一、FileInputStream
1、FileInputStream 类概述
java.io.FileInputStream 类是文件输入流,从文件中读取数据,读取到内存中使用。
FileInputStream 可用于字符文件或非字符文件的输入,因为所有的文件都是由字节组成的。
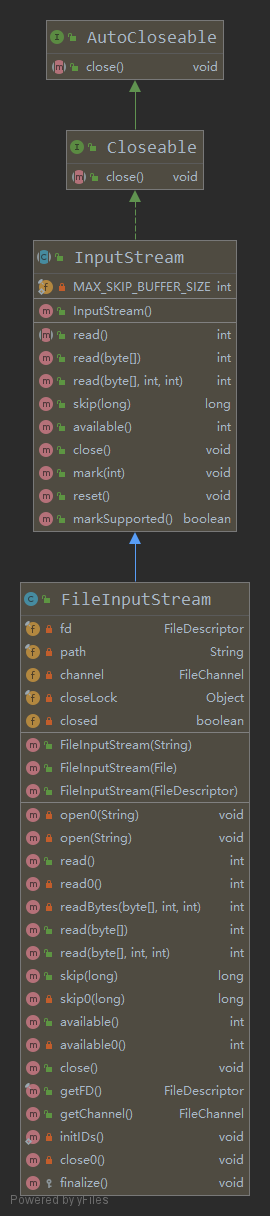
2、FileInputStream 类继承结构
3、构造方法
FileInputStream(File file) : 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
FileInputStream(String name) : 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
参数:读取文件的数据源
String name:文件的路径
File file:文件对象
构造方法的作用:
① 会创建一个FileInputStream对象
② 会把FileInputStream对象指定构造方法中要读取的文件
读取数据的原理(硬盘--> 内存)
java程序-->JVM-->OS-->OS读取数据的方法-->读取文件
字节输入流的使用步骤【重要】:
① 创建FileInputStream对象,构造方法中绑定要读取的数据源
② 使用FileInputStream对象中的方法read,读取文件
③ 释放资源
二、常用方法
int read()
从输入流中读取数据的下一个字节。 返回 0 到 255 范围内的 int 字节值。 如果因为已经到达流末尾而没有可用的字节, 则返回值 -1。
int read(byte[] b)
从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。 如果因为已经到达流末尾而没有可用的字节, 则返回值 -1。 否则以整数形式返回实际读取的字节数。
int read(byte[] b, int off,int len)
将输入流中最多 len 个数据字节读入 byte 数组。 尝试读取 len 个字节, 但读取的字节也可能小于该值。 以整数形式返回实际读取的字节数。 如果因为流位于文件末尾而没有可用的字节, 则返回值 -1。
public void close() throws IOException
关闭此输入流并释放与该流关联的所有系统资源。
三、案例
1、读取文件的值
代码实现:
1 @Test 2 public void testFileInputStream() { 3 FileInputStream fileInputStream = null; 4 try { 5 //1. 实例化File类的对象,指明要操作的文件 6 File file = new File("hello.txt"); 7 8 //2.提供具体的流 9 fileInputStream = new FileInputStream(file); 10 11 //3. 数据的读入 12 int data = fileInputStream.read(); 13 while (data != -1) { 14 System.out.print((char)data); 15 data= fileInputStream.read(); 16 } 17 } catch (IOException e) { 18 e.printStackTrace(); 19 } finally { 20 //4. 流的关闭操作 21 try { 22 if (fileInputStream != null) { 23 fileInputStream.close(); 24 } 25 } catch (IOException e) { 26 e.printStackTrace(); 27 } 28 } 29 }
当文件中没有中文的时候,运行结果如下:

当文件中出现中文时:
原文件:
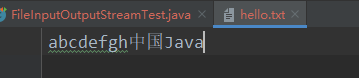
控制台输出:

