数据抓取之 hive分析
一.今日任务
根据本题给定的数据文件dat0204.log编写Hive命令建立数据表,并将dat0204.log导入所建立的数据表,然后编写Hive查询语句获取2014全年上映电影的数据记录,并将查询结果导入Hadoop平台的result目录。本题赛前抽取参数是dat0204.log文件,请参赛学生将完成本题要求的所有命令按步骤顺序以分行的形式保存于ans0204.txt中,
二.任务源码
- 创建数据库
create database test;
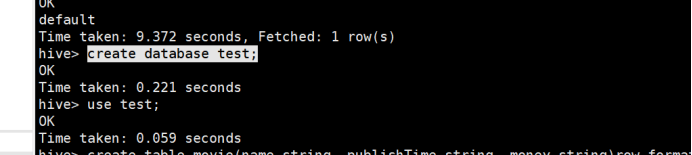
- 创建数据表
create table movie(name string, publishTime string, money string)row format delimited fields terminated by ',';
- 加载数据
load data local inpath '/home/hadoop/dat0204.log' into table movie;

- 查询数据
create table result as select * from movie where publishTime between "2014.1.1" and "2014.12.31";
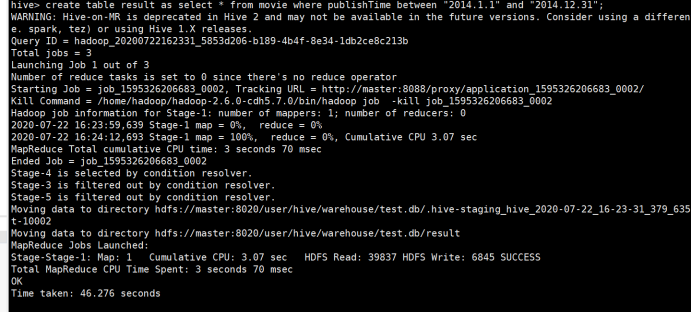
- 复制文件
hadoop fs -cp /user/hive/warehouse/test.db/result /result

三.遇到问题
Hive安装之后输入命令出现 Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStor
四.解决方案
根据百度搜索可能为以下几种情况
- hive-site.xml 链接出错
- 元数据未初始化
- Hive版本问题
经过排查,hive-site.xml文件配置没问题,但是mysql中hive数据库未赋予权限,然后刷新权限,初始化元数据就解决了
Mysql元数据库初始化命令 schematool -dbType mysql -initSchema