算法君:小白同学,给你出道算法题,看你小子算法能力有没有长进。
算法小白:最近一直在研究算法,刷了很多算法题,正好活动活动大脑,来来来,赶快出题!
算法君:听好了,题目是:求一个字符串中最长的回文字符串。
算法小白:这个算法好像很简单,就是有一个概念不太明白,啥叫“回文字符串”。
算法君:哈哈,你说的很简单,一定是题目的字数很少的意思。
算法小白:哦,又被老大猜中了。还是先给我讲一下什么是回文字符串吧!
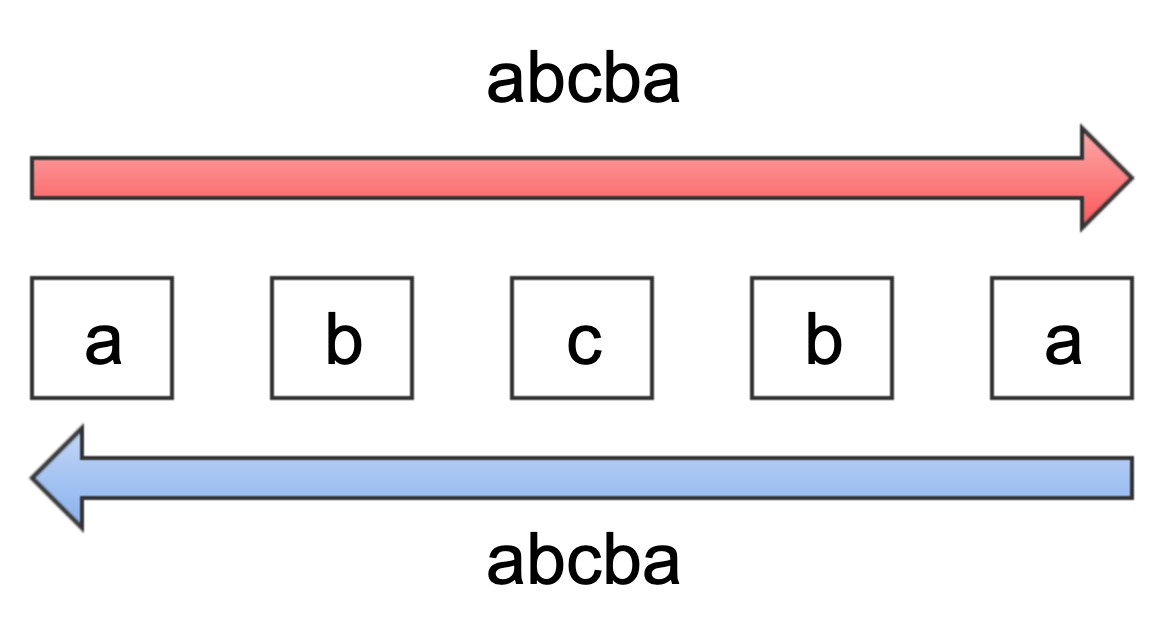
算法君:回文字符串吗!首先是一个字符串(废话),然后,核心就是回文。“回”吗,就是来来回回的意思。其实就是正向和反向遍历字符串中的每一个字符,然后嘛,如果遍历的结果都一样,就是回文字符串。例如,有一个字符串abcba,无论正向遍历,还是反向遍历,结果都是abcba,如果还不清楚,可以看下图。
算法小白:太好了,我终于知道什么叫回文字符串了,现在可以做这道题了。只要正向和反向分别遍历一遍字符串,然后比较一下结果,如果两次遍历的结果相同,就是回文字符串,哈哈哈,对吗?老大。
算法君:着什么急,你看清题目了吗?不是让你判断是否为回文字符串,是要在一个字符串中寻找最长回文字符串,例如,akbubk是一个字符串,这里边有很多回文字符串,其实单个字母就是一个回文字符串,还有就是bub、kbubk,很显然,最长的回文字符串就是kbubk。
算法小白:懂了,懂了,题目还要一个条件,就是要找到所有回文字符串中最长的一个。
算法君:真懂了吗? 好吧,说说你怎么设计这个算法。
算法小白:我只用了0.01秒,就想到如何设计了,当然是得到字符串中的所有子串,然后找到所有的回文字符串,最后,当然是对这些回文字符串按长度排序,并找到最大的回文字符串了。哈哈哈,我聪明吗!!!
算法君:Are you crazy?(此时的算法君内心一定是有一万匹草泥马跑过,气得都飙英文了),这么做当然没错,但.....,效率太低了。这要是字符串长点,是要去租用超级计算机运行算法程序吗?
