随机森林=随机+森林
森林顾名思义就是很多棵树用来做分类问题,在之前的博客中已经介绍了决策树的构建过程,森林则是这很多棵树的一个集合,主要思路是,每一颗树都有一个投票,考虑这些所有树的投票,选择票数最多的结果作为最终的结果
随机就是有很多偶然性,这里的随机包括训练每棵树的数据集是随机的(数据集采用的方法是oob方法),每棵树的维度是随机的。
oob(out of bag)方法
如下图中,g1,g2,...,gT,分别表示T个假设,(xi,yi)表示的是数据集,通过下图可以看到,g1的训练过程用到的数据集是随机挑选的部分数据(x1,y1),(xn,yn),不包括(x2,y2),(x3,y3)等,同理g2也随机挑选数据集,包括的数据集可以通过下表看出,这样的方法用到决策树的构建,构建的最终的森林就具有随性性,

在机器学习中,一个最重要的方法是验证,验证选择的假设正确性,通过oob方法,选中的数据构成了训练集,没有选中的那些构成了验证集,对于任何一个数据在N次之后都没有被选中的概率课通过下边计算,可知大概有1/e的数据在整个过程中都没有被选到。
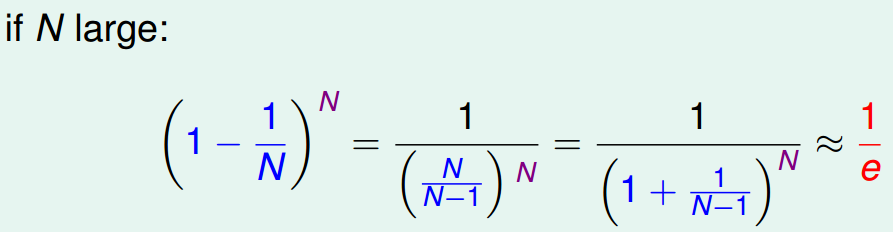
![]() 随机性除了数据选择的随机性还包括选择维度也是随机的,如果一个数据包括的维度是d,则每次构建决策树是都从中选择d`<d个维度这样每棵树选择的维度都是不一样的,
随机性除了数据选择的随机性还包括选择维度也是随机的,如果一个数据包括的维度是d,则每次构建决策树是都从中选择d`<d个维度这样每棵树选择的维度都是不一样的,
随机森林判断过程的图如下所示

对于每一个训练集Di,都会产生很多个很多个假设,利用验证机,验证每一个假设,然后选择最好的那一个,M个训练集就会产生M个最好的假设,然后通过恰当的组合方式,吧这些最好的假设组合起来,得到最终的结果。
特征选择
随机森林除了可以用于分类问题,还可以用于特征选择,
特征选择的意思,就是我们把多余的无用的特征去掉。比如我们预测一个人的信用状况,那貌似和她的身份证号没什么关系,因此可以去掉。进行特征选择有很多优点,首先降低了维度计算变得简单,其次特征维度降低之后有助于避免过拟合。缺点也是有的,比如如果维度删除的不正确反倒容易造成过拟合。
一种就是例如线性模型这样给每个维度计算一个权值,然后根据权值的绝对值大小进行排序,越高的说明这个属性越重要,当然也可以加入正则化项,这样有的不重要的属性的权重值就会降低。再有一种就是用随机森林的方法了。
如果一个属性它是重要的,那么我们往这个属性中添加一些noise,整个分类器的性能就会降低。
![]()
那么怎么向第i个属性中添加noise,一种方法就是我们把整个数据中第i个属性的属性值全部打乱然后重新分配,这种方法叫做 permutation
那么我们可以把这种方法应用到随机森林上。为什么要用随机森林呢,是因为随机森林有一个oob这样一种验证方法。不用再找新的验证集了
![]()
这里我们没有在扰乱i属性之后重新训练一个树来测试,而是在数据集上做了手脚。

![]()
我们在用(xn,yn)验证的时候,对于里面的每个树,我们总会应用到这个数据的i属性,那么在这个时候,我们把这个属性值替换就好了。替换成什么呢,我们这里只在对于oob那些数据的i属性值当中选择。
随机森林参考内容http://blog.csdn.net/sjkldjflakj/article/details/52016235