KNN算法很简单,大致的工作原理是:给定训练数据样本和标签,对于某测试的一个样本数据,选择距离其最近的k个训练样本,这k个训练样本中所属类别最多的类即为该测试样本的预测标签。简称kNN。通常k是不大于20的整数,这里的距离一般是欧式距离。
对于上边的问题,①计算测试样本与训练样本的距离,②选择与其最近的k个样本,③排序,选择k个样本所属类别最多作为预测标签
KNN问题的python实现代码
import numpy as np import operator import matplotlib.pyplot as plt def createDataSet(): group = np.array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]]) lables=['A','A','B','B'] return group,lables def classify1(inX,dataSet,labels,k): #距离计算 dataSetSize =dataSet.shape[0]#得到数组的行数。即知道有几个训练数据 diffMat=np.tile(inX,(dataSetSize,1))-dataSet #tile:numpy中的函数。tile将原来的一个数组,扩充成了4个一样的数组。diffMat得到了目标与训练数值之间的差值。 sqDiffMat=diffMat**2 #各个元素分别平方 sqlDistances=sqDiffMat.sum(axis=1) #对应列相乘,即得到了每一个距离的平方 distances=sqlDistances**0.5 #开方,得到距离。 #[ 1.3453624 1.41421356 0.2236068 0.1 ] sortedDistIndicies=distances.argsort() #升序排列 y=array([])将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y [3 2 0 1] #选择距离最小的k个点 classCount={} for i in range(k): voteIlabel=labels[sortedDistIndicies[i]] classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #get():该方法是访问字典项的方法,即访问下标键为numOflabel的项,如果没有这一项,那么初始值为0。然后把这一项的值加1。#{'B': 2, 'A': 1} #排序 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #operator模块提供的itemgetter函数用于获取对象的哪些维的数据 #[('B', 2), ('A', 1)] """ operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为一些序号(即需要获取的数据在对象中的序号),下面看例子。 a = [1,2,3] >>> b=operator.itemgetter(1) //定义函数b,获取对象的第1个域的值 >>> b(a) 2 >>> b=operator.itemgetter(1,0) //定义函数b,获取对象的第1个域和第0个的值 >>> b(a) (2, 1) 要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。 """ return sortedClassCount[0][0]
对于上边方法的测试:
>>> group,lables=createDataSet()
>>> classify1([0,0],group,lables,3)
通过上边的结果得到了结果:B
上边全部过程是使用KNN算法的最基本的也是最核心的部分。
下边用来解决实际问题。
问题描述:



如果想要使用KNN算法,首先需要处理海伦收集到的数据,把收集到的数据转化为分类器可以接受的形式:
def file2matrix(filename): fr = open(filename) numberOfLines = len(fr.readlines()) #get the number of lines in the file returnMat = np.zeros((numberOfLines,3)) #prepare matrix to return classLabelVector = [] #prepare labels return fr = open(filename) index = 0 for line in fr.readlines(): line = line.strip() listFromLine = line.split(' ') returnMat[index,:] = listFromLine[0:3] classLabelVector.append(int(listFromLine[-1])) index += 1 return returnMat,classLabelVector
通过上边的过程已经把数据格式化为KNN分类器需要的形式,但是,自己查看数据,以一行数据为例,数据的内容是:
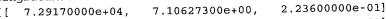
通过观察,可以得到,不同特征值的数据的数量级是不一样的,如果这个时候直接使用KNN中的计算距离的方法,则容易造成数据倾斜,因此增加了一个归一化的过程,归一化的公式为:
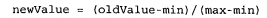
min,max分别是某一个特征的最大数值和最小数值,通过上边的过程,数据被归一化为一个0-1之间的数值,归一化的pyhton实现源码是:
#[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]数据的中有的特别大有的特别小,在之后的计算数据的时候大的数据会影响很大,因此需要归一化 def autoNorm(dataSet): minVals = dataSet.min(0) #min() 方法返回给定参数的最小值,参数可以为序列,即在这个题目中返回每列数据的最小值 maxVals = dataSet.max(0) ranges = maxVals - minVals #差值 normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals, (m,1)) normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide return normDataSet, ranges, minVals
至此,数据处理阶段已经全部完成,而接下来的工作就是使用KNN算法进行预测,并估计算法的准确度
def datingClassTest(): hoRatio = 0.10 #hold out 10% datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0]#得到数组的行数。即知道有几个训练数据 numTestVecs = int(m*hoRatio) #哪些用来当测试集哪些用来当训练集 errorCount = 0.0 for i in range(numTestVecs): classifierResult = classify1(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) #第一个参数树测试集,第二个参数是训练集,第三个参数是类标签,第四个参数是k print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])) if (classifierResult != datingLabels[i]): errorCount += 1.0 print("the total error rate is: %f" % (errorCount/float(numTestVecs))) print(errorCount)
在上边的过程中,把数据集分为训练集和测试集,验证测试集中的每一条数据的测试结果和真实结果的差别。并验证测试数据的准确度。
输入某人的信息,预测出对方的喜欢程度
#输入某人的信息,便得出对对方喜欢程度的预测值 def classifyPerson(): resultList = ['not at all', 'in small doses', 'in large doses'] percentTats = float(np.raw_input("percentage of time spent playing video games?")) ffMiles = float(np.raw_input("frequent flier miles earned per year?")) iceCream = float(np.raw_input("liters of ice cream consumed per year?")) datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') normMat, ranges, minVals = autoNorm(datingDataMat) inArr = np.array([ffMiles, percentTats, iceCream]) classifierResult = classify1((inArr - minVals)/ranges, normMat, datingLabels,3) print('You will probably like this person: ', resultList[classifierResult - 1])