这个时候竟然输出乱码了,为什么呢?(下面解释)
2、使用 read() 的重载方法读取文件
代码实现:
1 @Test
2 public void testFileInputStream1() {
3 FileInputStream fileInputStream = null;
4 try {
5 //1. 实例化File类的对象,指明要操作的文件
6 File file = new File("hello.txt");
7
8 //2.提供具体的流
9 fileInputStream = new FileInputStream(file);
10
11 //3. 数据的读入
12 byte[] buffer = new byte[5];
13 int len;//记录每次读取的字节的个数
14 while((len = fileInputStream.read(buffer)) != -1){
15 String str = new String(buffer,0,len);
16 System.out.print(str);
17
18 }
19 } catch (IOException e) {
20 e.printStackTrace();
21 } finally {
22 //4. 流的关闭操作
23 try {
24 if (fileInputStream != null) {
25 fileInputStream.close();
26 }
27 } catch (IOException e) {
28 e.printStackTrace();
29 }
30 }
31 }
当读取的文件中没有中文时,也是正常的。

可是当文件中有中文时:

这个时候又出现乱码了!!!
3、为什么会出现乱码呢?
这是因为英文和中文的字符集不同的原因。
英文情况下,无论是 ASCII编码还是 UTF-8编码,一个字母都会占一个字节。
中文情况下,使用的 UTF-8 编码,这个文字就会占用 三个字节。
(1)情况一:使用 read() 一个个读取
① 当读取英文时:
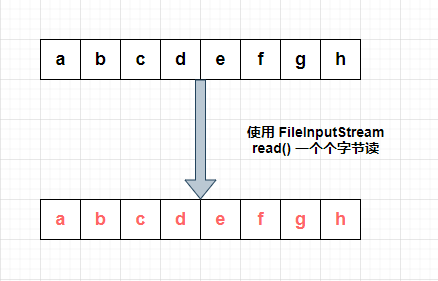
会一个个字节去读,而一个英文正好对应一个字节。
② 当包含中文时:
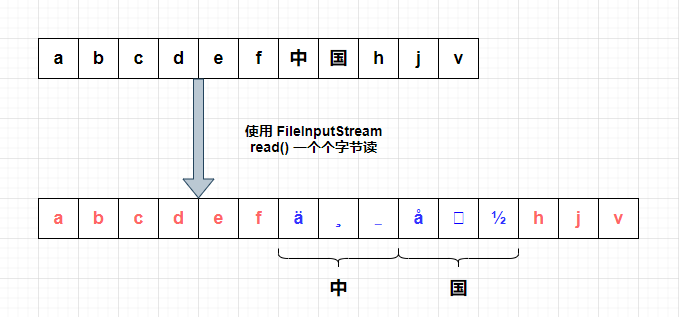
由于里面包含中文,一个中文占用三个字节,一个个字节去读取的时候,会把一个中文拆分为三个字节,依次显示出来,就呈现这样的效果。
(2)情况二:使用 read(Char[] cbuf) 读取
① 当读取英文时:
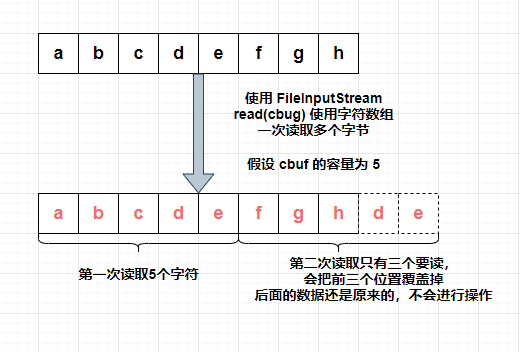
使用字节数组读取时,英文也正好可以读取显示。
② 当读取中文时:
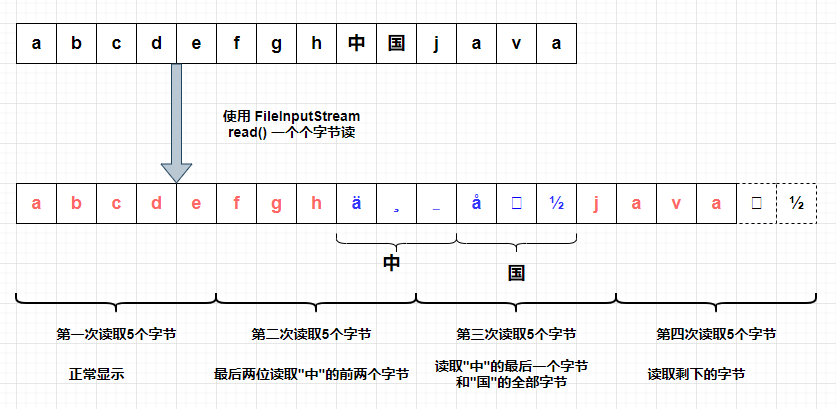
使用字节数组读取时,会把中文拆分读取,然后进行显示。
最后运行结果:

4、使用字节数组读取
read(byte[] b) ,每次读取b的长度个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回 -1 。
int read(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
明确两件事情:
a. 方法的参数byte[]的作用?
起到缓冲作用,存储每次读取到的多个字节,数组的长度一把定义为1024(1kb)或者1024的整数倍
b.方法的返回值int是什么?
每次读取的有效字节个数
Demo:
1 public static void main(String[] args) throws IOException {
2 //创建FileInputStream对象,构造方法中绑定要读取的数据源
3 FileInputStream fis = new FileInputStream("E:\b.txt");
4 //使用FileInputStream对象中的方法read读取文件
5 //int read(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
6 /*
7 发现以上读取时一个重复的过程,可以使用循环优化
8 不知道文件中有多少字节,所以使用while循环
9 while循环结束的条件,读取到-1结束
10 */
11 byte[] bytes = new byte[1024];//存储读取到的多个字节
12 int len = 0; //记录每次读取的有效字节个数
13 while((len = fis.read(bytes))!=-1){
14 //String(byte[] bytes, int offset, int length) 把字节数组的一部分转换为字符串 offset:数组的开始索引 length:转换的字节个数
15 System.out.println(new String(bytes,0,len));
16 }
17
18 //释放资源
19 fis.close();
20 }
Tips:使用数组读取,每次读取多个字节,减少了系统间的IO操作次数,从而提高了读写的效率,建议开发中使用。
字节流读取文件的原理:

四、复制文件
复制文件原理图解:

文件复制的步骤:
1. 创建一个字节输入流对象,构造方法中绑定要读取的数据源
2. 创建一个字节输出流对象,构造方法中绑定要写入的目的地
3. 使用字节输入流对象中的方法read读取文件
4. 使用字节输出流中的方法write,把读取到的字节写入到目的地的文件中
5. 释放资源;
代码实现:
1 public static void main(String[] args) throws IOException {
2 //1.创建一个字节输入流对象,构造方法中绑定要读取的数据源
3 FileInputStream fis = new FileInputStream("c:\1.jpg");
4 //2.创建一个字节输出流对象,构造方法中绑定要写入的目的地
5 FileOutputStream fos = new FileOutputStream("d:\1.jpg");
6 //一次读取一个字节写入一个字节的方式
7 //3.使用字节输入流对象中的方法read读取文件
8 /*int len = 0;
9 while((len = fis.read())!=-1){
10 //4.使用字节输出流中的方法write,把读取到的字节写入到目的地的文件中
11 fos.write(len);
12 }*/
13
14 //使用数组缓冲读取多个字节,写入多个字节
15 byte[] bytes = new byte[1024];
16 //3.使用字节输入流对象中的方法read读取文件
17 int len = 0;//每次读取的有效字节个数
18 while((len = fis.read(bytes))!=-1){
19 //4.使用字节输出流中的方法write,把读取到的字节写入到目的地的文件中
20 fos.write(bytes,0,len);
21 }
22
23 //5.释放资源(先关写的,后关闭读的;如果写完了,肯定读取完毕了)
24 fos.close();
25 fis.close();
26 }
注意:流的关闭原则,先开后关,后开先关。
五、注意点
1、对于文本文件(.txt,.java,.c,.cpp),使用字符流处理。
2、对于非文本文件(.jpg,.mp3,.mp4,.avi,.doc,.ppt,...),使用字节流处理。
3、使用字节流FileInputStream处理文本文件,可能出现乱码。