基于邻域的协同过滤主要分为两类,基于用户的协同过滤和基于物品的协同过滤。前者给用户推荐和他兴趣相似的其他用户喜欢的物品,后者则是推荐和他之前喜欢过的物品相似的物品。
基于用户的协同过滤算法
这里介绍基于用户的协同过滤,从定义来说,可以分为以下两步进行:
- 找到和目标用户兴趣相似的用户集合
- 找和这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户
计算用户相似度的基本算法:
(1)Jaccard 公式
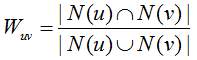
(2)余弦相似度:

得到用户之间的兴趣相似度后,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品,下面的公式表示用户u对物品i的感兴趣程度:
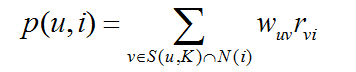
其中S(u,K)包含和用户u兴趣最相近的K个用户,N(i)是对物品i有过行为的用户集合,wuv是用户u和用户v的兴趣相似度,rvi代表用户v对物品i的兴趣,在这种情况下rvi=1
可以建立物品到用户的倒查表,对每个物品都保存对该物品产生过行为的用户列表,

可以给上图中的A推荐,选取K=3,用户A对物品c,e没有过行为,因此可以把这两个物品推荐给用户A,用户A对物品c,e的兴趣是:

改进:
上边的算法是有问题的,比如两个人都买过《新华字典》这本书,但这丝毫不能说明他们两个兴趣相似,因为大多数人都买过这本书,如果两个用户都买过《数据挖掘导论》,那可以认为两个人的兴趣比较相似,因为只要研究数据挖掘的人才会买这本书。即两个人对冷门物品采取过同样的行为更能说明他们兴趣的相似性,因此相似性度量函数为:

基于物品的协同过滤算法
下面介绍基于物品的协同过滤算法,其过程主要分为2步:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
计算物品的相似度:


N(i):喜欢物品i的用户数 |N(i)∩N(j)|:同时喜欢物品i和物品j的用户数
与UserCF算法类似,用ItenCF算法计算物品相似度时,也可以首先建立用户-物品倒排表(即对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将物品列表中的物品两两在共现矩阵C中加1,最终将这些矩阵相加得到上边的C矩阵,其中C[i][j]记录同时喜欢物品i和物品j的用户数,最后将c矩阵归一化得到物品之间的余弦相似度矩阵W。

得到物品的相似度之后,ItemCF通过如下公式计算用户u对一个物品j的兴趣:

N(u)是用户喜欢的物品的集合,S(i,k)是和物品i最相似的k个物品的集合,wji 是物品j和i的相似度,rui是用户u对物品i的兴趣。对于隐反馈数据集,如果用户u对物品i有过行为,即可令rui=1,该公式的含义是,和用户历史上感兴趣的物品越相似,越有可能在用户的推荐列表中获得比较高的排名。
用户活跃度对用户的影响
除了上面的分析权重的过程,还可以考虑用户活跃度对物品相似度的影响IUF,即活跃用户对物品相似度的贡献应该小于不活跃的用户,因袭增加IUF参数来修正物品相似度的计算公式

物品相似度归一化
如果已经得到了物品的相似性矩阵w,则可以得到归一化之后的相似度矩阵w'

归一化之后的好处是不仅仅增加推荐的准确度,还提高了覆盖率和多样性。
实现算法:
import math import time import pandas as pd def calcuteSimilar(series1,series2): ''' 计算余弦相似度 :param data1: 数据集1 Series :param data2: 数据集2 Series :return: 相似度 ''' unionLen = len(set(series1) & set(series2)) if unionLen == 0: return 0.0 product = len(series1) * len(series2) similarity = unionLen / math.sqrt(product) return similarity def calcuteUser(csvpath,targetID=1,TopN=10): ''' 计算targetID的用户与其他用户的相似度 :return:相似度TopN Series ''' frame = pd.read_csv(csvpath) #读取数据 targetUser = frame[frame['UserID'] == targetID]['MovieID'] #目标用户数据 otherUsersID = [i for i in set(frame['UserID']) if i != targetID] #其他用户ID otherUsers = [frame[frame['UserID'] == i]['MovieID'] for i in otherUsersID] #其他用户数据 similarlist = [calcuteSimilar(targetUser,user) for user in otherUsers] #计算 similarSeries = pd.Series(similarlist,index=otherUsersID) #Series return similarSeries.sort_values()[-TopN:] def calcuteInterest(frame,similarSeries,targetItemID): ''' 计算目标用户对目标物品的感兴趣程度 :param frame: 数据 :param similarSeries: 目标用户最相似的K个用户 :param targetItemID: 目标物品 :return:感兴趣程度 ''' similarUserID = similarSeries.index #和用户兴趣最相似的K个用户 similarUsers = [frame[frame['UserID'] == i] for i in similarUserID] #K个用户数据 similarUserValues = similarSeries.values #用户和其他用户的兴趣相似度 UserInstItem = [] for u in similarUsers: #其他用户对物品的感兴趣程度 if targetItemID in u['MovieID'].values: UserInstItem.append(u[u['MovieID']==targetItemID]['Rating'].values[0]) else: UserInstItem.append(0) interest = sum([similarUserValues[v]*UserInstItem[v]/5 for v in range(len(similarUserValues))]) return interest def calcuteItem(csvpath,targetUserID=1,TopN=10): ''' 计算推荐给targetUserID的用户的TopN物品 :param csvpath: 数据路径 :param targetUserID: 目标用户 :param TopN: :return: TopN个物品及感兴趣程度 ''' frame = pd.read_csv(csvpath) #读取数据 similarSeries = calcuteUser(csvpath=csvpath, targetID=targetUserID) #计算最相似K个用户 userMovieID = set(frame[frame['UserID'] == 1]['MovieID']) #目标用户感兴趣的物品 otherMovieID = set(frame[frame['UserID'] != 1]['MovieID']) #其他用户感兴趣的物品 movieID = list(userMovieID ^ otherMovieID) #差集 interestList = [calcuteInterest(frame,similarSeries,movie) for movie in movieID] #推荐 interestSeries = pd.Series(interestList, index=movieID) return interestSeries.sort_values()[-TopN:] #TopN if __name__ == '__main__': print('start..') start = time.time() a = calcuteItem('ratings.csv') print(a) print('Cost time: %f'%(time.time()-start))
参考:http://blog.csdn.net/sinat_33741547/article/details/52740010