算法小白:不好意思啊,我只想到了这种算法,反正能实现就行呗,管它效率怎样呢!
算法君:设计算法可不光是实现就行,要注重效率、效率、还是效率,重要的事情说三遍。这才能真正体现出算法之美,否则,直接用最笨的方法谁都会。
算法小白:那么老大有什么更好的实现吗?
算法君:当然,我作为老大,自然是肚子里有货了,先给你讲一种效率较高的算法。
算法君:要优化一个算法,首先要知道原来的算法哪里效率低了。就拿前面给出的字符串akbubk来说。u、bub和kbubk都是回文字符串,我们前面说了,判断回文字符串就是要分别正向和反向遍历一遍字符串,然后比较遍历结果,如果结果相同,就是回文字符串。对于单个字符,直接就是回文字符串,对于bub来说,按常规的判断方法,需要正向循环3次(得到正向字符串),反向循环3次(得到反向字符串)。一共6次才能判断该字符串是否为回文字符串(不过正向可以省略了,因为就用字符串本身就可以了),而对于kbubk来说,需要遍历10次才可以。
算法君:这是按常规的做法。但是,我们仔细观察,bub和u的关系,u是包含在bub中的,而且u肯定是回文字符串,所以以u为轴,只要判断该字符串的首字符与尾字符是否相等即可。也就是说,这样一来,就只需要比较一次(首字符和尾字符进行比较)就可以了,效率大大提升。
算法小白:好像是有点明白了。
算法君:别急别急,我还没说完呢!如果感觉bub和u的关系太简单,可以再看一下bub和kbubk的关系。bub是包含在kbubk中的,如果按常规的做法,bub正反遍历两次判断是否为回文字符串,而kbubk同样需要遍历两次,但对于kbubk来说,遍历的这两次,是包含bub的两次遍历的,也就是说,这里重复遍历了。这就是我们应该优化的地方:避免重复遍历字符串。
算法小白:真是醍醐灌顶啊,那么如何避免重复遍历字符串呢?
算法君:当然是保存历史了,我们是怎么知道秦皇汉武、唐宗宋祖的,不就是通过历史书吗?咱们又没见过这几位老哥,对不!
算法小白:保存历史?让我来猜一猜,是不是将已经确认的回文字符串保存起来呢,如果下次再遇到这些已经确认的回文字符串,就不需要再进行遍历了,直接取结果就行了!
算法君:算你小子聪明一回,没错,是要将已经确认的回文字符串保存起来,但并不是保存回文字符串本身。而是要保存字符串是否为回文的结果。还拿kbubk为例,我们可以将kbubk看成3部分,首字符k是一部分,尾字符k是一部分,中间的子字符串bub是一部分,如下图所示。

算法君:对于这个特例来说,bub是回文字符串。而寻找akbubk中最长回文字符串的过程中,肯定是从长度为1的子字符串开始搜索,然后是长度为2的字符串,以此类推,所以bub一定比kbubk先搜索到,所以需要将bub是回文字符串的结果保存起来,如果要判断kbubk是否为回文字符串,只需要经过如下2步就可以了:
1. 判断首尾两个字符是否相同
2. 判断夹在首尾字符中间的子字符串是否为回文字符串
算法君:如果这两步的结果都是yes,那么这个字符串就是回文字符串,将该模型泛化,如下图所示。

算法小白:这下彻底明白了,不过应该如何保存历史呢?设计算法和实现算法还是有一定差别的,这就是理论派和实践派的差距,中间差了一个特斯拉的距离。
算法君:哈哈,理论与实践是有差别的,但好像也没那么大。其实理论与实践很多时候是相辅相成的。
算法小白:快快,给我讲讲到底如何保存历史,给我一架从理论到实践的梯子吧!
算法君:梯子!没有,我这有一壶凉水,浇下去就灌顶了!
算法小白:别逗了,赶快说说!
算法君:要想确定如何保存历史记录,首先要确定如何获取这些数据,然后再根据获取的方式确定具体的数据结构。我们期望知道字符串中任意的子串是否是回文字符串,这个子串的第一个字符在原字符串中的索引是i,最后一个字符在原字符串中的索引是j。所以我们期望有一个函数is_palindrome_string,通过将i和j作为参数传入该函数,如果i和j确定的字符串是回文,返回true,否则返回false。
算法小白:老大的意思是说将i和j作为查询历史记录的key吗?
算法君:没错,这次终于说对了一回。下面就看is_palindrome_string函数如何实现了!
算法小白:我想想啊,那么如何实现这个is_palindrome_string函数呢?通过key搜索是否为回文的历史记录,也就是搜索value,在Python中字典可以实现这个功能。用字典可以吗?
算法君:字典算是一种实现,你想想用字典具体应该如何实现呢?
算法小白:这个我知道,Python我已经很熟悉了。可以将i和j作为一个列表,然后作为字典的key,不不不,该用元组,Python中是不支持将列表作为字典的key的。
例如:history_record = {(1,1):True, (1,3):False}
算法小白:然后通过元组(i,j)查询历史,例如,要想知道索引从1到3的子串是否为回文字符串,只需要搜索history_record即可,代码如下:
history_record[(1,3)]
算法君:没错,这算是一种存储历史的方法,不过搜索字典仍然需要时间,尽管时间不是线性的。想想还有没有更快的定位历史记录的方法呢?
算法小白:快速定位?..... 这个,比字典还快,难道是用魔法吗? 哈哈哈!这个还真一时想不出。
算法君:其实在数据结构中,已经清楚地阐述了最快定位的数据结构,这就是数组,由于数组是在内存中的一块连续空间,所以可以根据偏移量瞬间定位到特定的位置。
算法小白:嗯,数组我当然知道,不过如何用数组来保存回文字符串的历史呢?
算法君:前面提到的is_palindrome_string函数有两个参数i和j。i和j是字符串中某一个字符的索引,从0开始,取值范围都是0 <= i,j < n(这里假设字符串的长度是n),其实这也符合二维数组的索引取值规则。假设有一个n*n的正方形二维数组P(每个元素初始值都是0)。如果从i到j的字符串是回文字符串,那么就将P[i,j]设为1,如果要知道从i到j的字符串是否为回文字符串,也只需要查询P[i,j]即可。
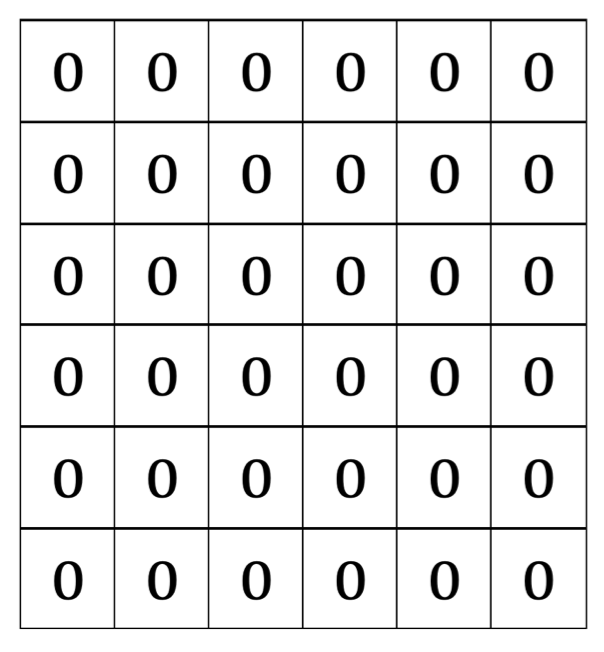
算法君:举个具体的例子,有一个字符串acxxcd,要求该字符串的最大回文字符串,可以创建如下图的6*6的二维数组,初始化为0。
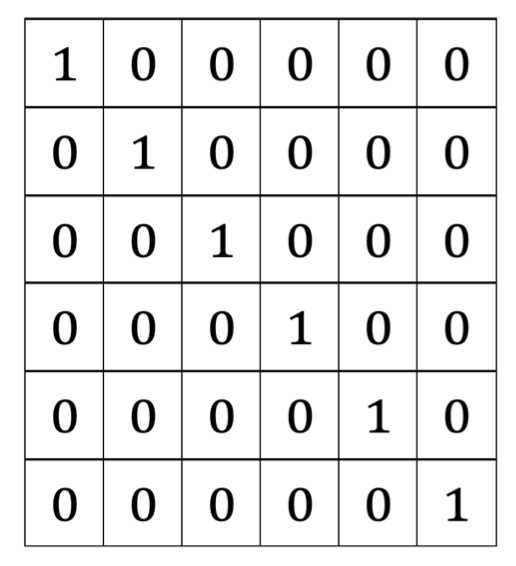
然后将长度为1的字符串标记为回文字符串(主对角线上),如P[0,0],P[1,1]等。
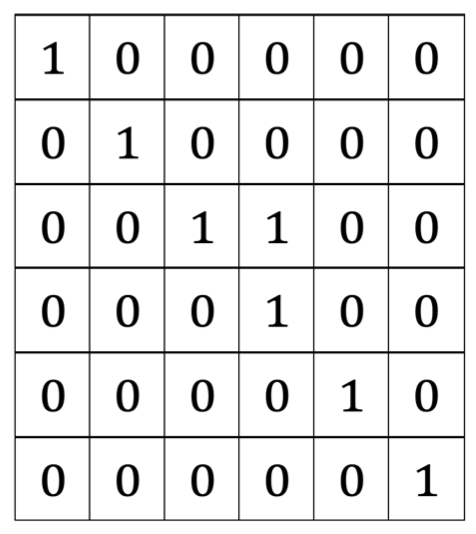
接下来将长度为2 的字符串是回文的做一下标记,也就是两个字符相等的字符串,这里只有一个,那就是xx,也就是P[2,3]。如下图所示。
在字符串acxxcd中,并没有长度为3的回文字符串,所以直接搜索长度为4的回文字符串,如果搜索长度为4的字符串,按着前面的描述,先要判断首尾字符是否相等,如果相等,再判断夹在中间的字符串是否为回文字符串,夹在中间的字符串的长度肯定是2,所以可以直接在这个二维数组上定位。例如,搜索到cxxc,首尾字符都是c,中间的xx在二维数组中的坐标是P[2,3],这个位置刚刚在前面设置为1,所以xx是回文字符串,从而判定cxxc是回文字符串。而cxxc在整个字符串中首尾字符的位置是(1,4),所以需要将P[1,4]设置为1,如下图所示。
继续扫描长度为5的回文字符串(不存在),然后是长度为6的回文字符串(不存在),所以这个唯一的长度为4的回文字符串就是acxxcd的最长回文字符串。
算法君:这种算法还有一个名字:动态规划法
算法小白:哈哈,还可以这么做。又学了一招!!老大就是老大!
