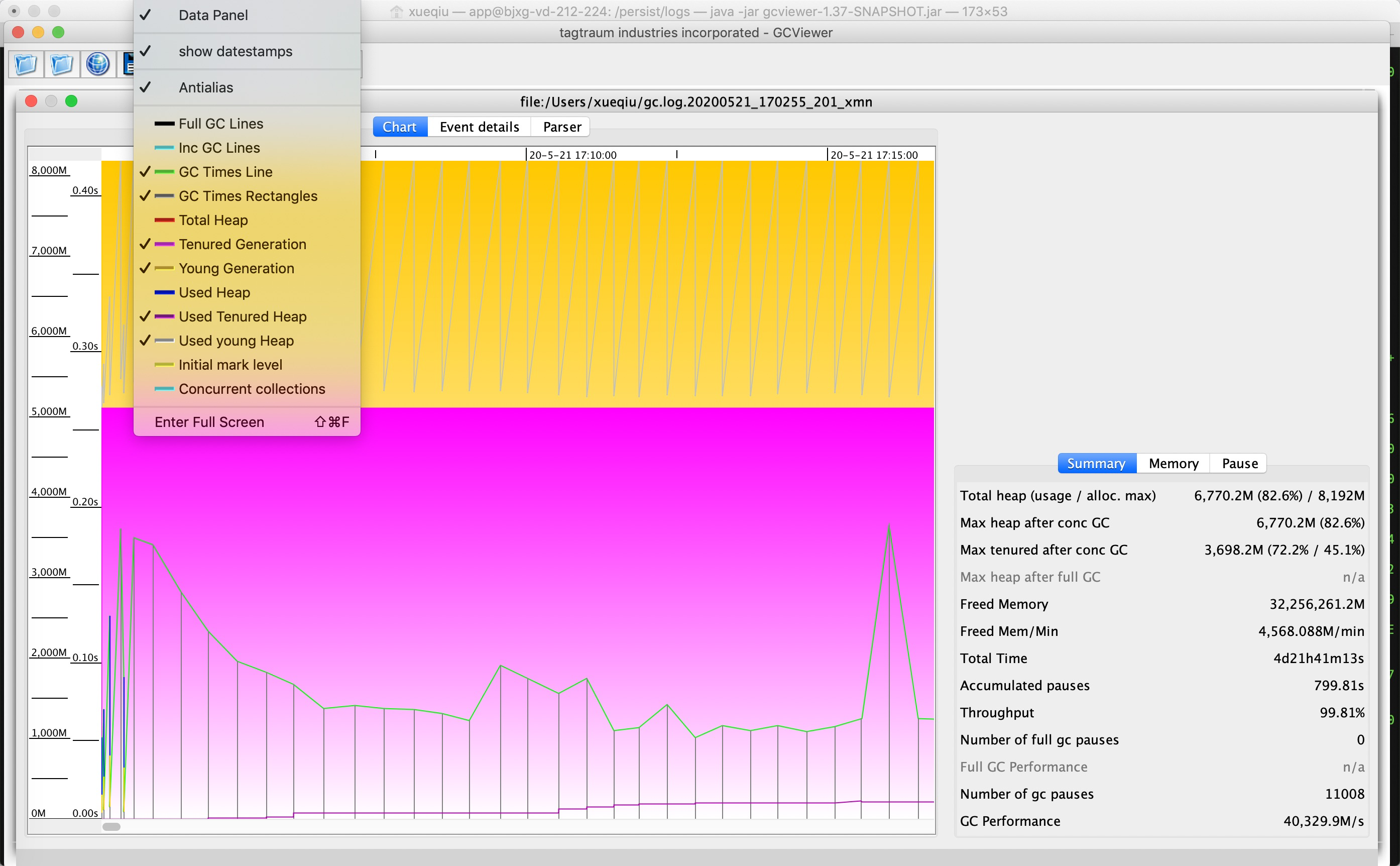
2、在线工具:https://gceasy.io/,可以上传GC日志生成GC报告,下图为报告中的关于GC耗时分布统计:
