0x01 环境说明
1.1 本地
OS: windows 10
JDK: jdk1.8.0_121
Scala: scala-2.11.11
IDE: IntelliJ IDEA ULTIMATE 2017.2.1
1.2 服务器
OS: CentOS_6.5_x64
JDK: jdk1.8.111
Hadoop: hadoop-2.6.5
Spark: spark-1.6.3-bin-hadoop2.6
Scala: scala-2.11.11
0x02 windows端配置
2.1 安装JDK
配置环境变量
JAVA_HOME
CLASSPATH
Path
2.2 配置hosts
文件位置
C:WindowsSystem32driversetc
新增如下内容(和集群的hosts文件内容一样,根据自己集群的实际情况修改)
192.168.1.10 master
192.168.1.11 slave1
192.168.1.12 slave2
2.3 安装IntelliJ IDEA
- 注意插件安装
Maven
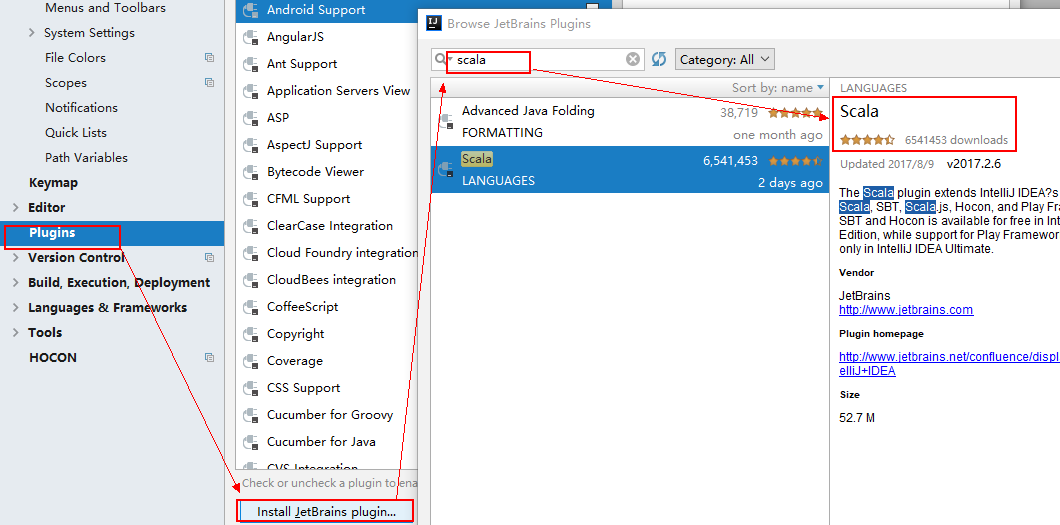
2.4 IDEA中安装scala插件
0x03 服务器端配置
3.1 安装JDK
3.2 安装Hadoop
3.3 安装Spark
0x04 测试
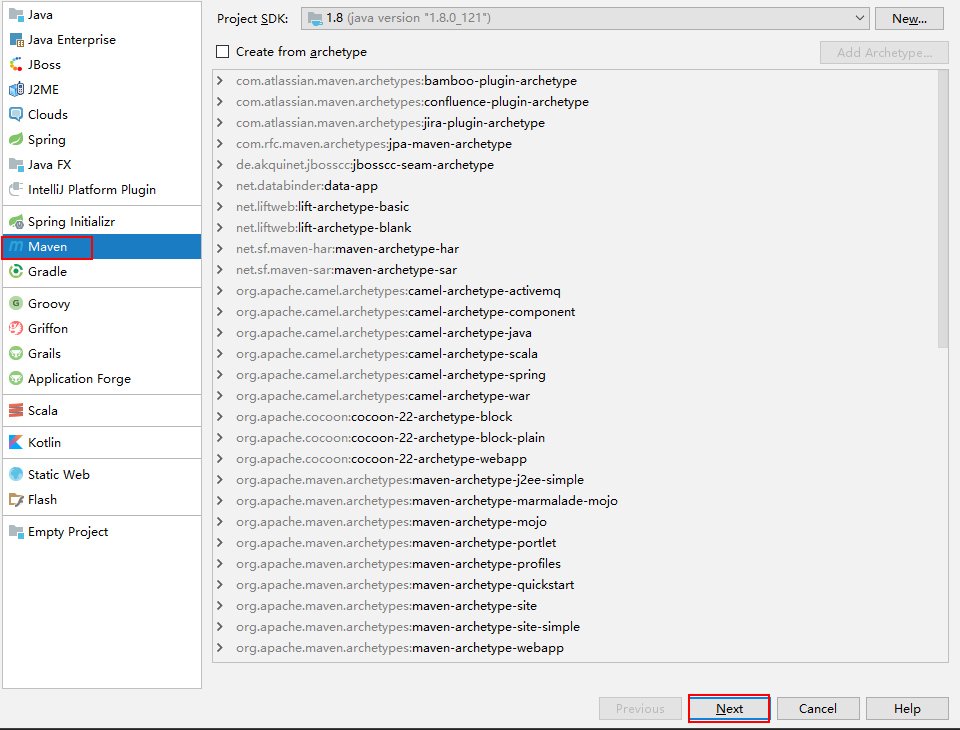
4.1 新建maven项目
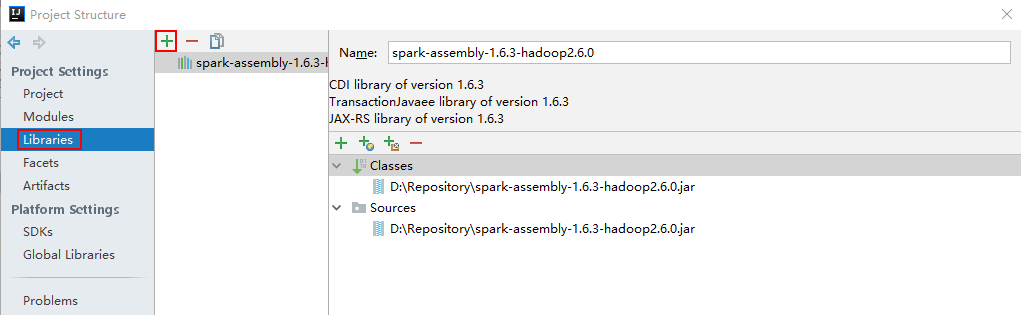
4.2 添加依赖包
File -> Project Structure -> Libraries添加spark-assembly-1.6.3-hadoop2.6.0.jar(位置在服务器端spark/lib/下)
4.3 新建ConnectionUtil类
在srcmainjava目录下新建java类ConnectionUtil
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class ConnectionUtil {
public static final String master = "spark://master:7077";
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("demo").setMaster(master);
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
System.out.println(javaSparkContext);
javaSparkContext.stop();
}
}
4.4 编译运行

如果出现上图结果则证明,运行正确。
4.5 运行JavaWordCount
- 数据准备,随便准备一个文档格式不限,上传到
hdfs上。
$ vim wordcount.txt
hello Tom
hello Jack
hello Ning
# 上传文件
$ hadoop fs -put wordcount.txt /user/hadoop/
# 查看文件是否上传成功
$ hadoop fs -ls /user/hadoop/
- 代码(
spark安装包中的example,指定了jar包和输入文件的路径)
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
// if (args.length < 1) {
// System.err.println("Usage: JavaWordCount <file>");
// System.exit(1);
// }
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount")
.setMaster("spark://master:7077")
.set("spark.executor.memory", "512M");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
ctx.addJar("D:\workspace\spark\JavaWordCount.jar");
String path = "hdfs://master:9000/user/hadoop/wordcount.txt";
JavaRDD<String> lines = ctx.textFile(path);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(SPACE.split(s));
}
});
JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
}
- 打包非常重要,否则运行会出现各种错误,甚至无法运行
在File -> Project Structure ->Artifacts点击绿色“+”,Add-->JAR-->From Modules with Dependencies

输入main class入口函数名,将Output Layout下所有jar包删掉(因为spark运行环境已经包含了这些包),如果已经存在META-INF要先将这个文件夹删除。然后Apply,OK
编译程序:Build-->Build Artifacts...,然后选择要编译的项目进行编译
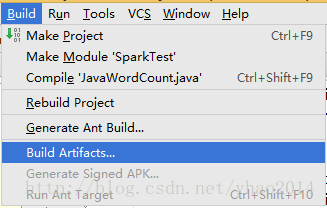
在当前工程生成的out目录下就可以找到输出的jar包,放到程序中指定的位置(就是addJar()方法中所设置的路径)

- 运行程序,结果如下

0x05 出现的问题
5.1 无法访问scala.Cloneable
java: 无法访问scala.Cloneable找不到scala.Cloneable的类文件
原因:原来使用的是spark-2.1.0-bin-hadoop2.4没有spark-assembly-1.6.3-hadoop2.6.0.jar依赖包所致。
解决:因为原来是用的hadoop版本为2.5.2相应的依赖包官网已经不再支持,所以更新的平台的hadoop环境为2.6.5,spark 2.X相应的文档很少,更改版本为1.6.3。
Create: 2017-08-12 10:33:55 星期六
Update1: 2017-08-14 20:10:47 星期一