1:批量查询操作
1):插入测试数据
PUT /costumer/doc/1
{
"name": "zhangsan",
"age": 20
}
PUT /costumer/doc/2
{
"name": "lisi",
"age": 19
}
PUT /costumer/doc/3
{
"name": "wangwu",
"age": 18
}
Elasticsearch是分布式的,在查询的时候不可避免的要夸网络,如果大量的单独的请求,会造成很大的网络延迟和开销;
ES的查询方式:

2):批量查询
GET /_mget
{
"docs": [
{
"_index": "costumer",
"_type": "doc",
"_id": "1"
},
{
"_index": "costumer",
"_type": "doc",
"_id": "2"
}
]
}
如果索引相同的话,可以简写:
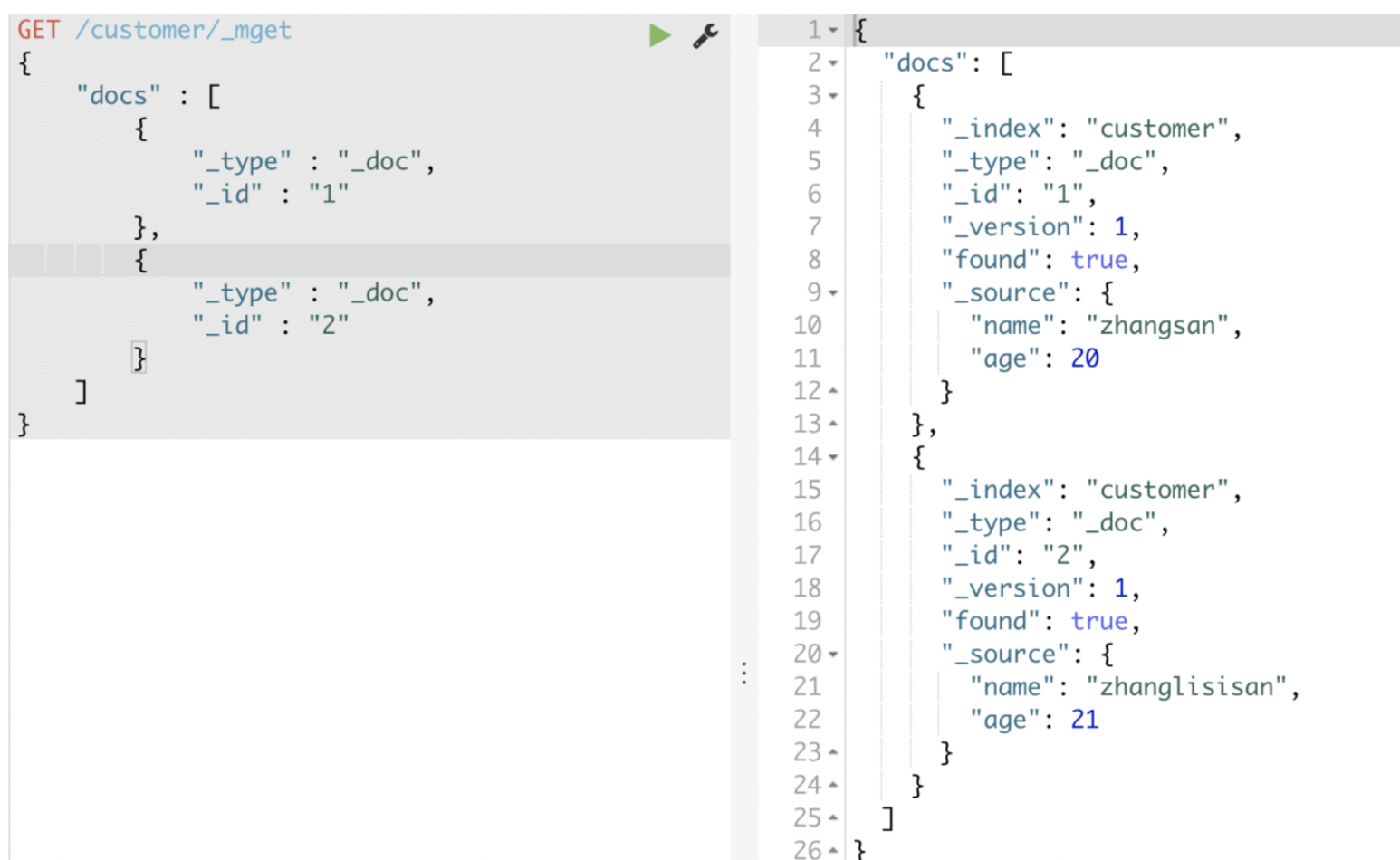
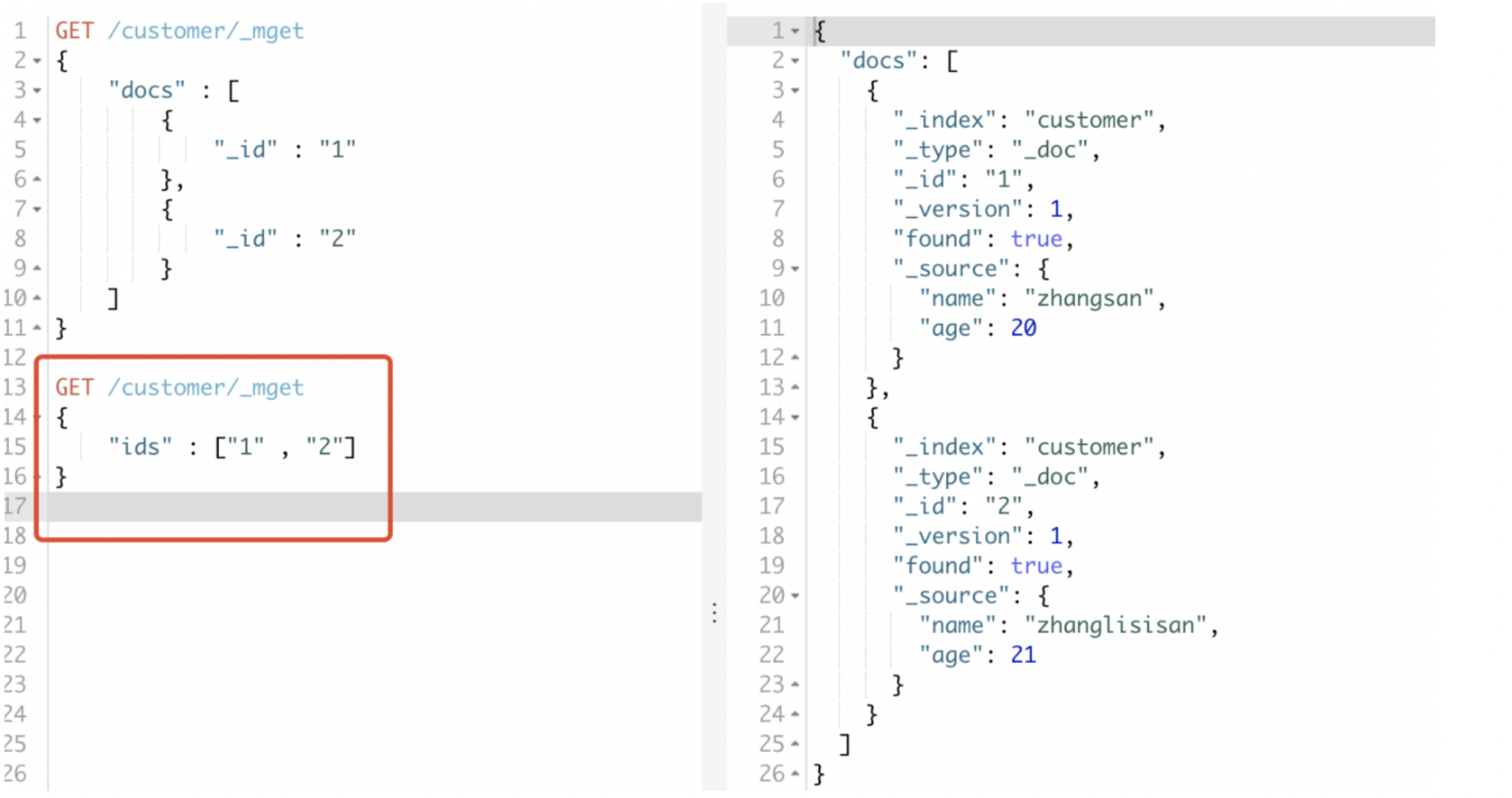
如果类型也相同的话,可以直接简写成:
2:批量执行(bulk)
与 mget 可以使我们一次取回多个文档同样的方式, bulk API 允许在单个步骤中可以进行多次 create 、 index 、 update 或 delete 请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次
【注意:】bulk操作是非原子性的,不可以用在事物上
语法:bulk 与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}
{ request body }
action/metadata 行指定 哪一个文档 做 什么操作 。
action 必须是以下选项之一:
| create | 如果文档不存在,那么就创建它。 |
|---|---|
| index | 创建一个新文档或者替换一个现有的文档。 |
| update | 部分更新一个文档 |
| delete | 删除一个文档 |
例如,为了把所有的操作组合在一起,一个完整的 bulk 请求 有以下形式:
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }
【注意】:
1、请注意 delete 动作不能有请求体,它后面跟着的是另外一个操作
2、谨记最后一个换行符不要落下。
3、每个子请求都是独立执行,因此某个子请求的失败不会对其他子请求的成功与否造成影响。
整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。 批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。 但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
幸运的是,很容易找到这个 最佳点 :通过批量索引典型文档,并不断增加批量大小进行尝试。 当性能开始下降,那么你的批量大小就太大了。一个好的办法是开始时将 1,000 到 5,000 个文档作为一个批次, 如果你的文档非常大,那么就减少批量的文档个数。
密切关注你的批量请求的物理大小往往非常有用,一千个 1KB 的文档是完全不同于一千个 1MB 文档所占的物理大小。 一个好的批量大小在开始处理后所占用的物理大小约为 **5-15 MB. es的内存分配是32G