算法君:不过这种存储方案也有缺点,就是比较浪费内存空间,因为需要额外申请n*n的数组空间。另外,你能说出这个算法的时间复杂度和空间复杂度吗?
算法小白:复杂度?我想想,所谓复杂度就是值随着算法输入数据的多少,时间和空间的变化关系吧。如是线性变化的,那么时间复杂度就是O(n)。
算法君:是的,可以这么理解。那么这个算法的复杂度是多少呢?
算法小白:由于该算法需要申请n*n的数组,所以空间复杂度应该是O(n^2),对于每一个字符串,都需要从长度为1的回文字符串开始搜索,需要双重循环,所以时间复杂度也是O(n^2)。
算法君:嗯,这回说得没错,那么还有什么更好的算法可以降低空间复杂度吗?例如,将空间复杂度降为O(1),也就是不需要申请额外的内存空间。
算法小白:我现在已经用脑过度了,这个要回去好好考虑下。感谢老大耐心讲解。
算法君:好吧,回去多想想还有没有更好的算法。下面给出一个具体的算法实现(Python语言)。
#动态规划法求最长回文字符串的完整代码 class MaxPalindromeString: def __init__(self): self.start_index = None self.array_len = None def get_longest_palindrome(self,s): if s == None: return size = len(s) if size < 1: return self.start_index = 0 self.array_len = 1 # 用于保存历史记录(size * size) history_record = [([0] * size) for i in range(size)] # 初始化长度为1的回文字符串信息 i= 0 while i< size: history_record[i][i] = 1 i += 1 # 初始化长度为2的回文字符串信息 i = 0 while i < size - 1: if s[i] == s[i+1]: history_record[i][i+1] = 1 self.start_index = i self.array_len = 2 i += 1 # 查找从长度为3开始的回文字符串 p_len = 3 while p_len <= size: i = 0 while i < size-p_len + 1: j = i + p_len-1 if s[i] == s[j] and history_record[i+1][j-1] == 1: history_record[i][j] = 1 self.start_index = i self.array_len = p_len i += 1 p_len += 1 s = 'abcdefgfedxyz' s1 = 'akbubk' p = MaxPalindromeString() p.get_longest_palindrome(s1) if p.start_index != -1 and p.array_len != -1: print('最长回文字符串:',s1[p.start_index:p.start_index + p.array_len]) else: print('查找失败')
算法君:如果想知道这些算法的具体实现细节,可以扫描下面的二维码,并关注“极客起源”公众号,然后输入229893,即可获得相关资源。除此之外,还有更多精彩内容等着你哦!
